compute shader 활용 예제를 base로, 이전에 tutorial에서 작성했던 것 보다 더 다양한 효과 구현에 목표를 뒀다. 먼저 particle 간의 gravity simulation을 작성한 후, particle dream 예제를 구현해보는 방향을 잡았다.
https://github.com/keechang-choi/Vulkan-Graphics-Example/pull/4
Motivation
- n body gravity simulation
- SaschaWillems/Vulkan-computenbody.cpp
- 기본 틀은 위 예제를 따라가며 작성할 계획이다. 이전 보다 조금 더 복잡한 계산이 compute shader에서 실행되는 만큼, shared memory 사용 및 compute pipeline 구성과 syncrhonization에 초점을 맞췄다.
- 아래 자료들은 모두 particle dreams 예시의 내용을 다루는데, webGL로 작성된 것들은 demo를 브라우저에서 실행해볼 수 있게 되어 있어서 실행해보며 어떤 기능들을 넣을지 구상할 수 있었다.
- animation in compute shader
- 이전 예제에서 animation 계산을 (정확히는 animation update는 cpu에서 하고, 계산된 joint matrices를 활용한 skinning계산을) vertex shader에서 실행했는데, 이번 예제 구현에서는 vertex shader 이전 단계에서 모든 animation이 완료된 animated vertices data가 SSBO형태로 필요하다.
- 이 animated vertices를 target으로 particle이 attraction 되는 효과를 만들 계획인데, 자세하게는 이 particle을 수치 적분하기 이전의 calculate compute shader에서 이 자료가 사용될 예정이다.
- 이를 위해서 비슷한 자료를 찾아보던 중 다음의 rust로 작성된 vulkan viewer 예제에서 구조를 참고했다.
- rustracer/crates/examples/gltf_viewer/shaders/AnimationCompute.comp at main · KaminariOS/rustracer (github.com)
- 이전 예제에서 animation 계산을 (정확히는 animation update는 cpu에서 하고, 계산된 joint matrices를 활용한 skinning계산을) vertex shader에서 실행했는데, 이번 예제 구현에서는 vertex shader 이전 단계에서 모든 animation이 완료된 animated vertices data가 SSBO형태로 필요하다.
Prerequisites
Numerical Integration
particle의 움직임을 나타나기 위해 처음 직관적인 접근은 뉴턴 역학을 활용하는 것이다. position을 update 하기 위해서, velocity를 사용하고, velocity를 update하기 위해서 acceleration을 사용하는 방식이다.
acceleration은 우리가 지정해준 force에 따라서 계산된다.
이전까지에는 각각이 미분-적분 관계를 가진다는 기본적인 생각으로 단순하게 시간 간격 dt만 알고 있다면, 적분을 근사해서 원하는 최종 값을 얻을 수 있겠다고 생각했다. (가속도에 dt를 곱해서 속도에 누적시키고, 속도에 dt를 곱해서 위치에 누적시키는 방식)
하지만 이 dt는 fps에 영향을 받기도 하고, 계산량이 많아진다면 간격이 커지면서 오차가 커질 수 밖에 없다. 그리고, 이 누적된 오차는 global error를 만드는데, 이 error에 따라서 원하는 simulation과 전혀 다른 simulation이 나올 수도 있다.
그래서 이 관련된 수치 적분에는 다양한 기법이 존재하는데, 처음 직관적인 방식을 Euler method라고 한다.
이 Euler method 보다 차수를 높여서, 더 적은 오차를 갖게 하는 방식도 있는데, 여기서는 더 확장된 Runge-Kutta method에 대한 내용을 알면, 나머지는 그 특수한 경우로 볼 수도 있다.
error estimation의 order이외에도, 수치 적분의 방식에따라 여러 특성을 가지는데, 아래 문서의 설명들을 보고 개념을 많이 참고 했다.
https://adamsturge.github.io/Engine-Blog/mydoc_updated_time_integrator.html
그중 symplecticity 라는 개념이 있는데, 이는 energy conservation과 관련된 개념으로, simulation의 장기적 결과에 큰 영향을 준다.
위의 각 method의 order에 대응되는 method는 다음과 같다고 볼 수 있다.
해당 내용을 좀 더 이해해보려고, 수학 공부를 조금 다시 해보기도 했는데, Textbook 하나를 잡고 진득하게 공부할 필요가 있을 것 같다. 관련 키워드는 남겨놓겠다.
- ODE(Ordinary Differential Equations). 관련 주제로 검색했을때는, Ernst Hairer 교재가 많이 나오긴 했다.
- numerical integration
- Hamiltonian mechanics
- 깊게 다루기보다는 주로 numerical integration을 적용할 할 예시들이 역학들이고, 수치 적분에서는 미분방정식을 evaluation해야하니 같이 나오는 것 같다.
- Lagrangian mechanics, calculus of variations
- symplectic integration
- flow, differential form
- differntial geoemtry관련 내용도 알면 이해하기 좋아보였다.
우선적으로 공부를 할 수는 없을 것 같고, 생각날때 조금씩 알아가야할 것 같아 symplectic function에 대한 개념까지만 공부했다. (integration method가 symplectic한 개념은 아직 자세히 보지 못했다.)
어쨌든 해당 내용을 공부하지 않더라도, 검색해서 찾은 방식들대로 integration을 구현하면, 에너지가 보존되는 효과를 누릴수 있다.
Mesh Attraction
model의 mesh attraction에도 위의 수치 적분은 동일하게 적용된다. 단지 evalation하는 과정이, n-body simulation에서는 \(O(n^2)\) 이지만, mesh attraction에서는 미지 지정한 mesh의 vertice로 attract되도록 지정해주면 된다. (나는 attraction에 공기 저항 처럼 drag에 해당하는 force를 추가해줬다.) 여기서부터는, 물리 simulation이 아니라 특수 효과를 구성한다는 생각으로, 적절한 coefficient 조절을 통해 현실성은 고려하지 않고 보이는 것에만 집중해서 구현할 계획이다.
한가지 짚고 넘어갈 점은, model의 vertices 뿐만 아니라, 그 면적 자체에도 attraction이 되도록 구현하는 점이다. 이 부분을 복잡하게 생각했었는데, 다른 구현 코드들을 보니 단순히 particle 개수를 추가해서, 남는 particle들을 mesh의 내부 분할 점으로 attract 시키는 방식을 쓰고 있어 나도 그 방식을 채택했다.
이때 쓰이는 테크닉이 삼각형 내부의 uniform한 random point를 생성하는 것인데, 아래 글을 참고해서 작성했다.
https://math.stackexchange.com/questions/18686/uniform-random-point-in-triangle-in-3d
\(\displaylines{ \begin{aligned} & r_1 \sim U(0, 1) \\ & r_2 \sim U(0, 1) \\ & w_1 = \sqrt{r_1} * (1-r_2) \\ & w_2 = \sqrt{r_1} \\ & triangle \; ABC \\ & p = A + w_1 * (B-A) + w_2 * (C-A) \end{aligned} }\)
위의 방식으로 계산된 random variable p는, 삼각형 ABC 내부의 uniform distribution을 따르게 된다.
이 좌표를 target으로, particle들이 attract되게 만들면, model의 mesh를 채우게 될 수 있을 것이다. attract되는 정도, particle의 수, 크기, 색상 등을 조정할 옵션을 만들고, mouse click 을 통한 interaction을 추가하는 것까지가 계획이다.
Plan
작업 순서
- gravity n-body simulation 구현
- integration method를 여러 방식을 option으로 선택할 수 있도록 구현 후 비교
- 구현 후, 2-body simulation의 analytic 한 solution 과 비교해서, 옳게 simulation 되는지 검증.
- 확인을 위한 particle의 trajectory rendering 기능 구현
- particle 개수를 늘려서 성능확인.
- model attraction 구현
- model SSBO 구현 후, dynamics 없이 정지된 particle 위치 확인.
- skinning in compute shader 작성
- pipeline 및 synchronization 고려
- model 선택 기능 추가.
- 이 예제를 완료 후
- PBD 방식에 대한 예제 구현.
- cloth simulation도 좋을 것 같다. animation과 상호작용할 수도 있음.
- Publications (matthias-research.github.io)
- CPU vs. GPU (naive) vs. GPU (PBD) 계산 성능 비교
- collision 관련 예제를 만들어 봐도 좋겠다는 생각이 듦.
- PBD 방식에 대한 예제 구현.
CLI11 and ImGui
구현하면서 command line argument와 ImGui을 통한 옵션 선택을 적극적으로 추가했다. 처음에 단순한 초기 설정들은 CLI11을 통해 구현했고, 이후 복잡한 선택이 필요한 값들은 ImGui widget을 추가해서 구현했다.
상수로 박아뒀던 값들 중에서 변경이 자주 필요하거나 실험이 필요한 값들 위주로 옵션으로 변경했다. 일부 변수들은 자원 생성과 관련되어서 초기화 과정이 필요한 것들이 있는데, 이런 값들은 재시작을 통해 반영되도록 따로 표시해서 재시작 버튼을 활용할 계획이다. 재시작은 가장 편한 방법이 생성한 모든 instance를 파괴하고 새로 생성하는 것이어서 재시작 loop를 추가했다.
두 방식을 모두 쓰는 값도 있어서 코드의 일관성이 조금 깨진 측면도 있지만, 앞서 밝힌대로 엄격하지 않게 해당 기능들을 필요시 편하게 사용했다.
Progress
Synchronization
https://vkguide.dev/docs/gpudriven/compute_shaders/#compute-shaders-and-barriers
이전 tutorial에서 compute shader를 다룰때는, fence를 사용해서, compute shader의 계산을 host에서 기다린 후, 다음 단계 (이미지 얻어오고 draw하는 과정)를 진행했다.
여기서는 다른 방식으로 synchronization을 구현하는데, pipeline barrier를 사용하는 방식이다. (필요한 이유는 제출된 command들이 submit order로 시작하지만 완료 순서는 모르기 때문)
pipeline barrier에 SSBO buffer memory barrier를 사용해서 execution/memory dependency를 구성해준다.
Memory Barrier
- in a queue
- 위에서 간단히 설명한 pipeline barrier
- two queue
- 이전 예제와의 차이점이 또 존재하는데, compute dedicated queue family의 사용이다.
- 이전에는 하나의 queue에서 compute와 graphics 작업을 모두 수행했다면, 이번에는 compute 목적의 queue family에서 다른 queue를 하나 더 생성했다.
- pipeline barrier에는 이를 위한 기능이 있는데,
Queue family ownership transfer개념이다.
- 기본적인 설명은 다음을 참고 했다.
- https://www.khronos.org/blog/understanding-vulkan-synchronization
- 서로 다른 두 queue family index의 queue가 하나의 자원(buffer나 image)를 공유할 때, memory access에 synchronization을 제공.
- 일반적인 pipeline barrier와의 차이점으로 src stage와 src access mask는 src queue쪽에, dst stage와 dst access mask는 dst queue쪽에 제출된다는 점이다.
- 자세한 설명은 spec 문서를 참고하면 된다.
- https://registry.khronos.org/vulkan/specs/1.3/html/vkspec.html#synchronization-queue-transfers
- 자원을 생성할 때,
VkSharingMode를VK_SHARING_MODE_EXCLUSIVE로 지정한 경우는 명시적으로 queue family 간의 ownership을 옮겨줘야 한다. - 두가지 부분 release / acquire 과정으로 구성되는데,
release- pipeline barrier가 제출하는 queue가 src queue family index에 해당한다.
- dst access mask는 무시된다. visibility operation이 실행되지 않는다.
- release operation은 availability operation이후에 실행되고, second synchronization scope의 연산들 이전에 실행된다.
acquire
- pipeline barrier가 제출하는 queue가 dst queue family index에 해당한다.
- 이전에 release한 자원의 영역과 일치해야 한다.
- src access mask가 무시된다. availability operation이 실행되지 않는다.
- acquire operation은 first synchronization scope의 연산들 이후에 실행되고, visibility operation 이전에 실행된다.
- 그리고 이 release와 acquire 연산들은 알맞은 순서에 실행되도록 app에서 semaphore등의 사용을 통해 execution dependency를 지정해야 한다고 한다.
- 우리도 semaphore를 통해 execution dependency를 주었는데, 사용될 부분을 미리 살펴보면 다음과 같다.
- [1] storage buffer 로 buffer copy 직후 graphics queue에서 release (transfer queue는 별도로 쓰지 않고 graphics queue를 사용했음)
- [2] compute command recording에서, compute queue에서 acquire
- [3] recording 끝낸 후, compute queue에서 release
- [4] draw command recording에서, graphics queue에서 acquire
- [5] recording 끝낸 후, graphics queue에서 release
- 일단 첫 release는 초기화 단계이므로 가장 먼저 실행 후 마무리 된다. (
oneTimeSubmit()을 사용했기 때문에waitIdle()과정을 통해 host에서 완료를 기다림) -
buildComputeCommandBuffers()를 먼저 호출하고 제출하게 되는데, 이때 사용하는 semaphores는 다음과 같다.- wait:
graphics.semaphores[currenrFrameIndex] - signal:
compute.semaphores[currenrFrameIndex]
- wait:
- 그 후 draw 목적의
buildCommandBuffers()를 호출하고 제출하는데, 이때 사용하는 semaphores는 다음과 같다.- wait:
compute.semaphores[currenrFrameIndex](기존 presentCompleteSemaphores도 여전히 있다.) - signal:
graphics.semaphores[currenrFrameIndex](기존 renderCompleteSemaphores도 여전히 있다.)
- wait:
- 추가되는 semaphores는 두가지 종류의 frames in flight 수 만큼이고, 이 중 graphics의 것만 signaled 상태로 생성한다.
- 정리해보면 첫 frame rendering 과정에서는 [1]의 release 이후, ([2]의 acquire과 [3]의 release)가 ([4]의 acquire과 [5]의 release) 보다 먼저 실행이 완료되고, 그 후 ([4], [5])의 실행이 완료되면 다시 ([2], [3]) 의 실행 완료가 반복되는 구조이다.
- [2]와 [3]의 순서는 semaphore가 아니라, acquire에서 지정한 dst stage mask로 인해 생긴 execution dependency chain으로 강제된다.
- acquire시 second synch scope는 dst stage mask로 지정할
ComputeShaderstage의 연산들이 되고, 그 사이에 dispatch 명령이 있고, 그 후에 release 시 first synch scope는 src stage mask로 지정할ComputeShaderstage의 연산들이 된다. - 결국 release, acquire의 정의 시 언급 된 실행 순서에 따라서, [2]의 acquire이후 [3]의 release 실행을 보장할 수 있게 된다.
- action type commands이외에는 stage의 개념이 없으므로, 다른
vkCmdPipelineBarrier()자체가 synch scope에 포함된다고 볼 수는 없을 것 같다.
- 마찬가지로 [4]와 [5]도 중간에 지정해주는
VertexInputstage의 역할로 인해 execution dependency가 생길 것이다. - 그리고 각 pipelineBarrier에서 해당되는 src/dst stage mask 이외에는 none pipeline stage (top/bottom)을 사용해줬는데, 각각 기다릴 것이 없고 기다리게할 것이 없게 해서 알아서 최적화 되도록 설정해줄 수 있다.
- 우리도 semaphore를 통해 execution dependency를 주었는데, 사용될 부분을 미리 살펴보면 다음과 같다.
- 예시
- https://github.com/KhronosGroup/Vulkan-Docs/wiki/Synchronization-Examples#transfer-dependencies
- transfer 과정에서 이후에 사용할 queue의 family index가 다른 경우는 Queue family ownership transfer를 수행해주고 있다.
-
https://stackoverflow.com/questions/60310004/do-i-need-to-transfer-ownership-back-to-the-transfer-queue-on-next-transfer
- 위 예시에 해당하는 질문글이고, semaphore 사용과 double buffering 사용시 장점등을 답변하고 있다.
Particle Rendering
다음은 particle rendering과 shader에 관련된 부분의 진행과정이다.
- vertex shader 구현 shaders/particle/particle.vert
- fragment shader 구현 shaders/particle/particle.frag
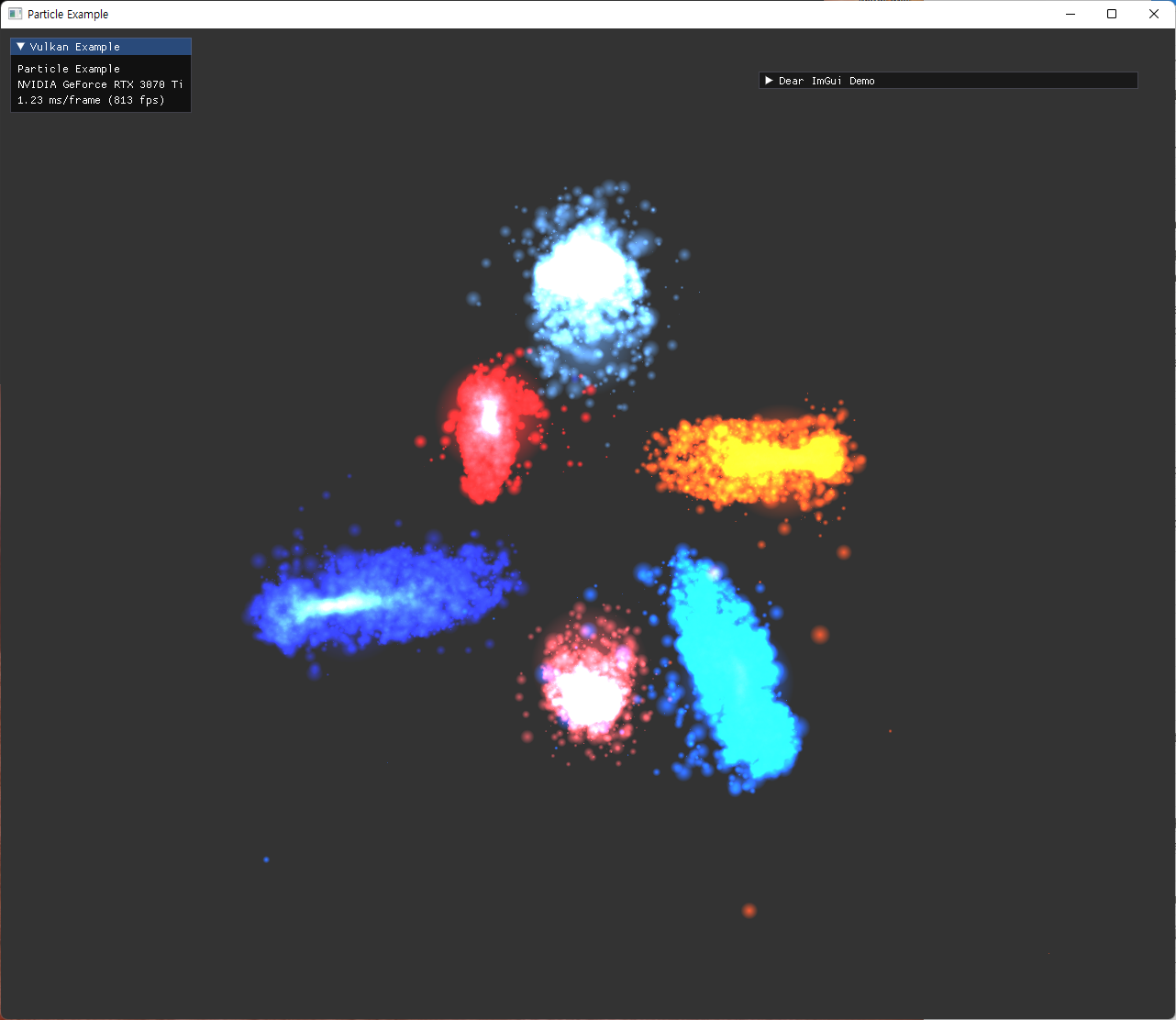
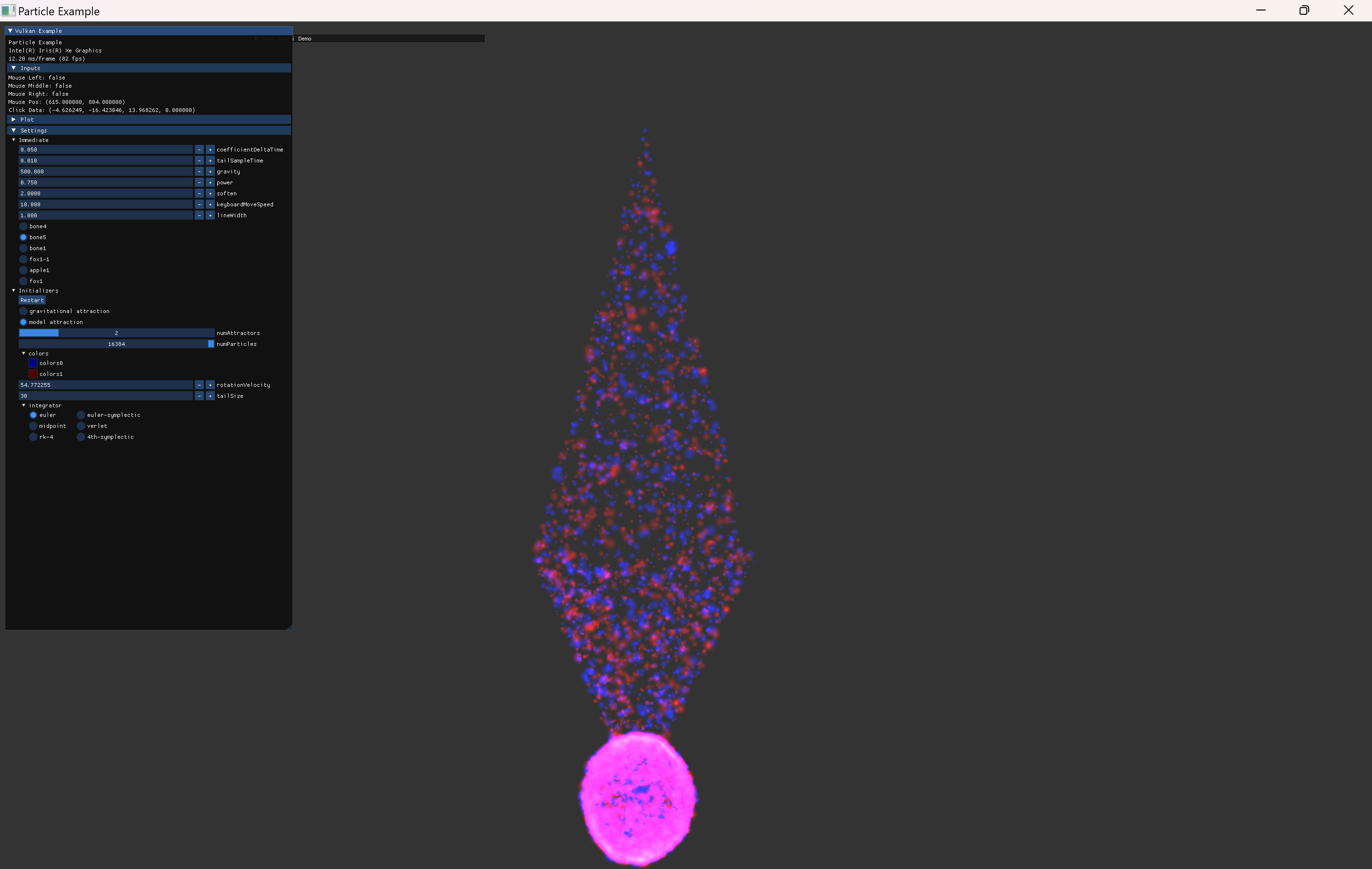
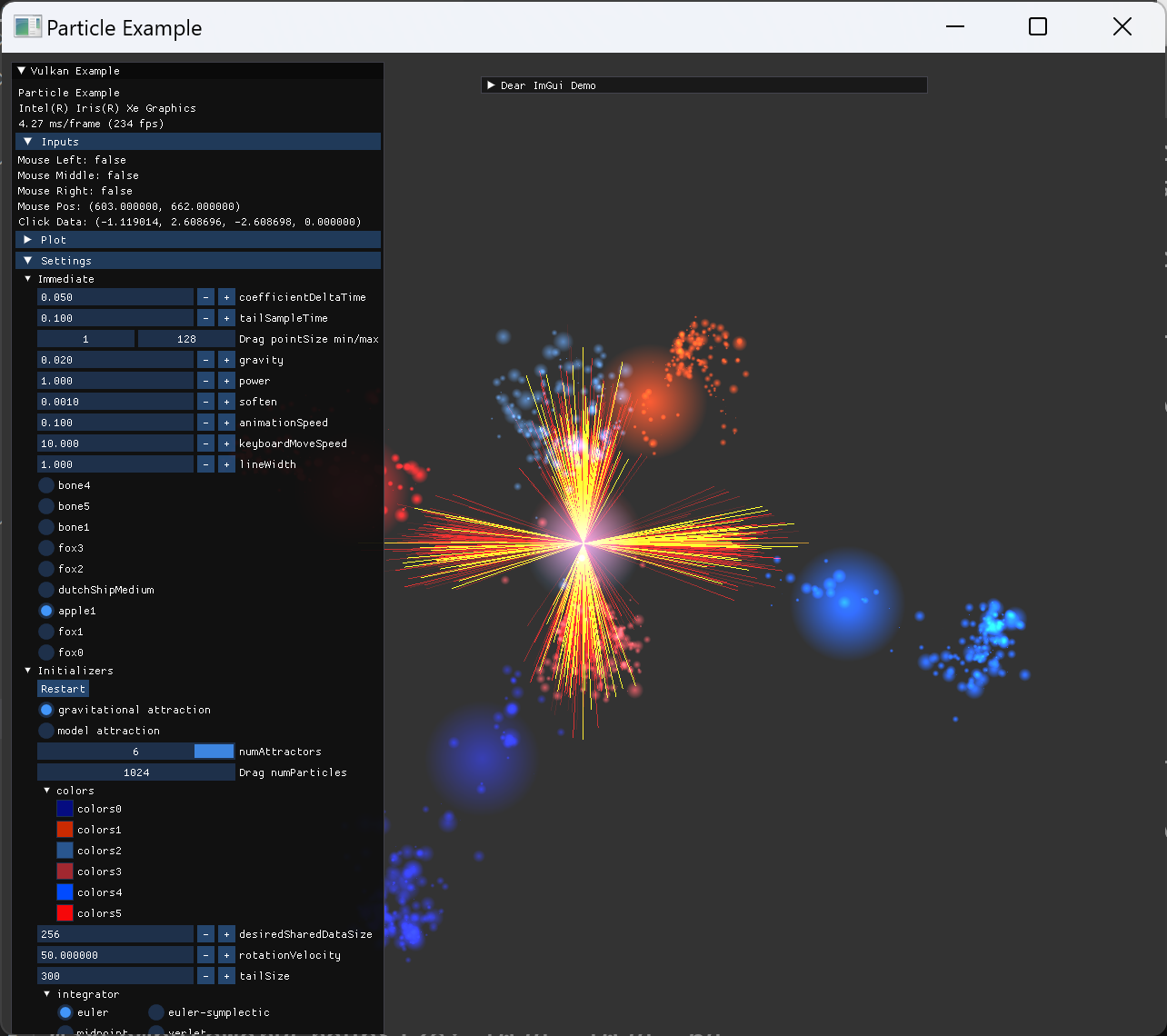
particle의 초기 위치 설정은 원본예제의 attractor를 사용하는 방식과 동일하게 작성했다. 각 축마다 양쪽으로 2개씩 위치시키는 방식인데, 해당 위치에는 mass가 큰 particle도 하나씩 위치시켜서 attractor의 역할을 한다. 이 mass는 particle의 크기를 통해 나타내도록 shader에서 구현된다.
| image | explanation |
|---|---|
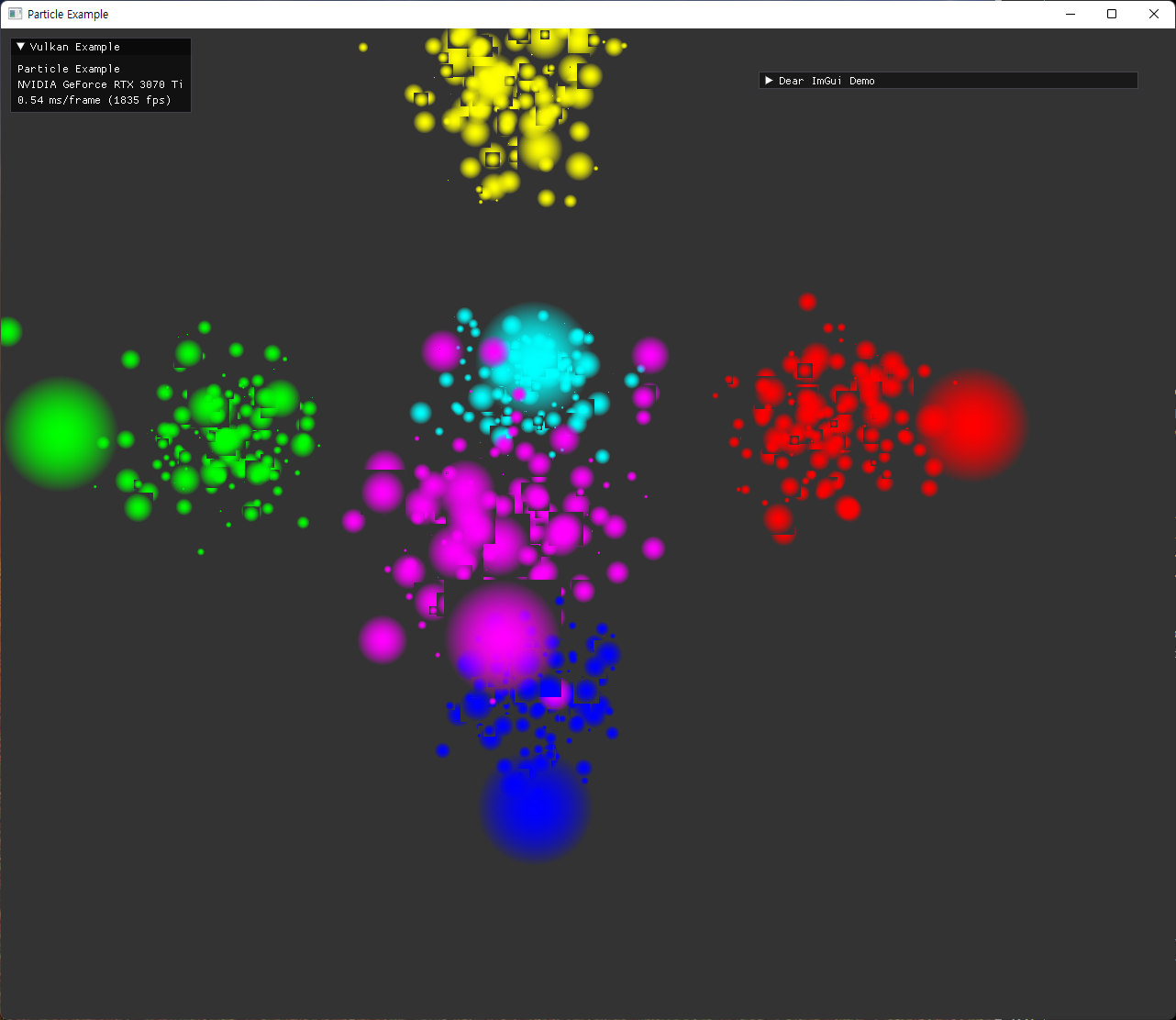 |
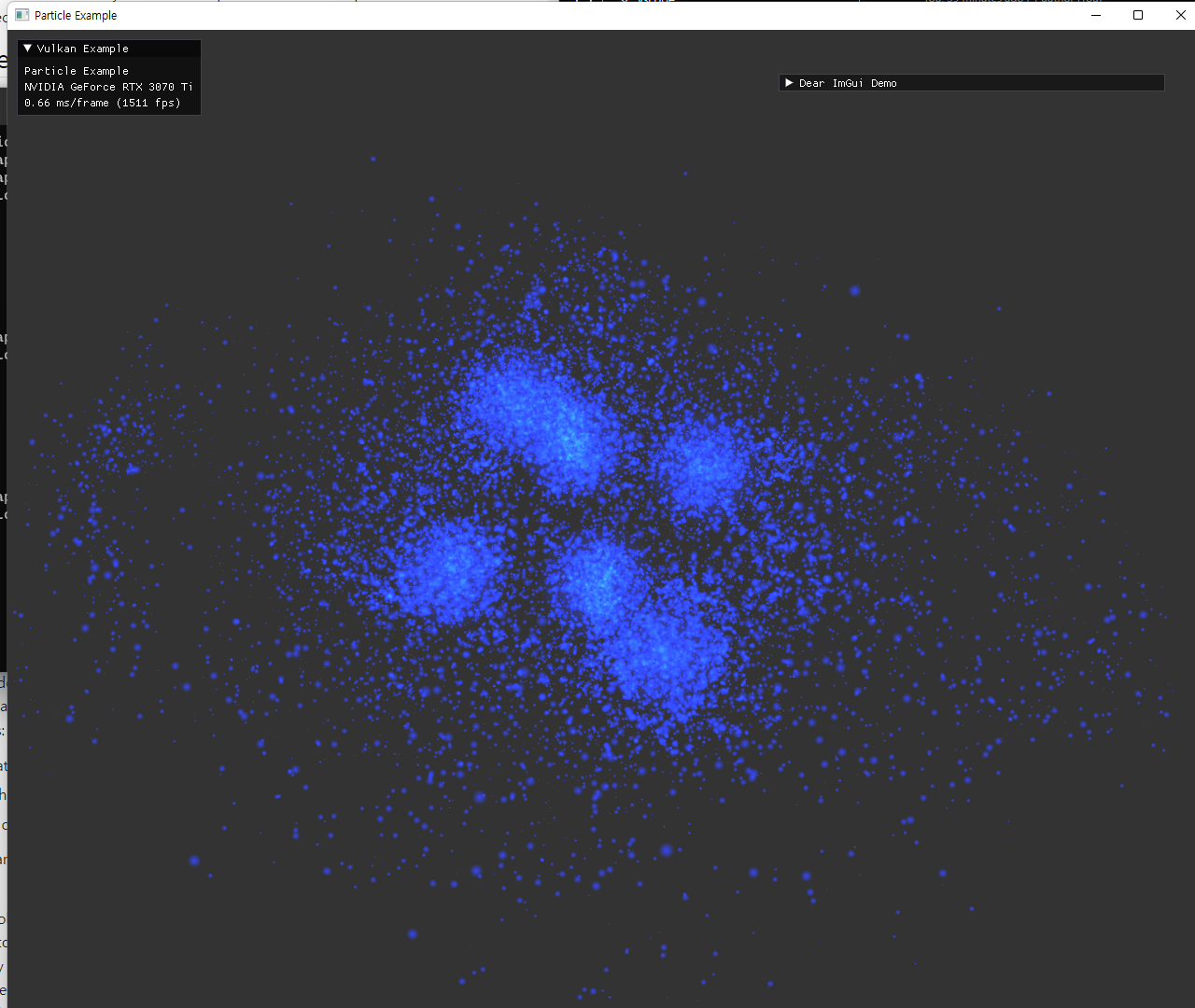
particle은 계산된 position과 gl_PointSize 를 이용해서, fragment shader에서 원 형태의 sprite가 되도록 표현했다. alpha값을 조절해서 중앙이 더 진하게 보이도록 설정했다. 원 주변의 사각형이 겹친 부분은 depth가 제대로 구현되지 않았는데, transparent 관련 구현 대신 depthTestEnable을 끄고 pipeline state를 생성하는 방식으로 해결했다. |
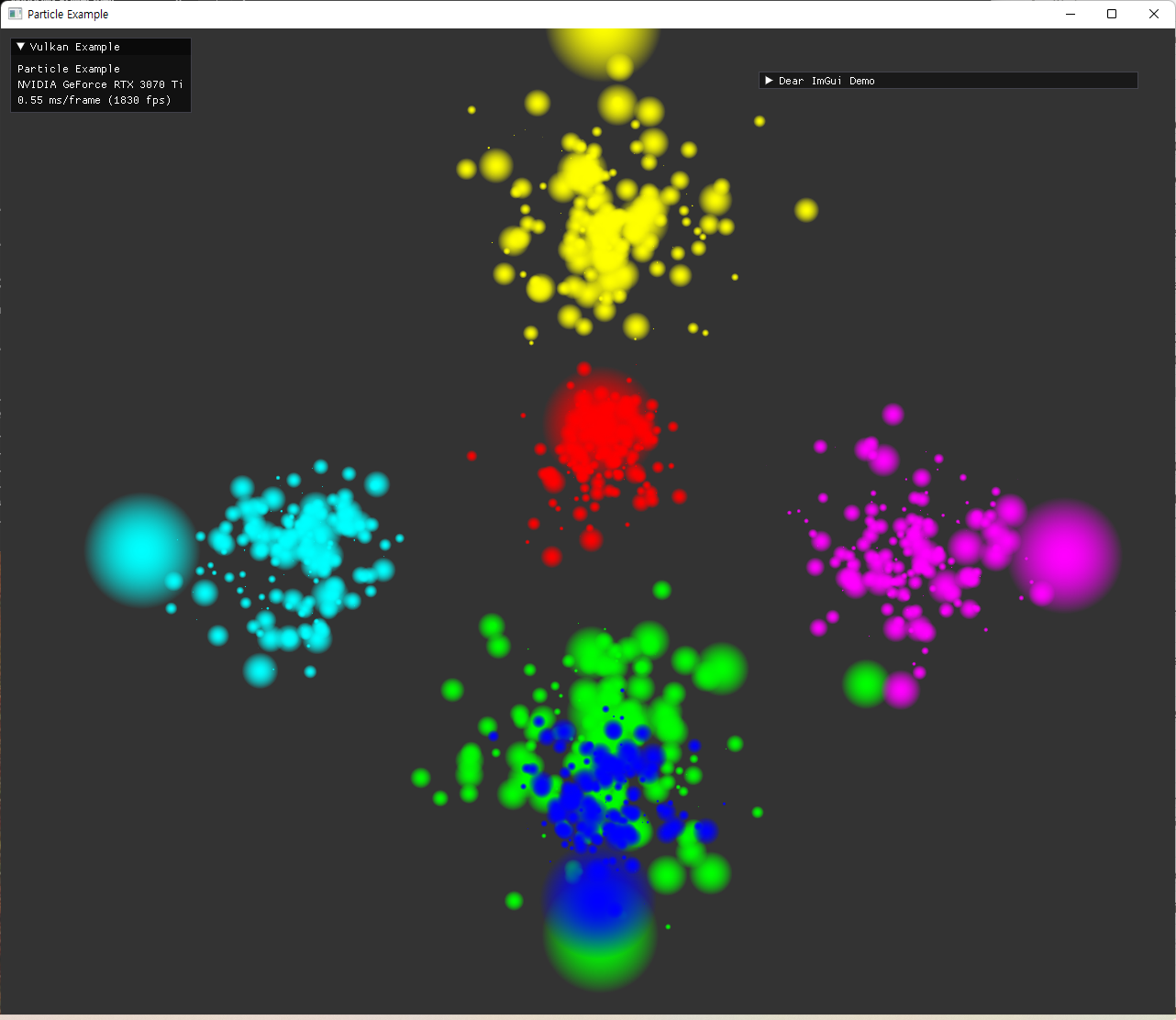 |
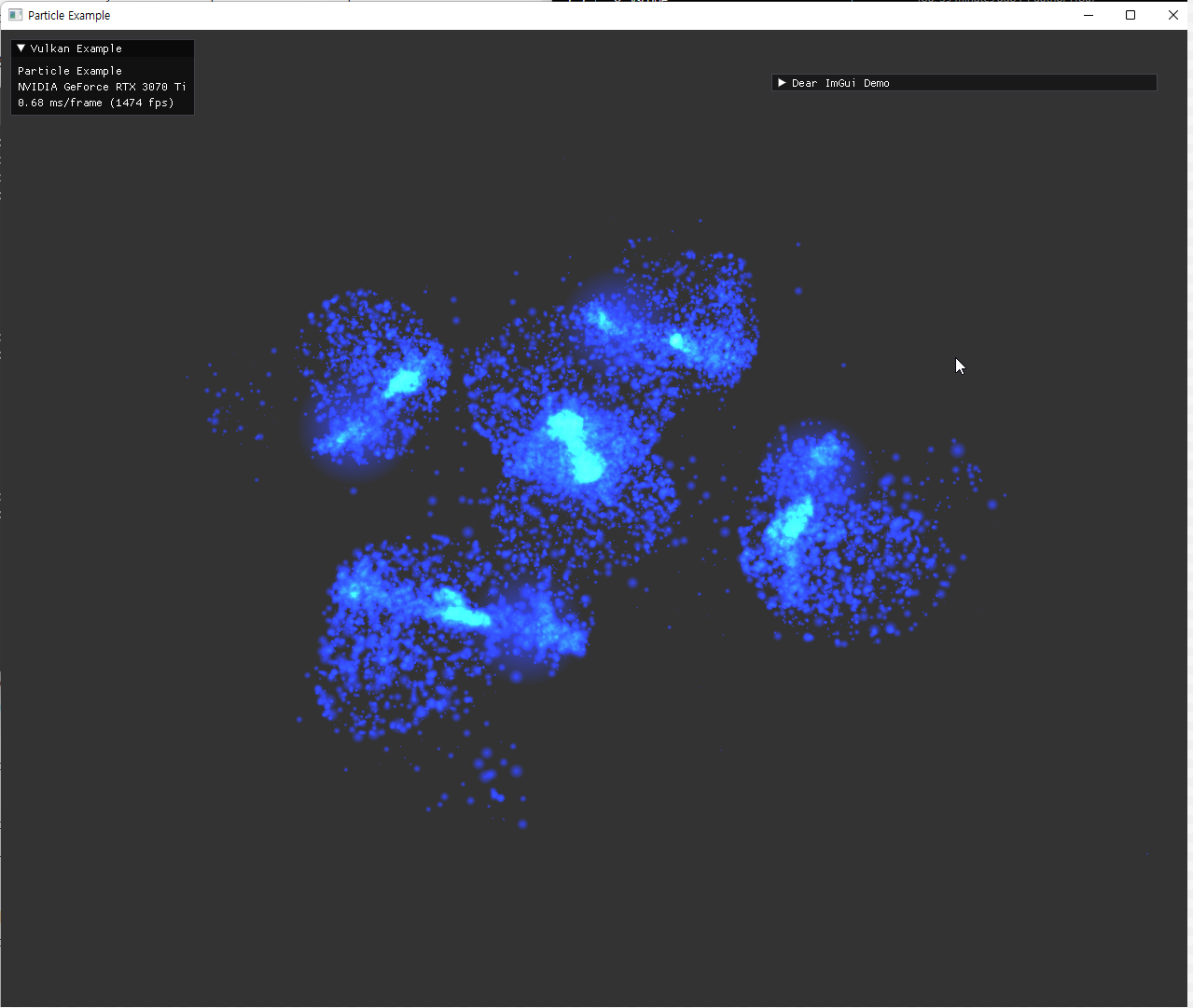
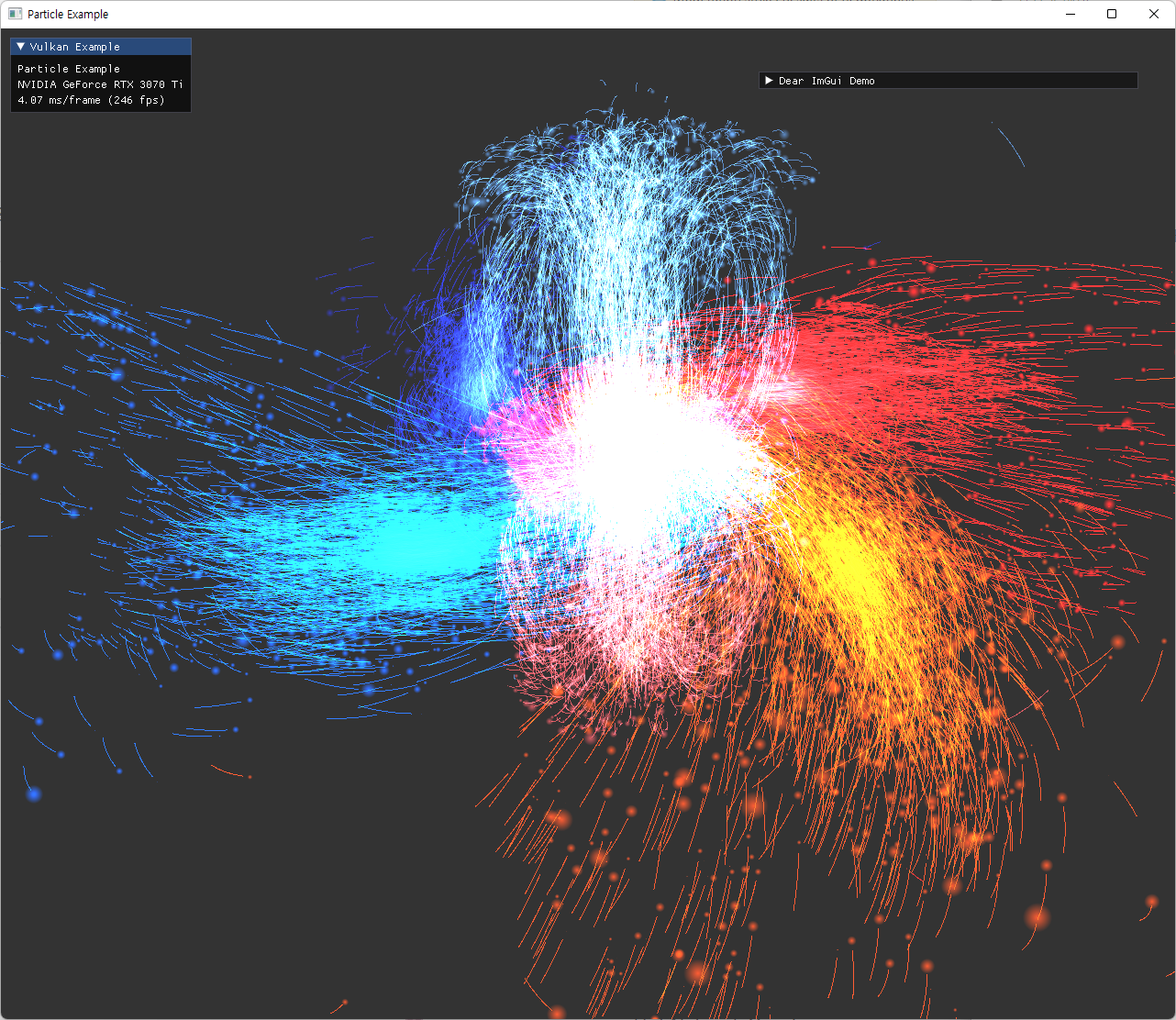
원형의 sprite와 alpha 값 조절은 잘 표현되었지만, depthTest가 꺼졌기 때문에, 더 뒤에 있어야 할 파란 점들이 초록 점들을 뚫고 보이는 현상이다. 이를 제거하기 위해 additive color blend 방식으로 보여지도록 설정했다. |
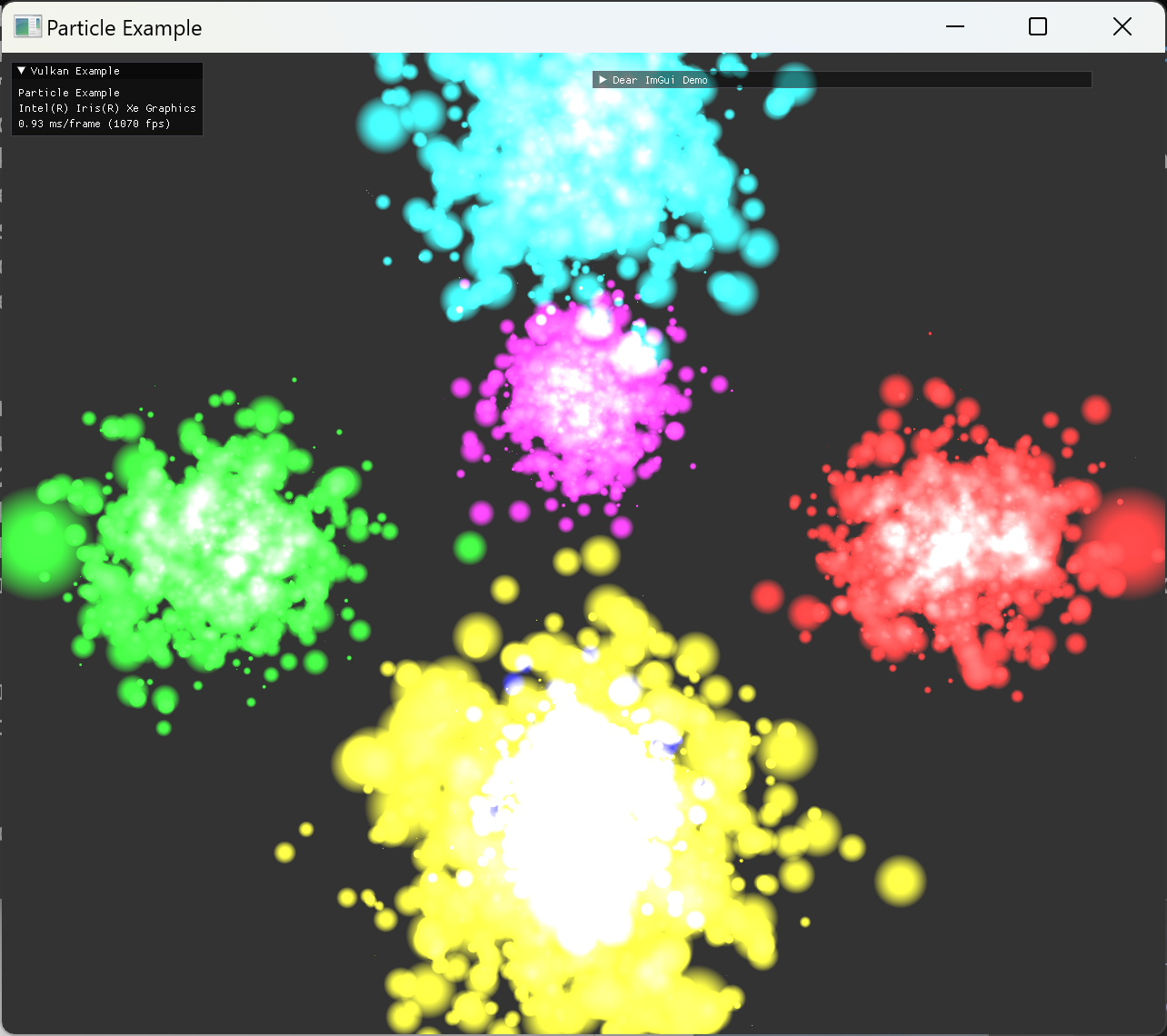 |
additive color blend로 겹친 부분이 흰색에 가깝게 보이도록 빛나는 효과를 의도한 결과이다. color blend로 1, 1, add를 설정해 줬고, alpha blend로 src, dst, add를 설정해줬다. |
Graphics Pipeline
graphics pipeline은 위처럼 particle rendering으로만 단순하게 구성되어 있다. 추후에 trajectory를 추가하면서, trajectory pipeline을 추가하게 된다.
Particle-Calculate-Integrate
파이프라인과 그 shader 구성은 크게 2개의 step으로 이뤄진다.
-
step-1에서 differential equation의 evalution을 통해 그 시점에 필요한 값들을 계산한다. (주로 가속도 계산이라고 생각하면 된다.) -
step-2에서는 계산된 값들을 누적시키는 적분을 수행한다. 최종 position도 계산한다.
이 두 단계에서 생성하는 값과 계산에 이용하는 값들은 integration method에 따라 다르다. 그리고 integration method의 stage가 여러개 필요한 경우도 있는데, Runge-Kutta method 같은 경우는 step-1을 4번의 stage로 나눠서 계산을 해야 한다. 결국 오차를 줄이는 것과, 계산 비용의 trade-off가 있다고 보면 될 것 같다.
Euler method와 symplectic-Euler method를 비교했을 때는, 연산량의 차이가 없어서 사용하지 않을 이유가 없다.
Compute Pipeline 구성
-
step-1- 기본적으로 SSBO는 particle의 position과 velocitity 정보를 저장한다.
- 이외에
step-1에서 계산해야 할 값이 \(\frac{dp}{dt}, \; \frac{dv}{dt}\)인데, integration method에 따라서 이런 값이 각각 4개씩 까지 늘어난다. 그래서 particle data의 구조는 pos, vel, pk[4], vk[4] 로 구성했다.- 이 크기를 dynamic하게 생성해서 buffer 생성시에 설정하려고 했는데, struct 구조를 dynamic하게 바꿔야하다 보니, 적절한 방법을 찾지 못했다. 이 data 여러개를 한번에
std::memcpy()를 통해 SSBO로 전달해줘야 하므로 다른 stl container를 쓸 수는 없어서 조사하던 중 template programming의 방식이면 가능할지도 모르겠다는 결론에 도달했다. particle 수를 매우 큰 값으로 생성할 수 있으니 이 particle 하나의 data 량은 buffer 크기 등 영향을 많이 미치는 값이라 최적화 할 수 있으면 좋겠지만 우선은 4개씩 사용하도록 고정해놨다. 추후에 개선할 점이다.
- 이 크기를 dynamic하게 생성해서 buffer 생성시에 설정하려고 했는데, struct 구조를 dynamic하게 바꿔야하다 보니, 적절한 방법을 찾지 못했다. 이 data 여러개를 한번에
- 이 최대 4개의 값은 순서대로 하나씩 계산될 수 있는 값이면서 differential equation의 evaluation이 필요한 과정이라 (가속도를 구하는 \(O(n^2)\)의 과정)을 최대 4번 해야한다.
- 이 반복을 위해서,
step-1의 pipeline과 command recording은 최대 4번 반복 가능하도록 loop를 사용해서 구현의 복잡성을 줄였다. 이 값은 처음에는 command line args로 받거나 restart imGui option으로 받아서, pipeline 생성시 사용하는 구조로 되어있다.
-
step-2-
step-2은 비교적 간단하다, 오래걸리는 연산도 없고 어떤 종류의 integration method 든지 한번만 실행되면 된다. - binding 될 SSBO도 고정해놨으므로 각 method마다 차이점은 shader 구현에만 있다.
- 여기서 계산된 particle의 position이 위에서 구현한 particle shader로 전달되게 된다. 그리고 그때의 graphics commands 들과의 synchronization은 Queue owenership transfer 부분에서 미리 설명한 것과 같이 semaphore를 통해 정의되게 된다.
-
-
step-1과step-2사이의 execution dependency- 처음 예제를 따라 작성할때는, 하나의 SSBO만 사용했기 때문에,
step-1계산전에 buffer의 내용을step-2에서 변경시키면 안되기 때문에 필요하다고 생각했다. - 현재 double-buffering(혹은 N-buffering)으로 구현한 상태에서는, 읽어오는 입력값들은 이전
prevFrameIndex의 SSBO를 사용하기 때문에 위의 문제는 없다. - 하지만, i번 particle에 대한
step-1의 연산이 끝나야 생성된 값들을 사용해서 i번 particle의step-2번을 실행할 수 있으므로 실행 순서가 여전히 필요하긴 하다.- 지금 드는 생각인데, calculate뒤에 integrate 내용을 붙여서 하나로 구성하면 큰 문제가 없을지도 모르겠다.
- 성능상 이점이 있을지는 실험해봐야겠지만, 구현상 복잡도는 더 커진다.
step-1만 여러번 반복이 필요한 경우가 있어서step-2과 분리해놓는게 편하다.
- 처음 예제를 따라 작성할때는, 하나의 SSBO만 사용했기 때문에,
- 이 구성은 나중에 추가한 skinning in compute shader 구현 이전까지 유지되고, 이 skinnging을 위한 pipeline은
step-1이전에 추가된다. (step-1에서 가속도 계산에 필요하므로)
Compute Shader 구성
-
step-1의 compute shader 구현 shaders/particle/particle_calculate.comp- pipeline에서 설명한대로, 모든 particle pair로 발생하는 attraction의 가속도 계산의 \(O(n^2)\) 의 과정이 구현되어 있다.
- prevFrameIndex의 particle SSBO는 read only qualifier로 명시한다.
- currentFrameIndex의 particle SSBO에 이후 적분 계산에 쓰일 값들을 계산해서 저장한다.
- UBO로 전달되는 값들 중 사용하는 값은 다음과 같다.
- dt: frame 사이에 시간이 얼마나 흘렀는지를 측정한 값으로 delta timing에 사용됨
- particleCount: particle 수 보다 많은 invocation이 이뤄질 경우에 대한 처리
- 예를들어, local workgroup dimension이 (256,1,1)이라고 하면, \(floor(numParticles/256)+1\) 만큼의 local workgroup들이
vkCmdDispatch()에 의해 실행될 것이다. - 이때 numParticles가 256의 배수가 아닐때는, 항상
gl_GlocalInvocationID가 numParticles보다 큰 invocation이 실행될 것인데, 이런 경우를 걸러주기 위해서 필요하다.
- 예를들어, local workgroup dimension이 (256,1,1)이라고 하면, \(floor(numParticles/256)+1\) 만큼의 local workgroup들이
- gravity coefficient: 중력상수 역할의 계수
- power coefficient: 거리 제곱의 값에 취할 지수. 구현 상 1.5 값으로 지정하면 실제 inverse square law에 해당한다.
- soften coefficient 이다.
- specialization constant 다음 값들을 전달 받는데, 이 값들은 상수로 사용되지만, compile time이 아니라 runtime에서 pipeline 생성시 전달해준 값들로 정해진다.
- 위의 계수 3가지 값도 원래는 specialization constant로 넘겨줬었는데, 실행하면서 변경해보는 것이 편해서 UBO로 형태를 바꿨다.
- SHARED_DATA_SIZE: \(O(n^2)\) 계산의 성능을 높이기 위한 shared memory 사용시 지정할 크기. 전체적인 shader loop와 관련있다.
- INTEGRATOR: integration method의 type
- INTEGRATOR_STEP:
step-1을 여러번 반복하기 위해서 pipeline도 여러개를 생성하는데, 생성할 때마다 단계를 하나씩 높여서 생성하기 위한 변수이다. 내부 입출력 형태나 위치를 지정할 때 분기로 사용된다. - local_size_x_id: local workgroup의 dimension
- 상수로 지정이 되어야하기 때문에 고정된 값을 사용하던 기존 구조에서 pipeline 생성시 전달해주도록 수정했다.
- 구조 설명
- [
gl_GlobalInvocationID.x]를 index로 써서 이 particle 하나에 대한 계산을 하나의 invocation에서 수행한다. - 한 particle의 가속도 계산에서 모든 particle의 위치가 필요하므로 loop가 필요하다. 단순히 0~ubo.particleCount-1 의 loop를 돌지 않고, 두 index i, j와 sharedData를 사용한다.
- i는 0부터 SHARED_DATA_SIZE 만큼 증가시키며 iteration
- [i+
gl_LocalInvocationID.x] index의 particle의 입력값(position 혹은step-1의 이전 stage에서 계산된 결과인pk[4]의 값들) 을 sharedData[gl_LocalInvocationID.x]에 저장한다.- gl_LocalInvocationID.x 는 같은 work group에서의 각 invocation index이다. \(\in [0, \text{gl_WorkGroupSize.x}-1]\)
- 이 particleCount를 넘어가면 사용하지 않을 목적으로 입력정보 대신 0을 넣어놓는다. (이 사용하지 않을 값이 divide by zero 등의 계산상 문제를 일으키지 않을지 주의)
- synchronization
- momory control
-
memoryBarrierShared()호출 - invocation이 thread에 해당하는 실행 단위이므로 한 thread에서 shared variable의 변경후, 다음 접근에서 visible하도록 기다린다.
-
- invocation control
-
barrier()호출 - 같은 work group의 모든 invocation이 모두 이 함수 호출 지점에 도달하도록 기다린 후 재개된다.
-
- momory control
- 이제 j를 0부터
gl_WorkGroupSize.x-1 까지 iteration.-
shardData[j]의 값을 other particle의 입력값으로 사용해서 대상 index의 particle의 가속도 정보에 누적해준다.
-
-
barrier()호출을 통해, 다음 i값의shardData업데이트를 하기 전에 사용이 끝날때까지 기다린다.(memoryBarrierShared()호출은 불필요해 보여서 하지 않음.)
- [i+
- i값을
SHARED_DATA_SIZE만큼 증가시켜서 반복
- [
- 이 iteration이 끝나면, 대상 index의 particle에 영향을 주는 다른 모든 particle에 대한 가속도 계산이 끝나게 된다. (같은 workgroup내의 index의 particle들도 계산이 같은 시점에 끝났을 것이다.)
- 이제 그 대상 particle의
pk[4]와vk[4]에 필요한 정보의 형태로 계산해서step-1의 다음 stage 혹은step-2로 넘어가면 된다.
-
step-2의 compute shader 구현 shaders/particle/particle_integrate.comp- 여기서도
gl_GlobalInvocationID.x의 값을 index로 사용할텐데, 차이점으로 먼저 particleCount와 비교하여 같거나 크면,return;을 통해 미리 계산을 종료해도 된다. (step-1에서는barrier()사용에 유의해야 한다.) - 그 후 내용은 간단하다, 넘어온 정보들을 활용해서 INTEGRATOR type에 따라 다른 방식으로 particle의 pos와 vel을 업데이트해준다.
- 여기서도
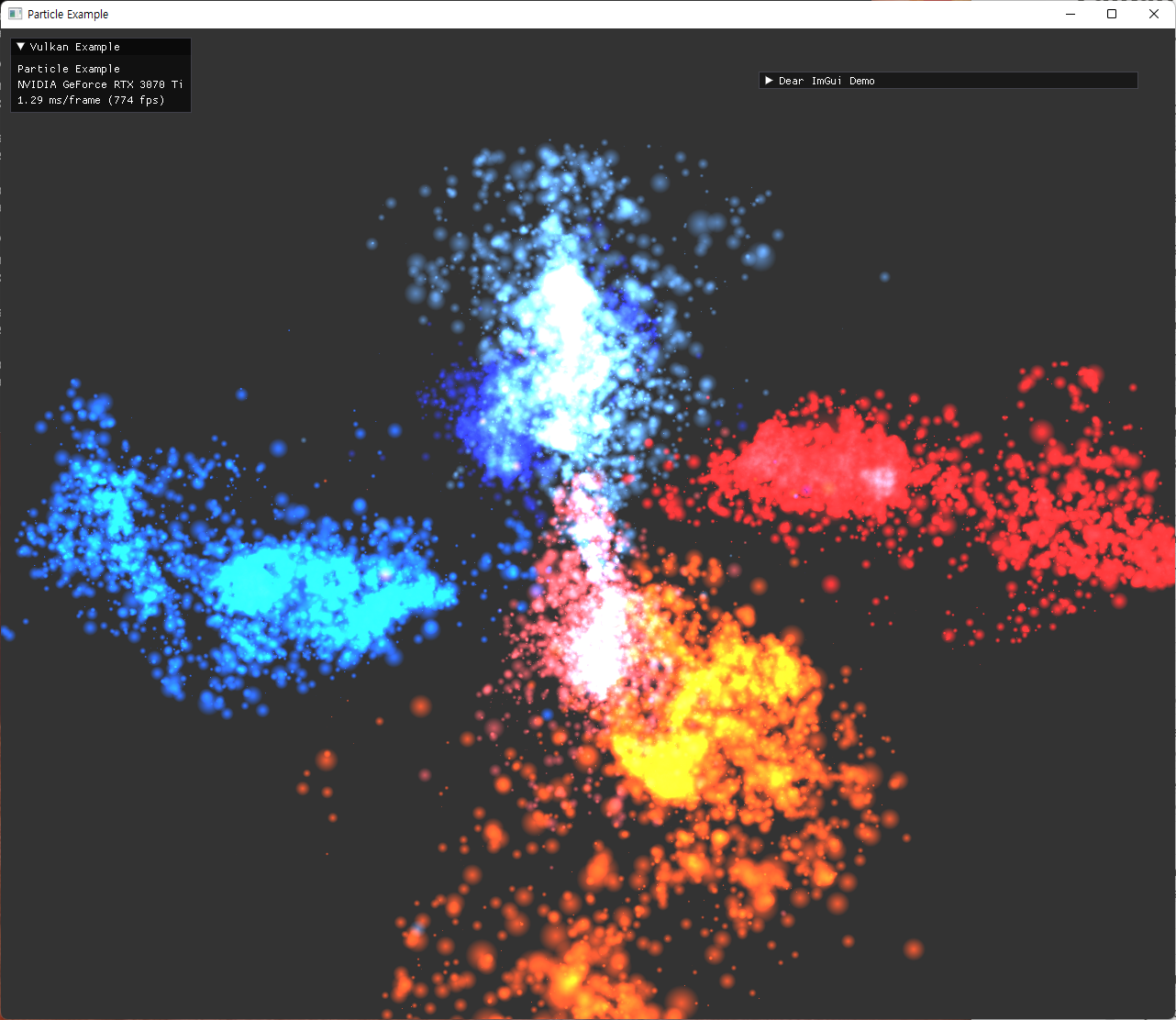
- 업데이트가 완료된 pos값은, 이전에 작성해둔 graphics pipeline으로 넘어가서 particle rendering 부분에서 사용된다. 구현된 실행 결과들은 다음과 같다.
 |
 |
 |
 |
||
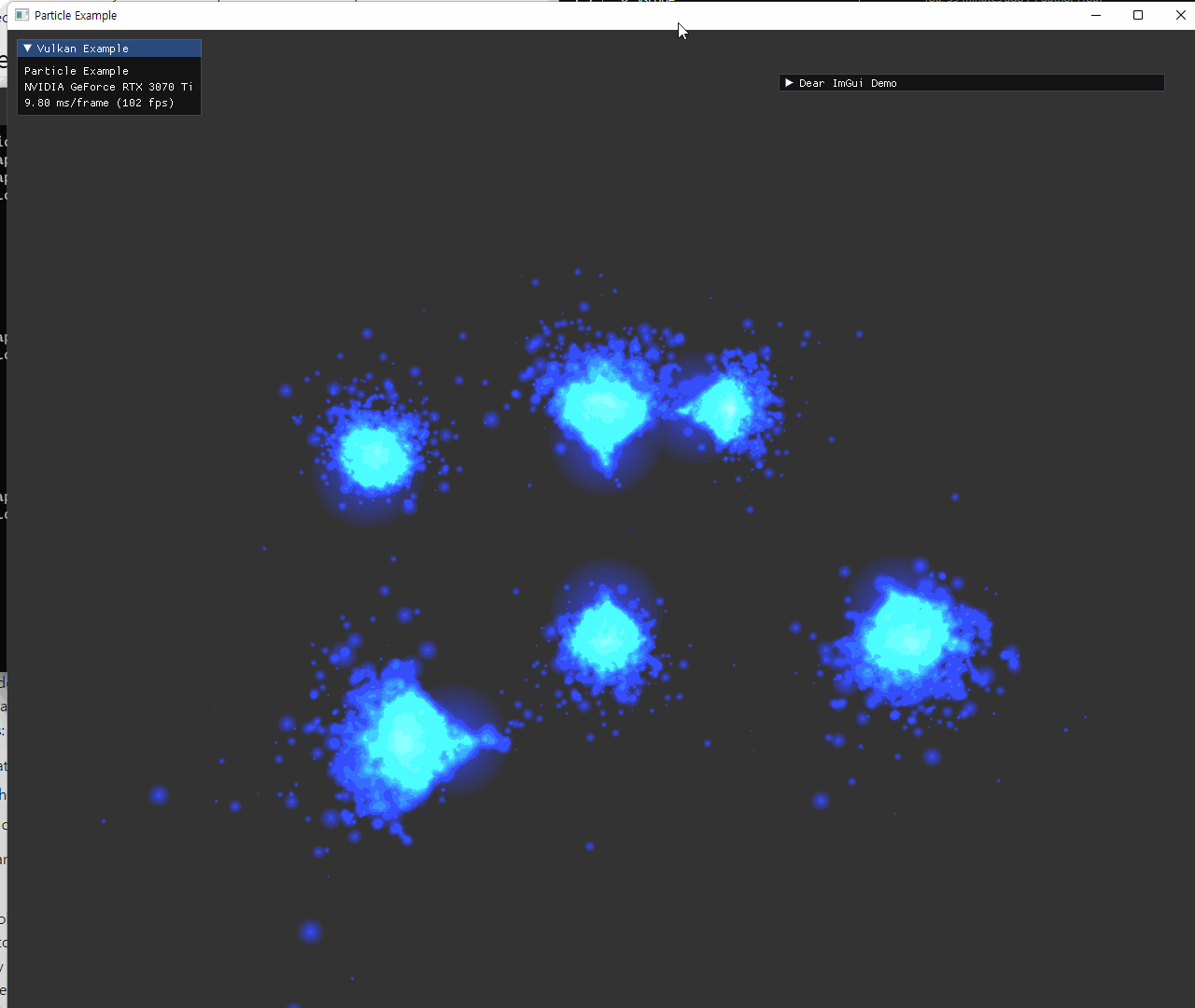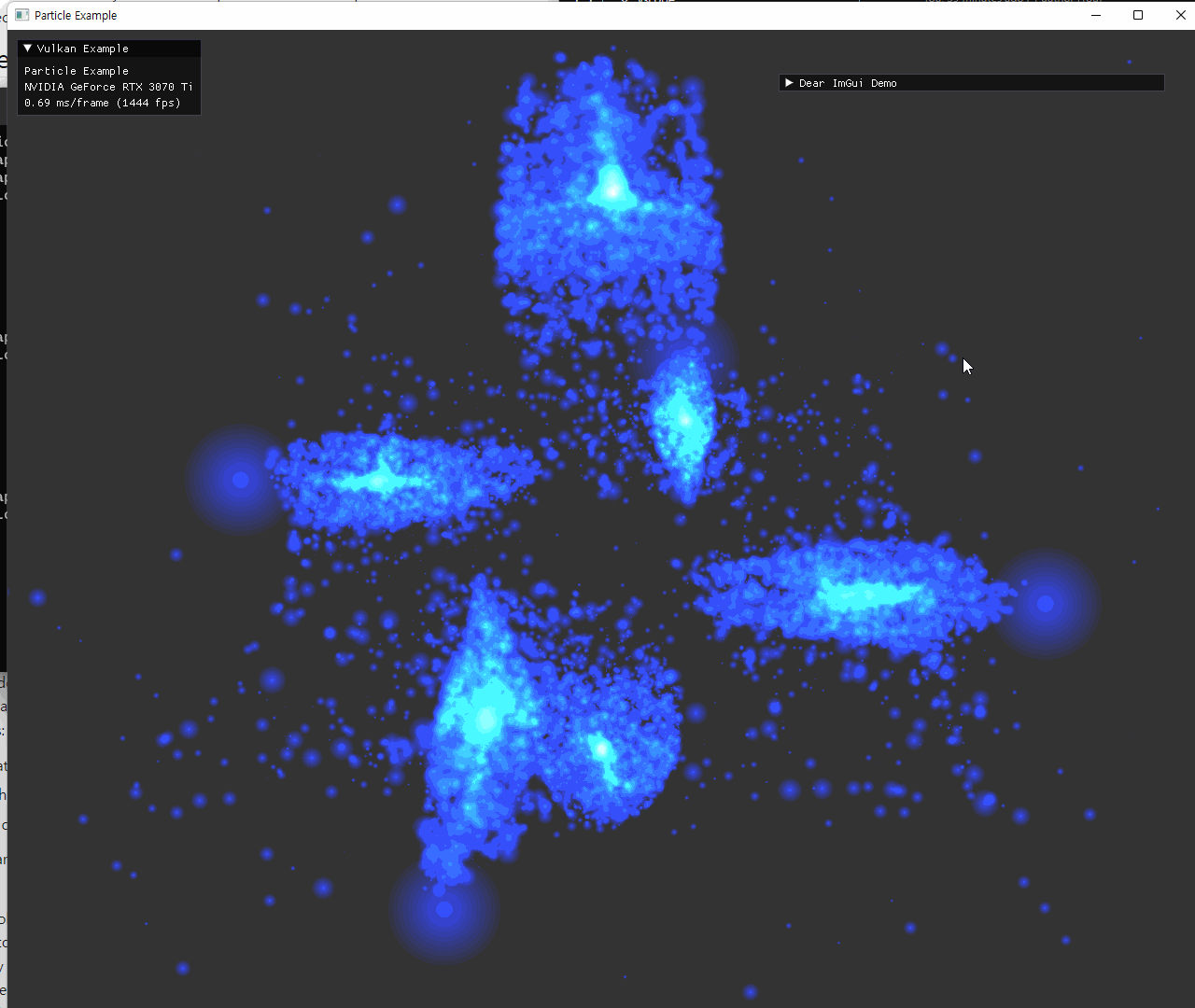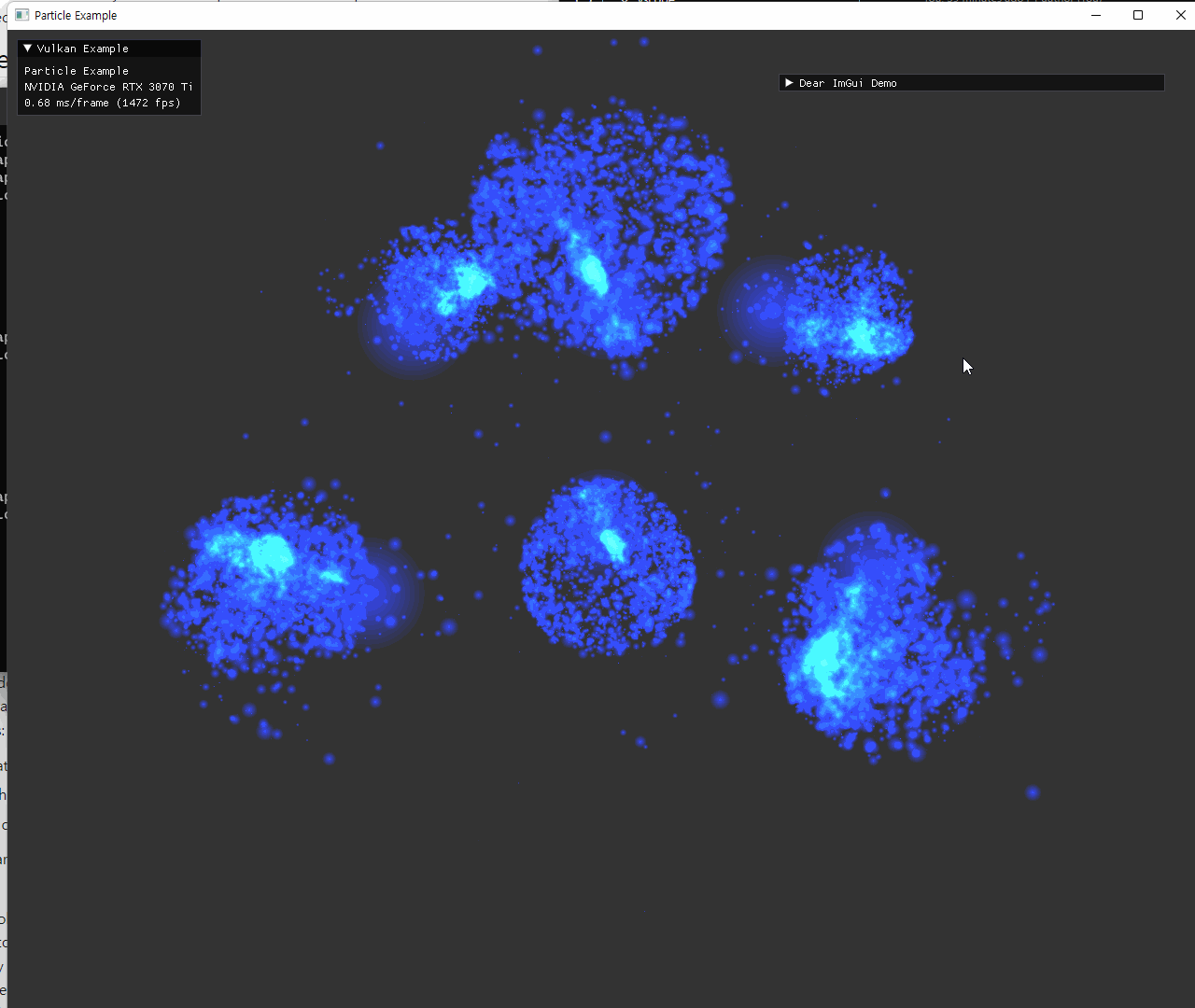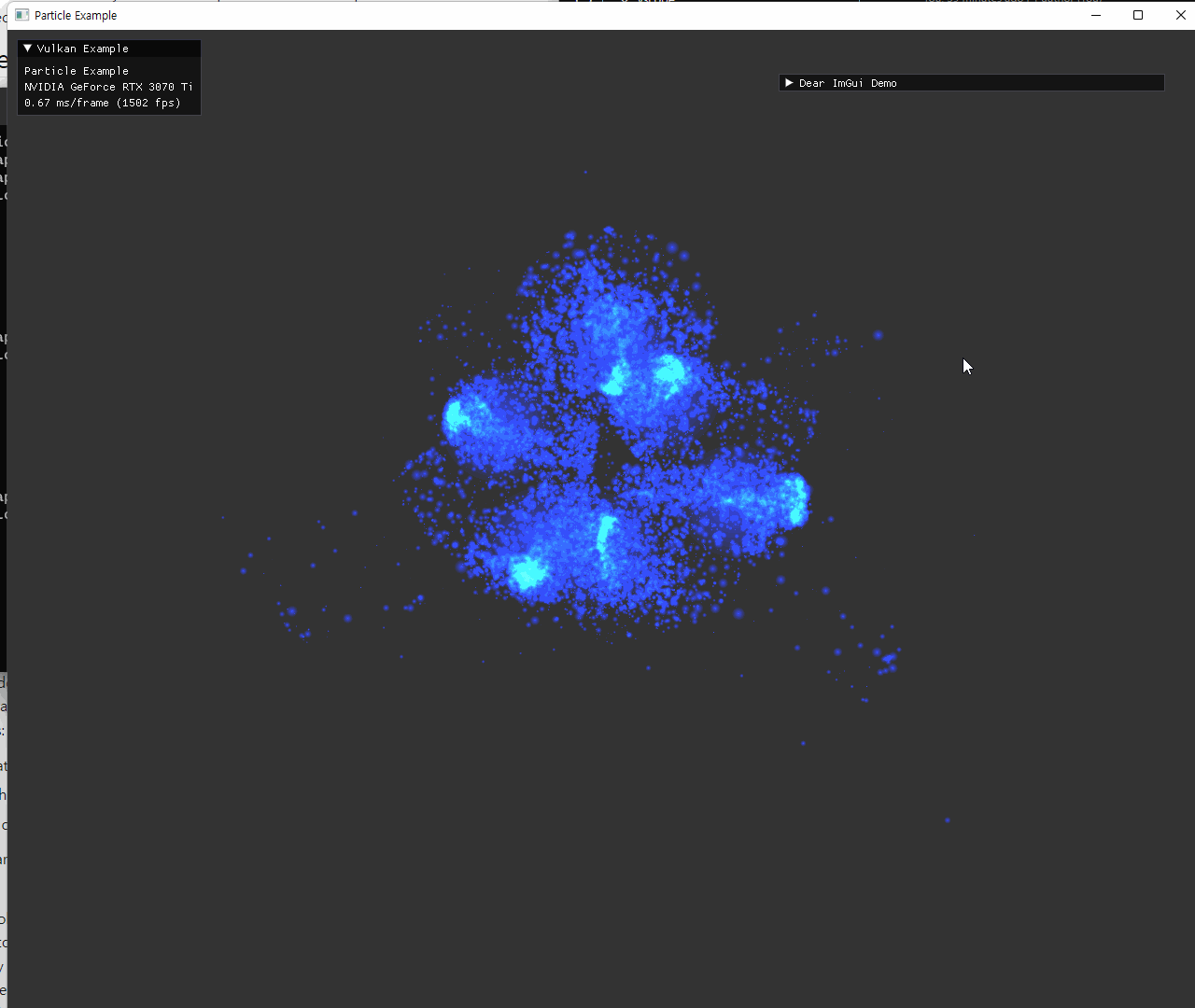
| 색 변경 및 attractor수 조절 | |
|---|---|
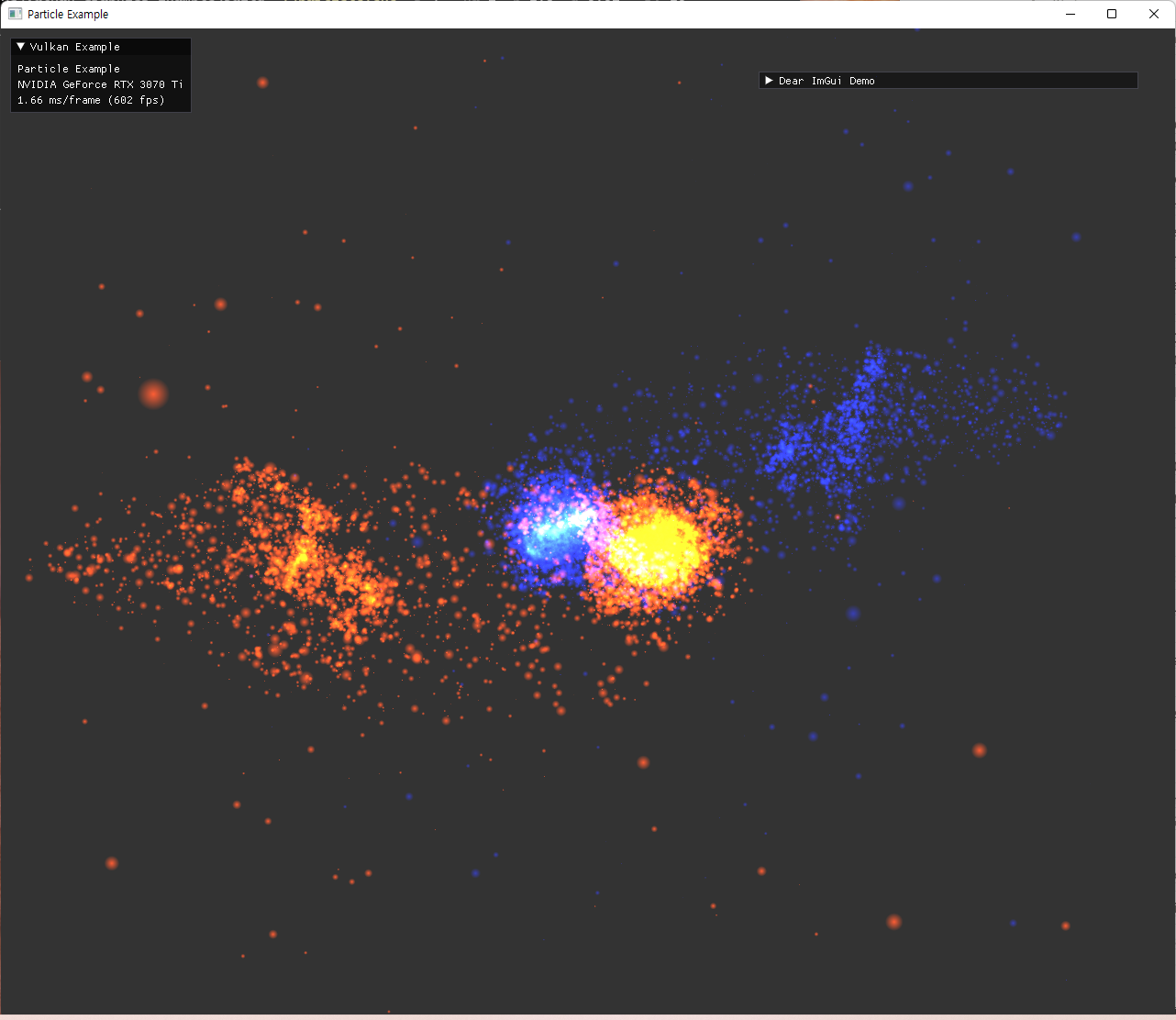 |
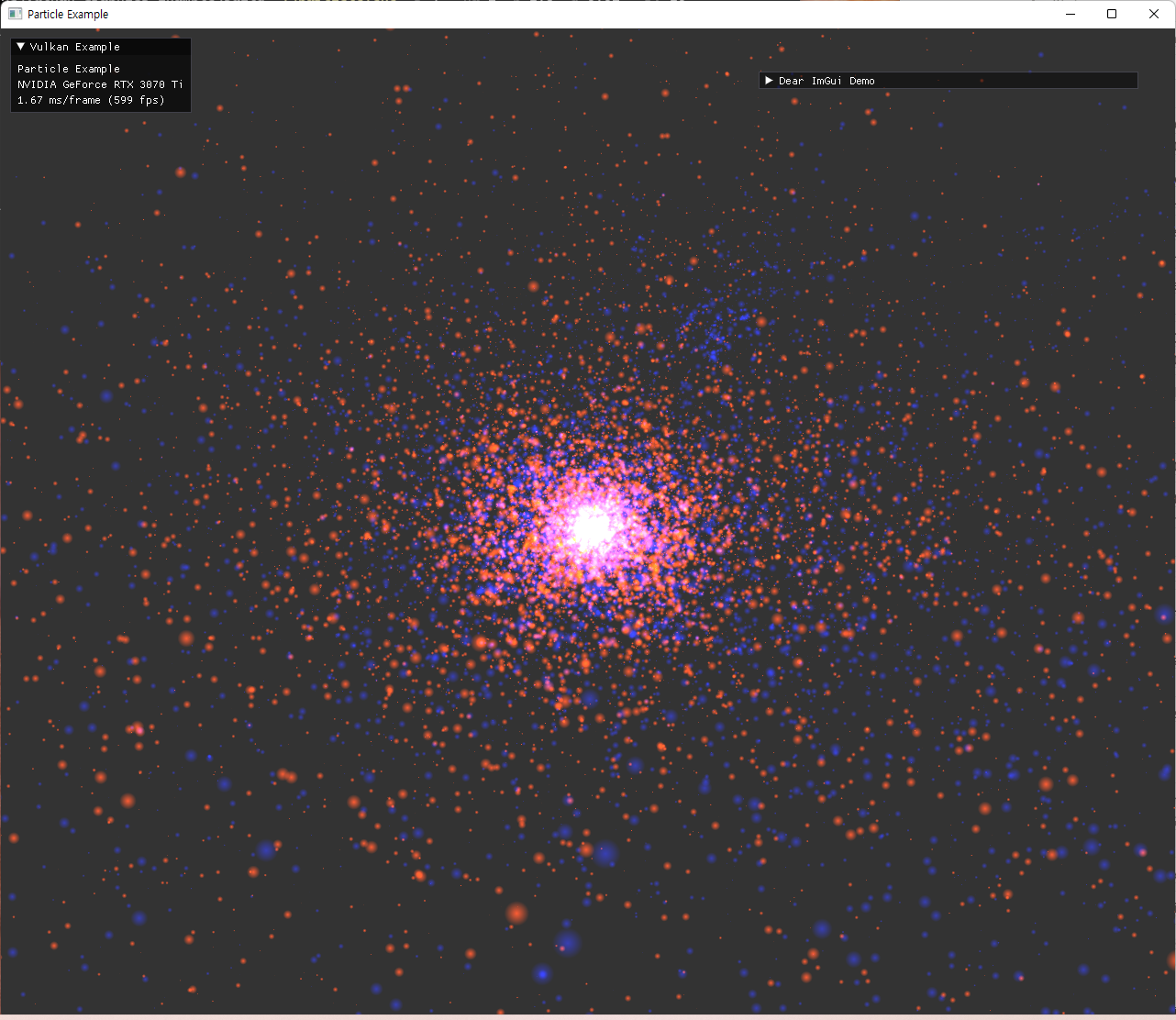 |
 |
 |
Specialization Constants
shader에서 사용하는 계수나, 상수로서 필요한 값들은 specialization constants 기능을 통해 compile 이후의 pipeline을 생성할 때, runtime에서 전달이 가능하다. 처음에는 여러 계산에 사용되는 계수들도 이 방식으로 전달해줬지만, 이후에는 실험 중 UI interation으로 변경이 필요한 값들은 Uniform buffer 사용으로 변경했다.
vulkan-hpp의 wrapper들을 쓰면 다음과 같은 방식으로 사용이 가능하고, 초기 전달해주던 데이터의 값들이다.
std::vector<vk::SpecializationMapEntry> specializationMapEntries;
specializationMapEntries.emplace_back(
0u, offsetof(SpecializationData, sharedDataSize), sizeof(uint32_t));
specializationMapEntries.emplace_back(
1u, offsetof(SpecializationData, gravity), sizeof(float));
specializationMapEntries.emplace_back(
2u, offsetof(SpecializationData, power), sizeof(float));
specializationMapEntries.emplace_back(
3u, offsetof(SpecializationData, soften), sizeof(float));
vk::ArrayProxyNoTemporaries<vk::SpecializationMapEntry> a(
specializationMapEntries);
vk::ArrayProxyNoTemporaries<const SpecializationData> b(specializationData);
std::array<const SpecializationData, 1> c = {specializationData};
vk::SpecializationInfo specializationInfo(a, b);
문법상 주의할 부분이 있는데, (a,c)로는 SpecializationInfo를 생성할수가 없다. compile자체가 안되는데, 다른 클래스 생성에서는 쓰던 부분이라 헷갈리는 부분이었다. 예시로 다음 사이트에서 compile해볼 수 있다. https://godbolt.org/z/v69sG4sbK
위의 compile 문제는 template argument deduction과 관련있는데, deduction 시 implicit conversion이 고려되지 않기 때문이다.
a는 type이 고정되어 있기 때문에 implicit constructor 사용이 문제 없지만, c는 type T에대한 deduction이 필요해서 implicit conversion이 고려되지 않아 compile이 불가능하다.
Template argument deduction - cppreference.com
Fix
기존 원본 예제에서는 particle 수가 workgruop size의 배수가 아닐때 실행이 안되던 문제들이 있었다. 이에대해 수정한 내용들이다.
- dispatch 시, 0이 들어가지 않도록 전체
numParticles를 workGroupSize로 나눈 후 +1을 해준다. - SHARED_DATA_SIZE와 workGroupSize가 같도록 수정해줬다.
- 원본 예제에서는 다른 값이 사용될 수도 있는데, 그 경우 shader에서 index 문제가 발생하거나, 일부 particle-particle pair가 계산에 사용되지 않을 수 있다. (계산량을 줄이기 위해 의도된 것인지는 모르겠다.)
- 수정 하던 과정에서
barrier()사용과 compute shader 개념에 부족한 부분이 있어서 computation이 멈추거나 하는 문제가 있었는데, 다음 자료를 참고했다.
Two-Body Simulation and Verification
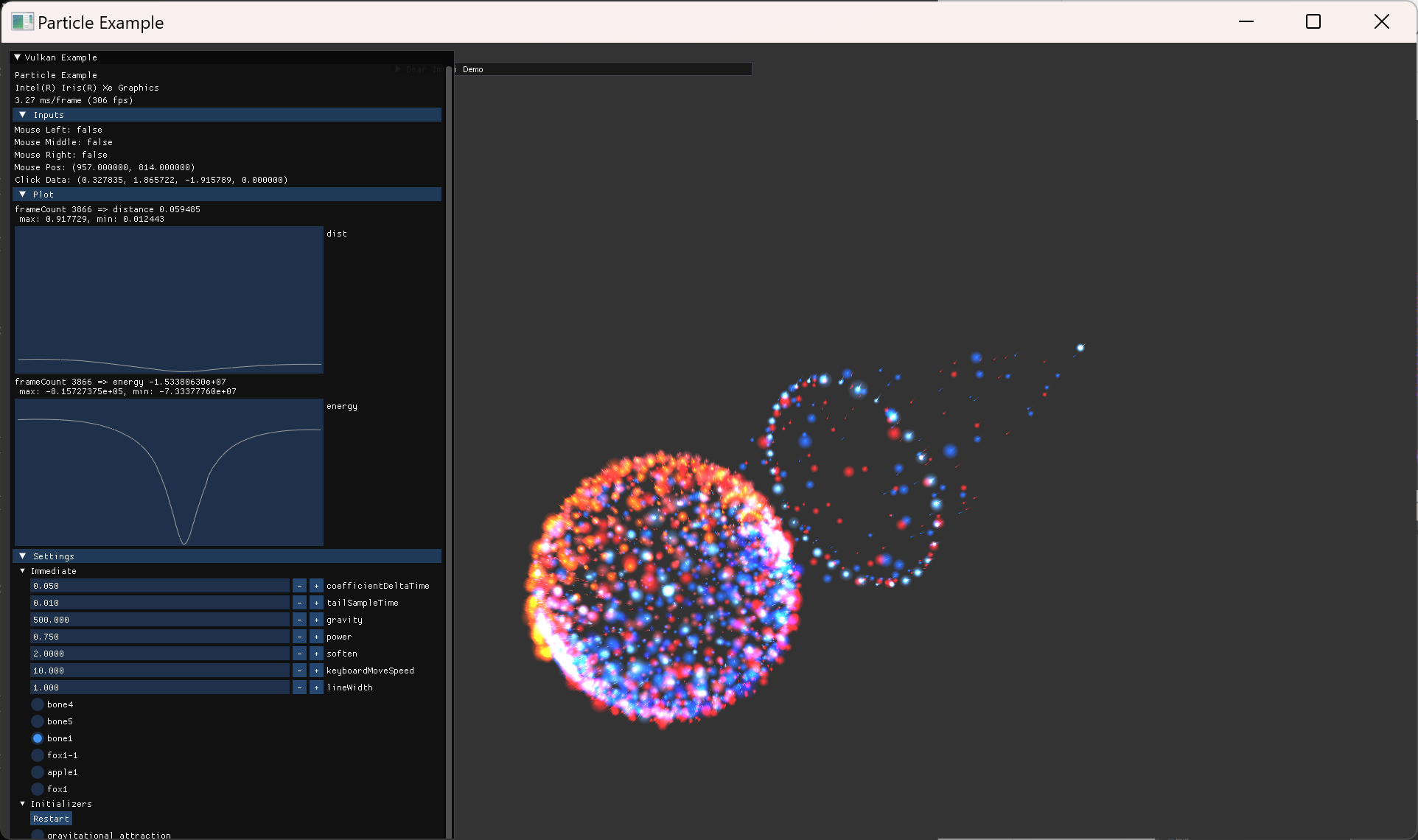
이제 눈에 보이는 simulation 결과를 얻게되었다. 그래서 이 결과가 의도대로 동작하는지 점검하고 다음 과정을 진행하고자 했다.
- 다음과 같이 다른 simulation 자료와 비교하면서 확인을 했다.
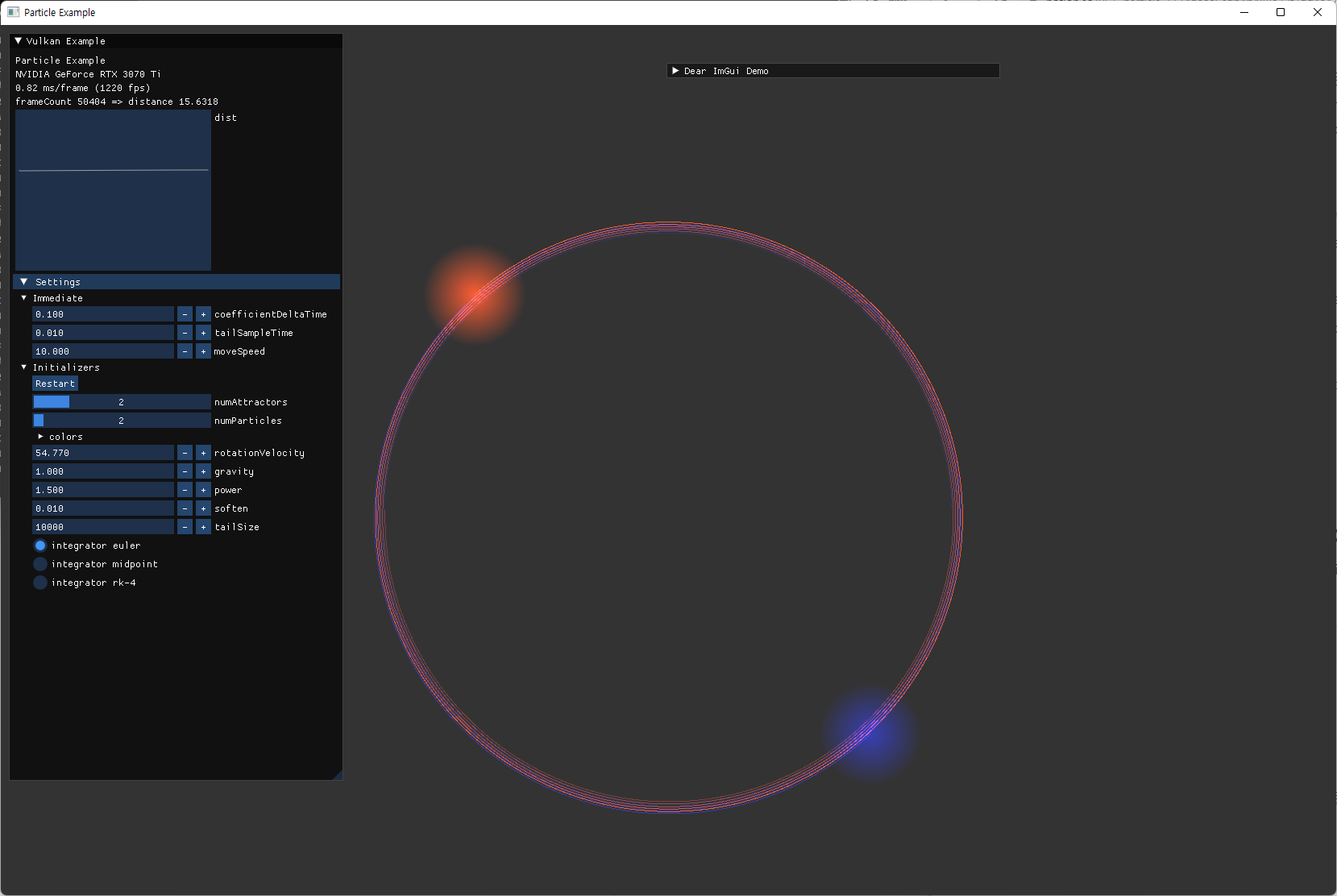
- 다음 처럼 간단한 경우인 2-particle이 원운동을 하도록 수치를 조정해서 실행했다.
-
.\particle.exe --np 2 --na 2 -g 0.01 --rv 30 -p 1.5 -s 0.001
-
- particle의 trajectory가 남지 않으니 결과를 확인하기 어려웠고, 정확한 물리량을 출력하는 것도 필요해보여 이 기능들을 먼저 추가하기로 했다.
Trajectory
particle이 움직이면서 만드는 궤도 혹은 자취를 남기기 위한 기능이다. 내구 구현 명칭은 tail로 명명했다.
- 첫 구현은 가장 naive 한 접근을 사용했다
- 이후 한번의 최적화 과정을 거쳤는데,
drawIndexed()방식이다.- tail을 그릴 index는 미리 고정된 순서의 초기값을 지정해놓고, vertex만 업데이트해준 방식이다.
- 하지만 여전히 비슷한 수준의 계산과 memory transfer가 필요했다.
- 우선 테스트하는 수준의 numParticles에서는 적당한 연산속도로 계산이 가능해서, 당분간 이 구조를 사용했다.
- commits
- 추후 model attraction부분을 작성하고 나면, 더 많은 수의 particle이 필요해서 CPU를 거치는 방식의 trajectory는 한계가 있어 모든 계산은 GPU로 옮겨줬다.
- 다음은 작성 과정에서 나온 오류와 해결 과정들이다.
|
image
|
explanation |
|---|---|
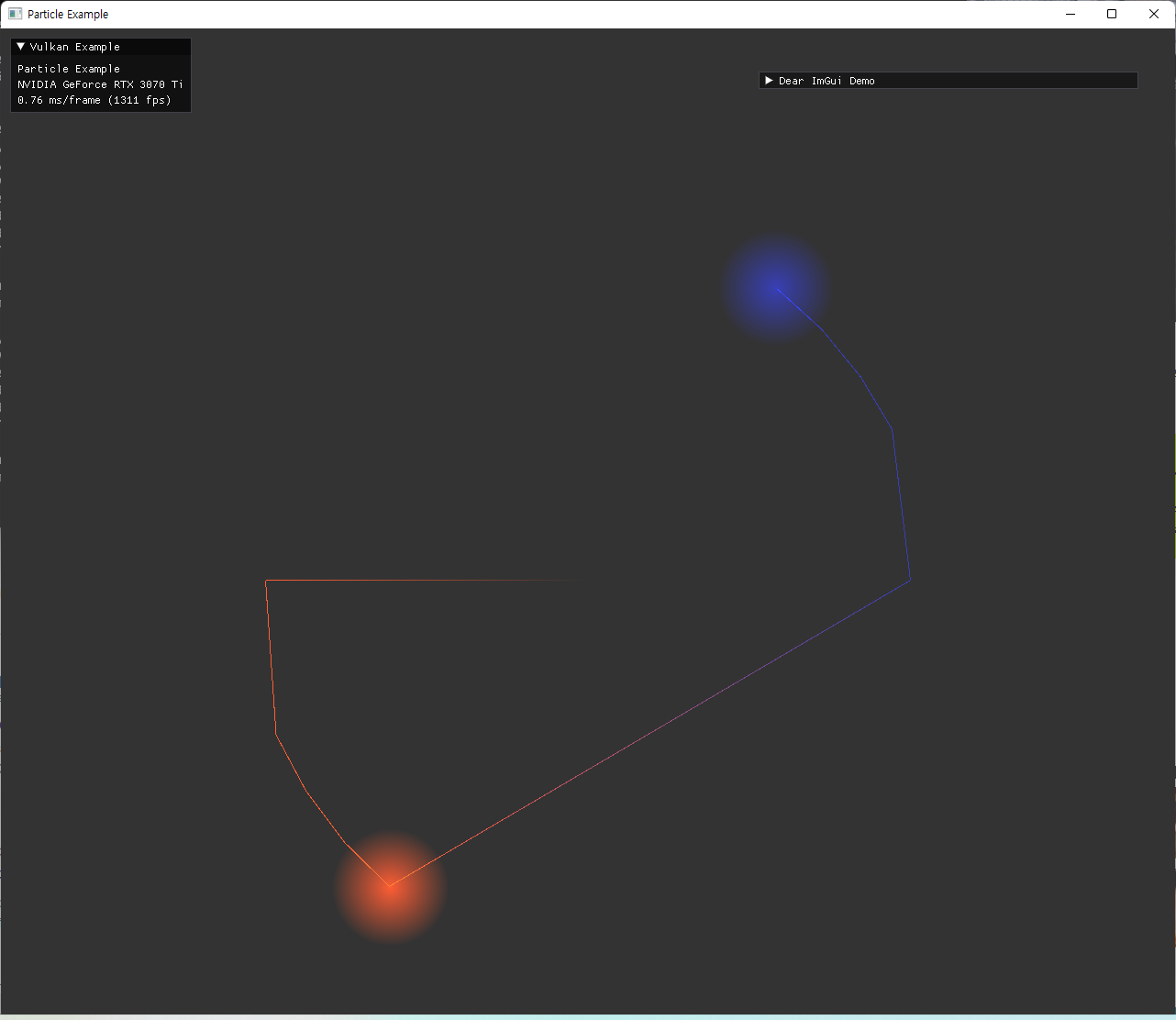 |
처음 tailVertex의 vertex state create info에서 offset 관련 잘못된 지정으로 발생한 문제이다. 원점이 계속 포함된 trajectory가 나타났다. |
 |
drawIndexed() 를 사용했을 때 나타난 문제점이다. 자세히 보면, trajectory가 끊어져야하는 지점(다른 particle로 넘어갈 때)도 이어져 있는데, 파이프라인을 생성할때, inputAssemblyState의 primitiveRestartEnable를 지정해주어야 하는 부분이다. 이를 통해 index buffer에 알맞는 restart index를 지정해주면, 그 index부터 geometry를 다시 그리기 시작하게 할 수 있어서 한번의 draw call로 원하는 trajectory를 모두 그릴수 있게 된다.
|
 |
|
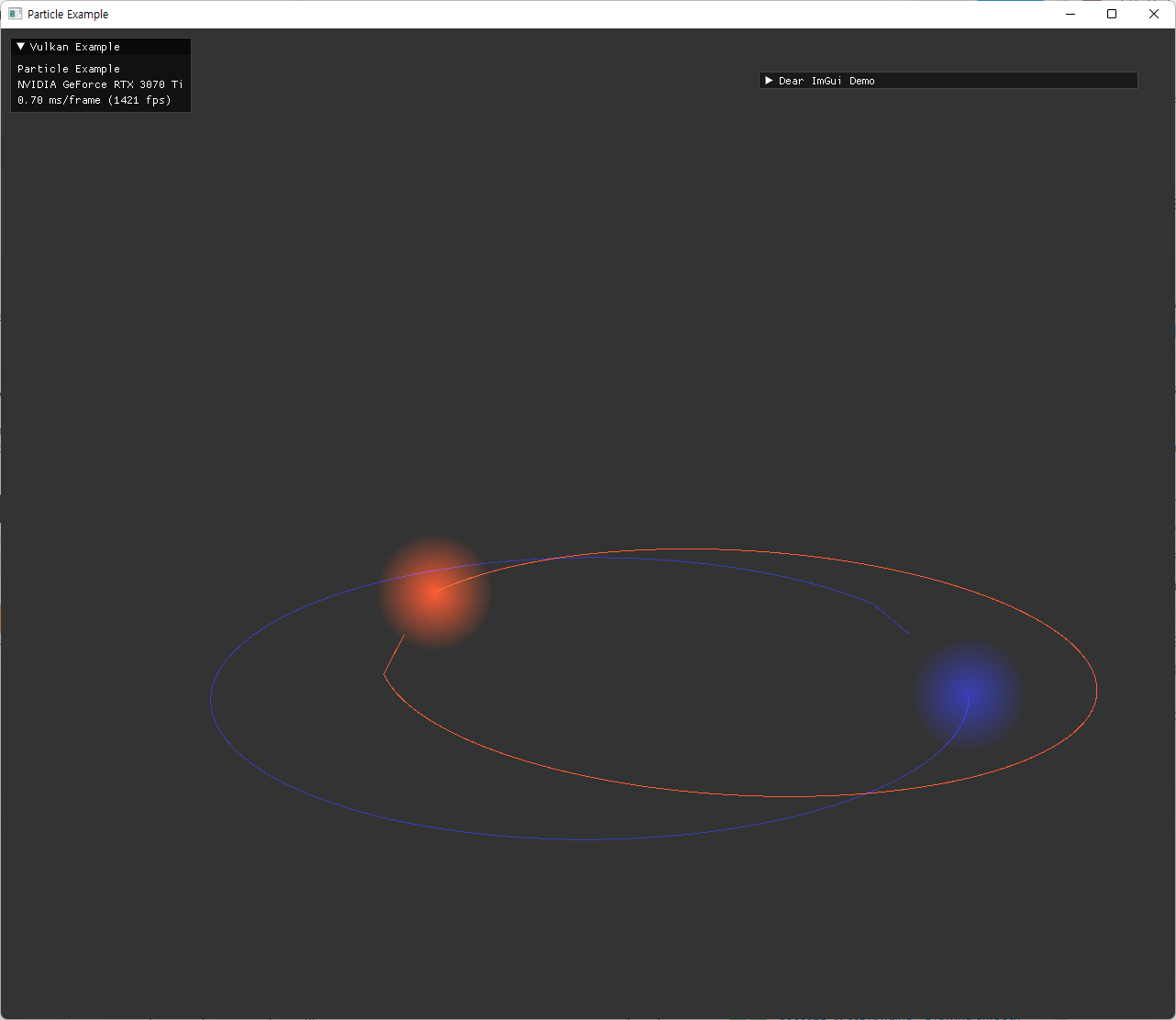 |
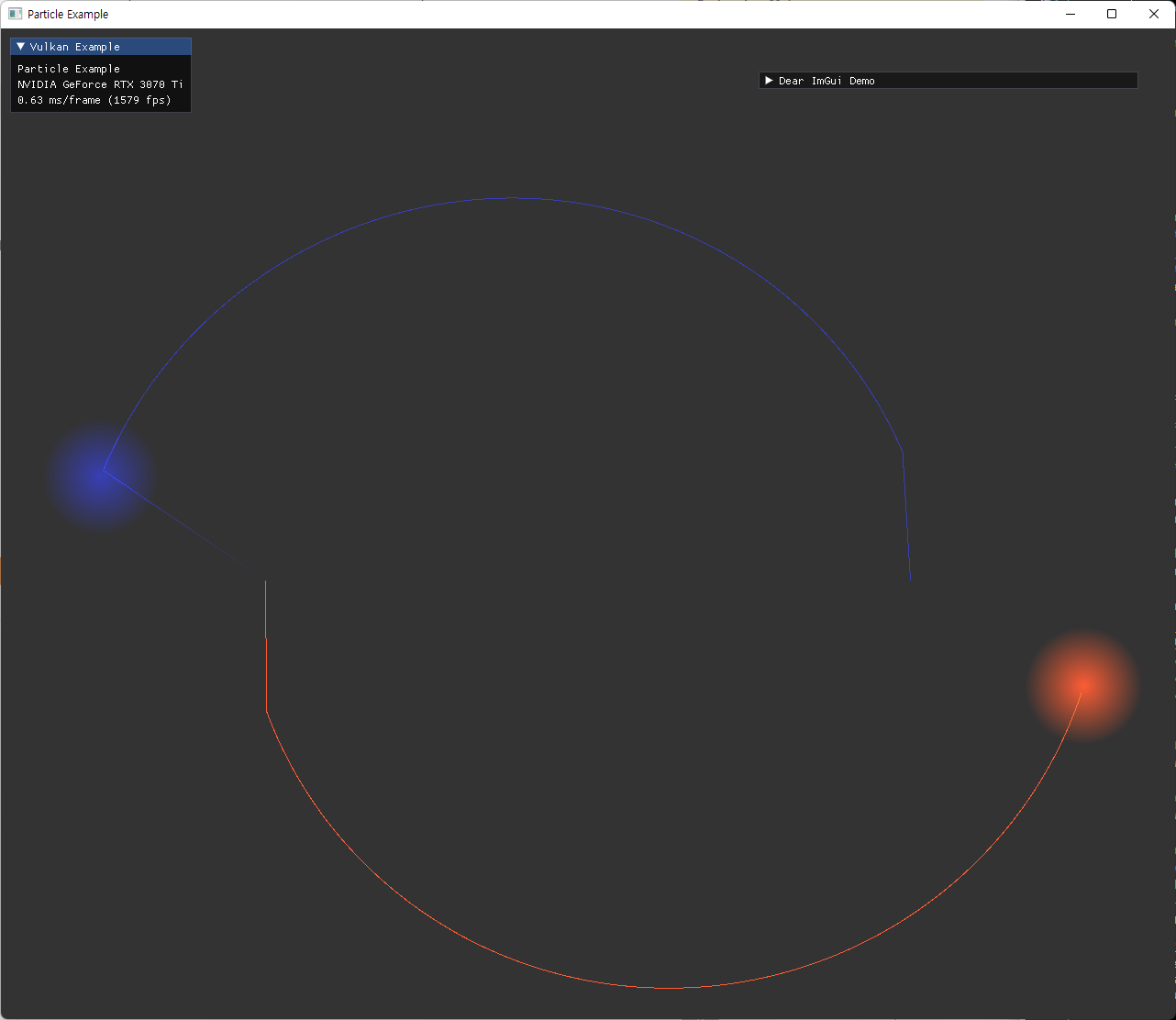
trajectory를 올바르게 그린 후에 확인한 첫번째 오류인데, 궤도의 첫 부분의 오차가 유난히 큰 문제가 있었다. simulation 속도를 엄청 느리게 할 때는 이런 오류가 나타나지 않아 delta time과 관련된 오차 부분을 살펴봤다. 원인은 frameTimer의 값이 1.0으로 초기화 되어 있어서 발생한 integration error였고, 단순히 0으로 바꾸면서 해결됐다. |
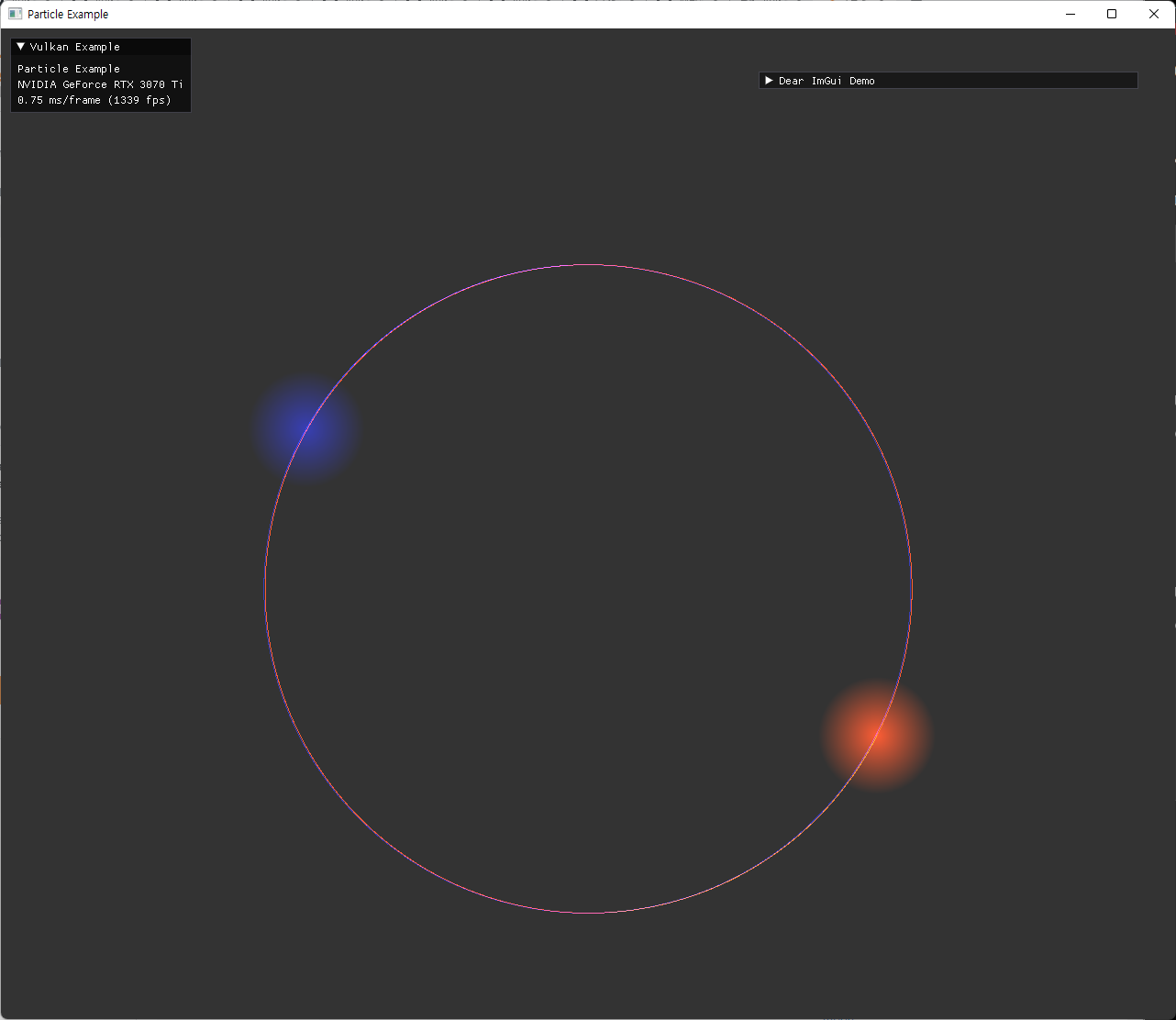 |
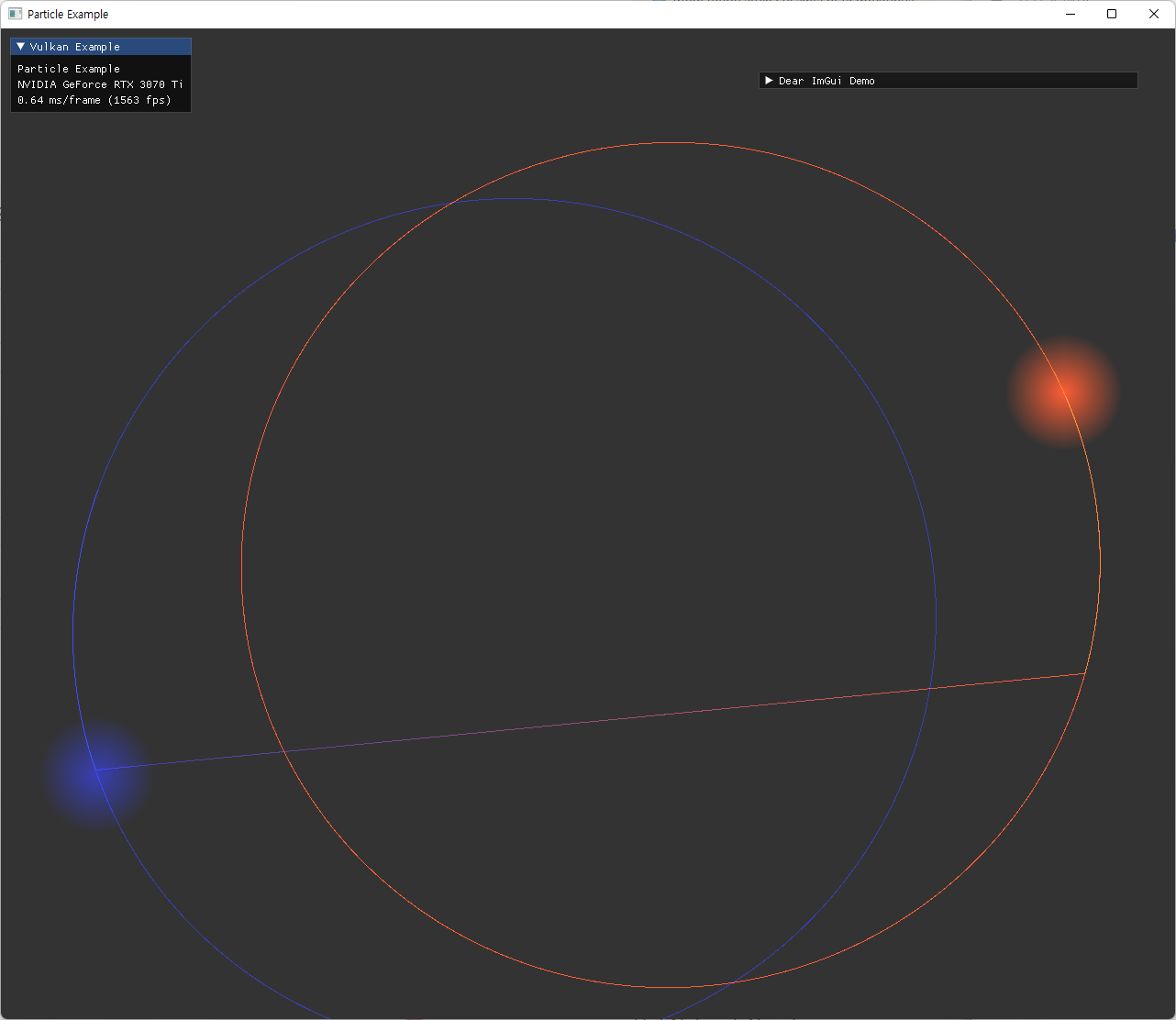
최종적으로 two-particle에 대해 예상한 것과 동일한 궤도를 확인하면서 검증을 마쳤다. |
Visualization
시각적인 효과를 위해, tail의 alpha 값을 오래된 것 일수록 작아지도록 설정했다. (fade out 기능) 이 alpha 계산도 처음에는 CPU 측에서 해주다가, 이후에는 tail vertex의 head index와 차이값을 통해 shader에서 draw 직전에 계산하도록 옮겨주었다.
또한, tail로 사용할 vertex 수와, tail을 sampling 할 시간 간격 등을 지정해줄 수 있도록 option으로 추가했다.
이 sampling 시간 간격은 0이면 매 frame update하게 되고, 그 외의 값은 seconds 단위로 update 주기에 사용된다.
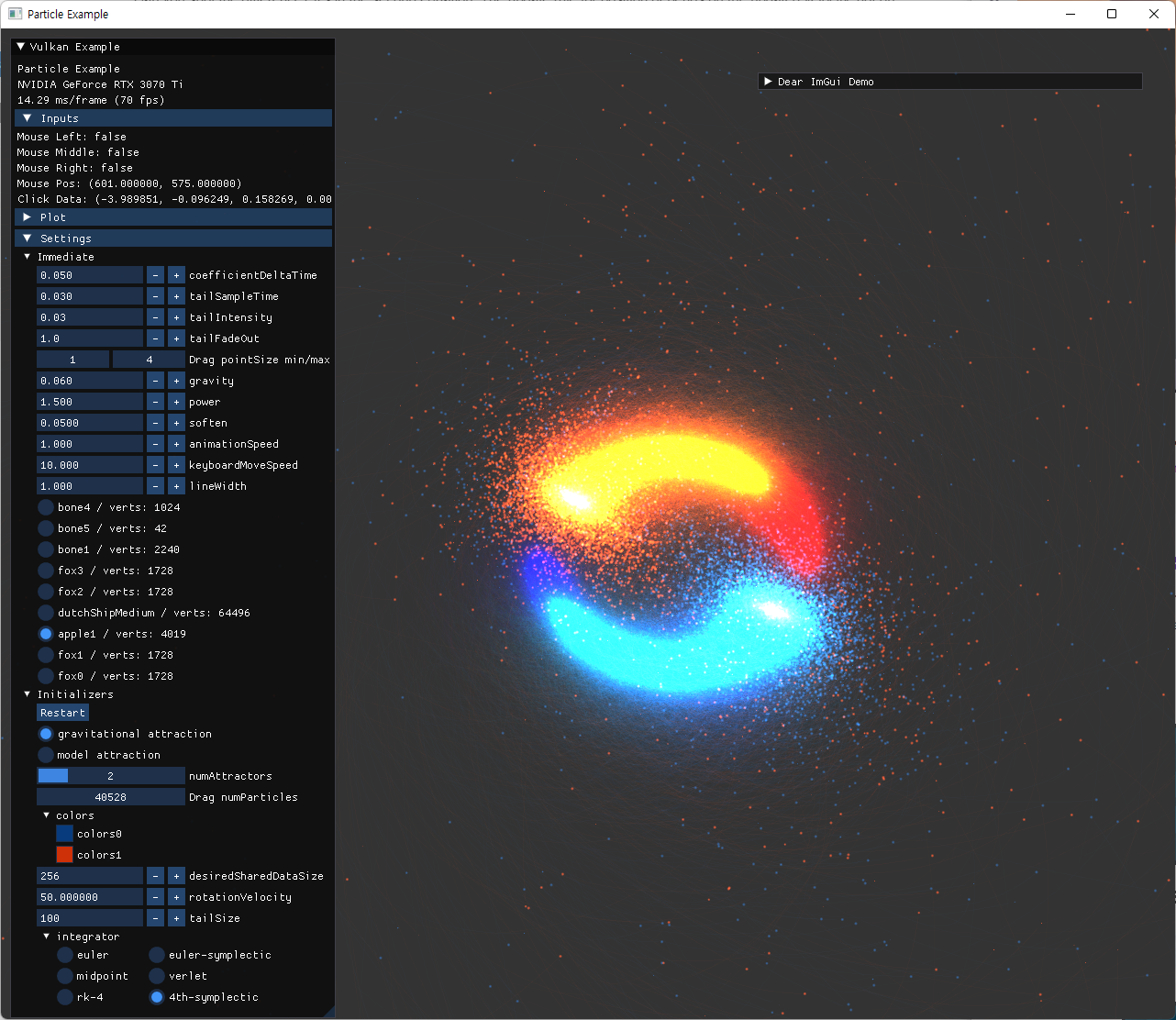
| 여러 옵션으로 실행한 결과 | |
|---|---|
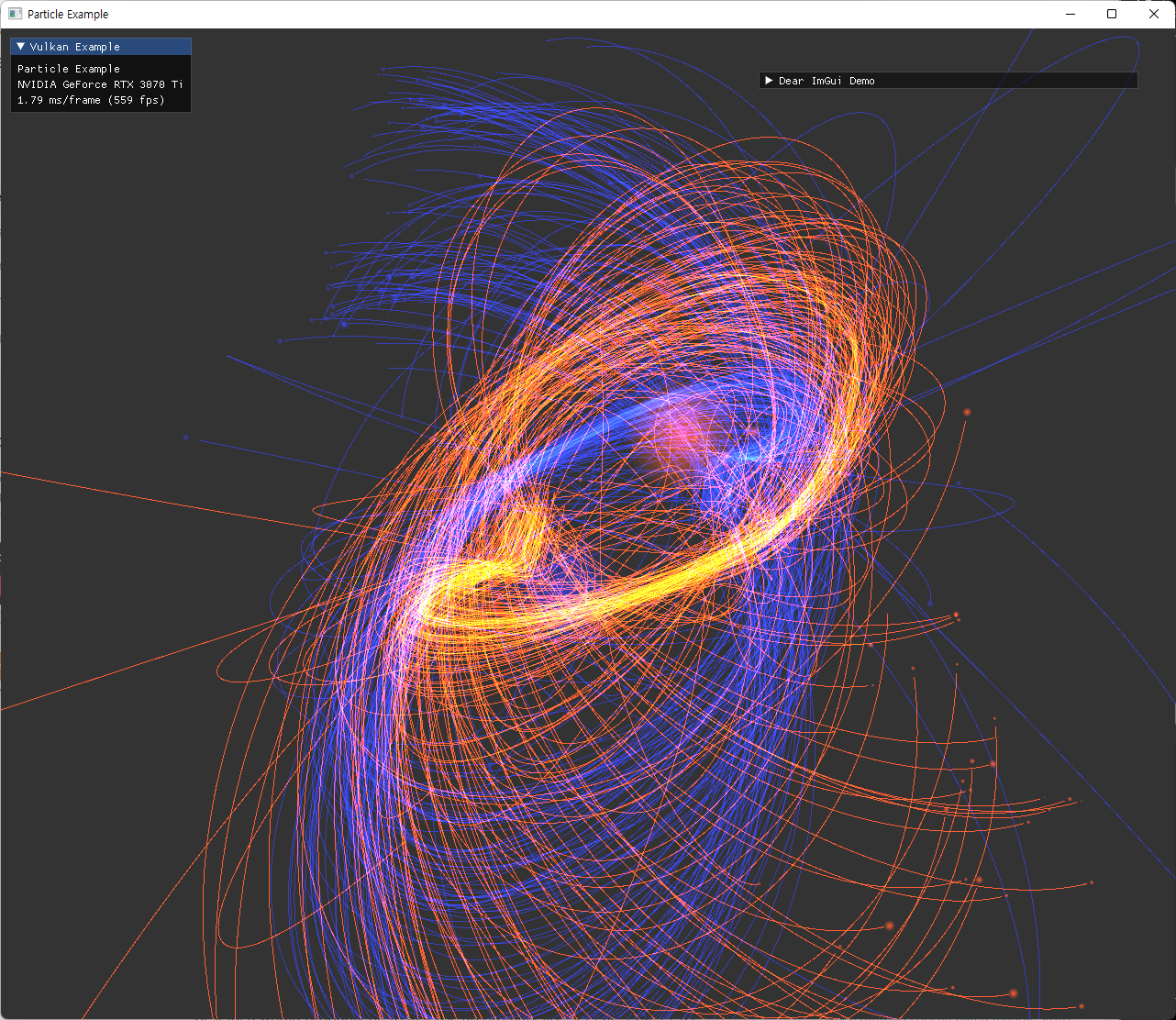 |
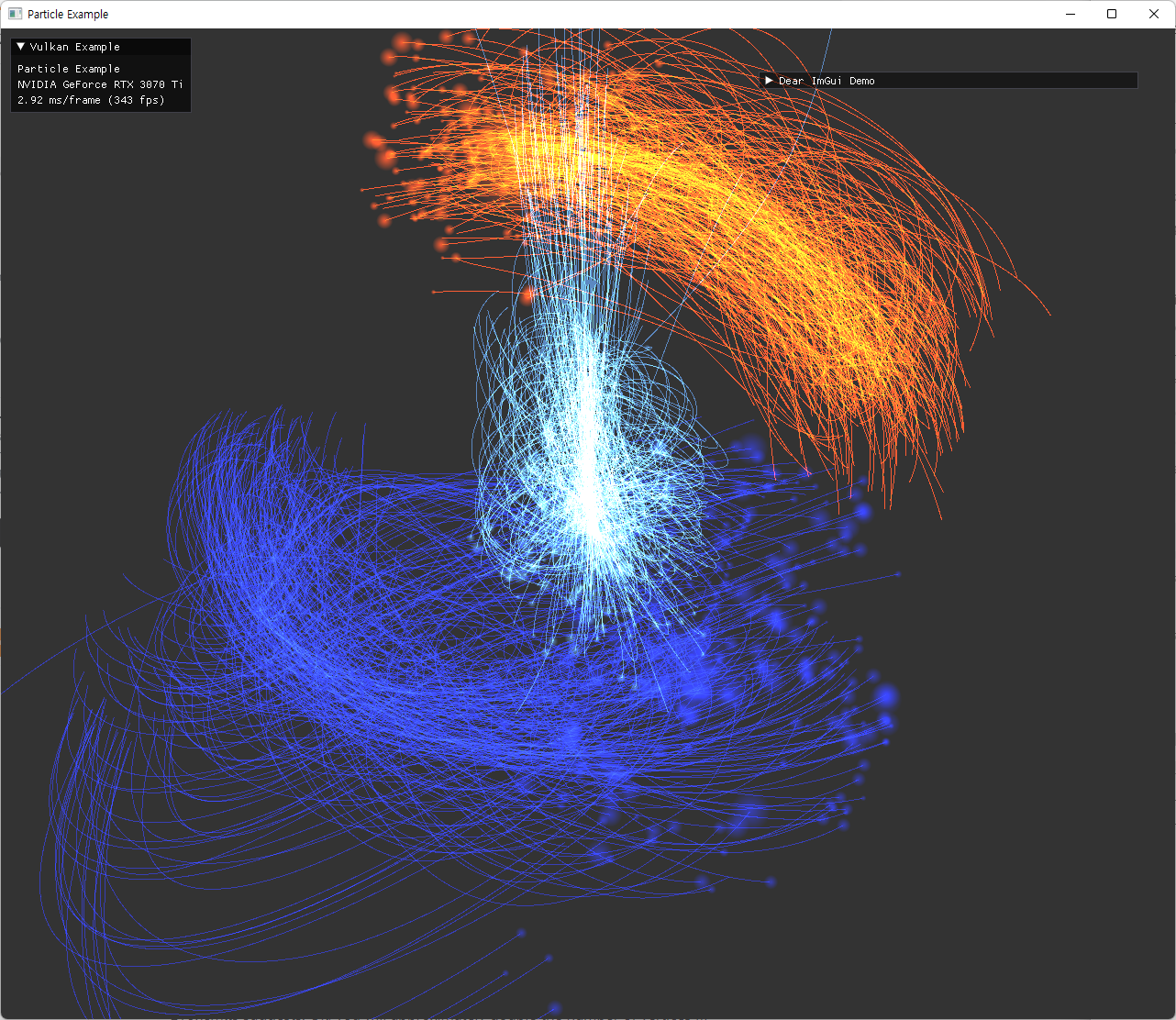 |
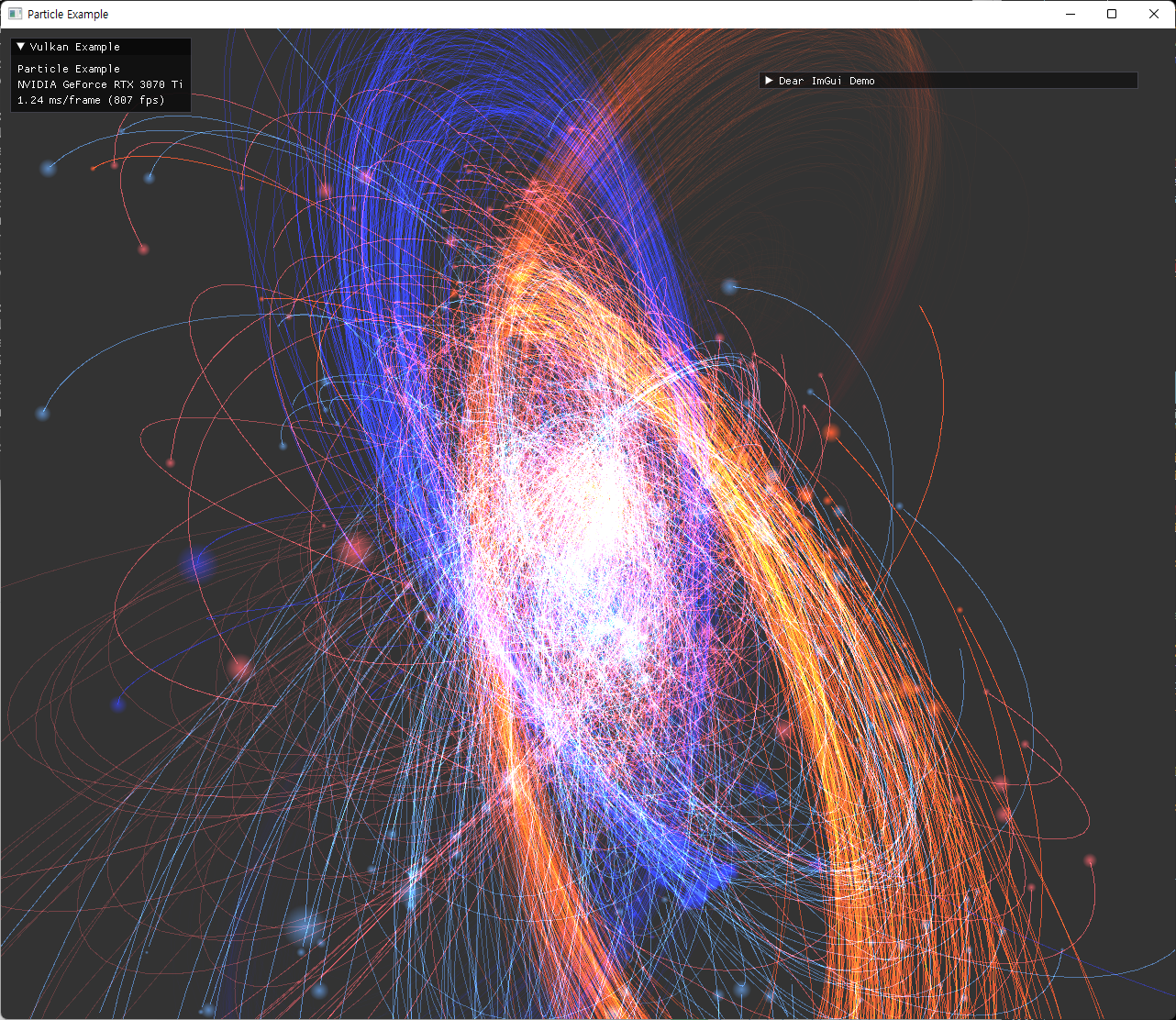 |
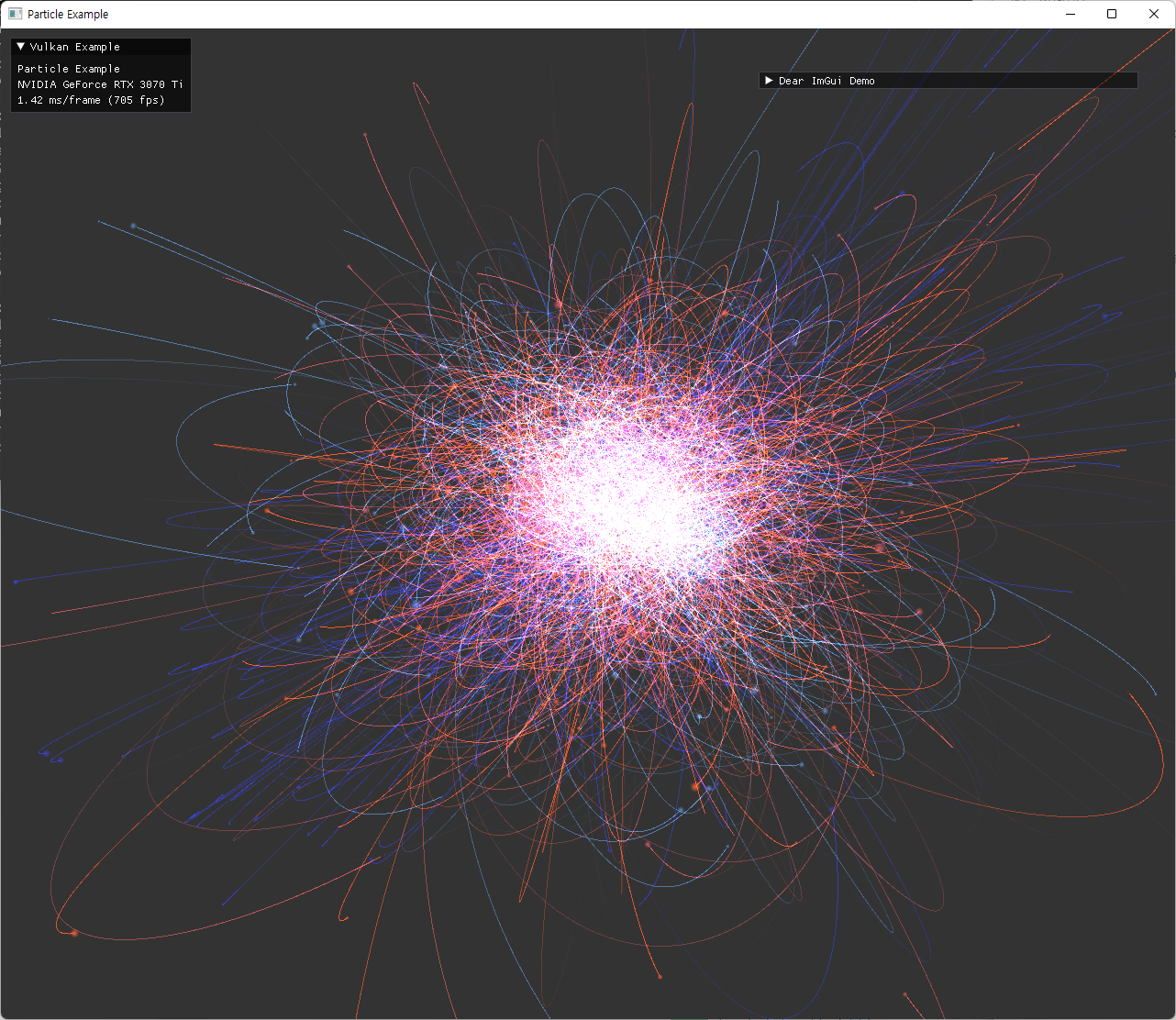 |
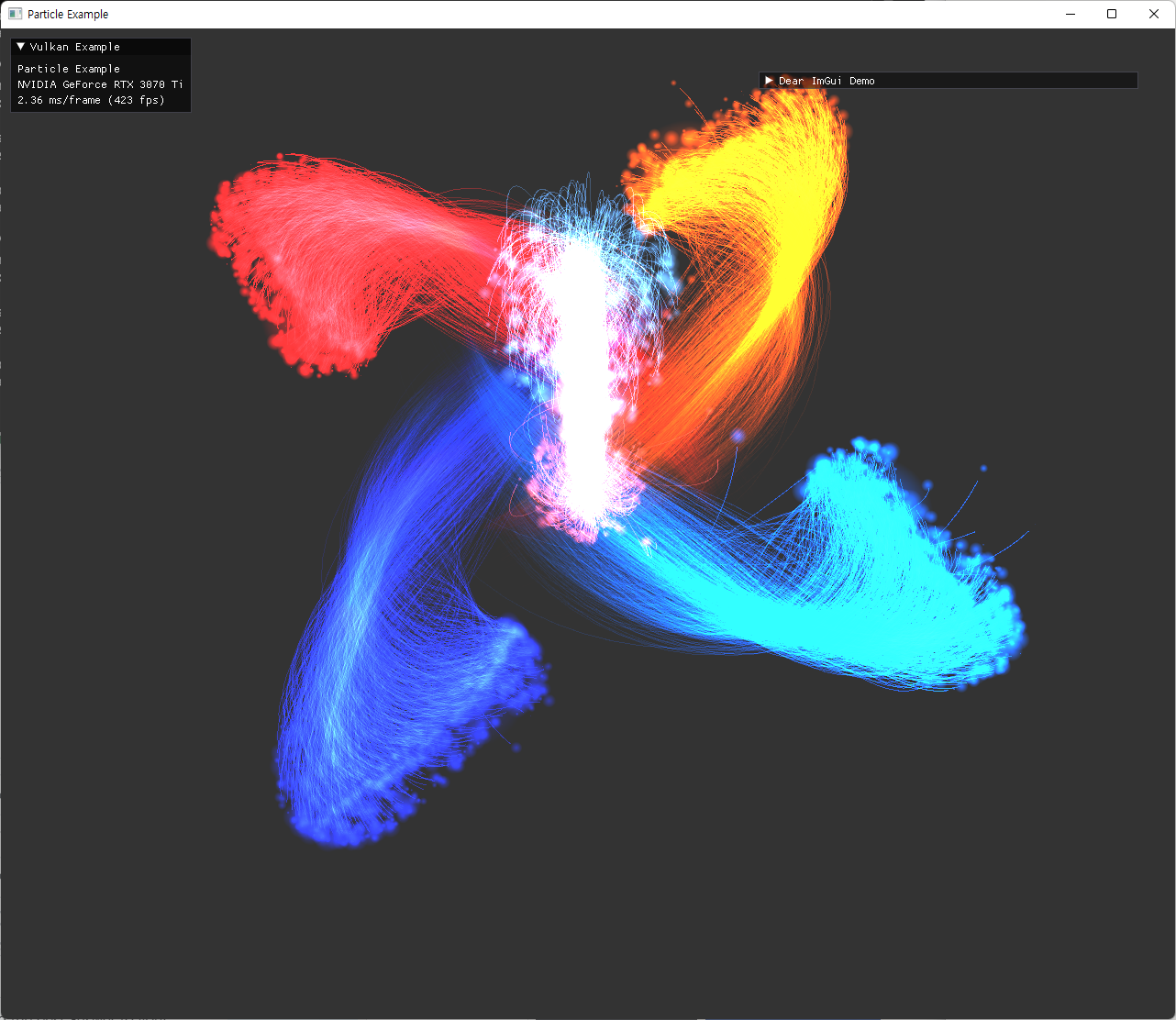 |
 |
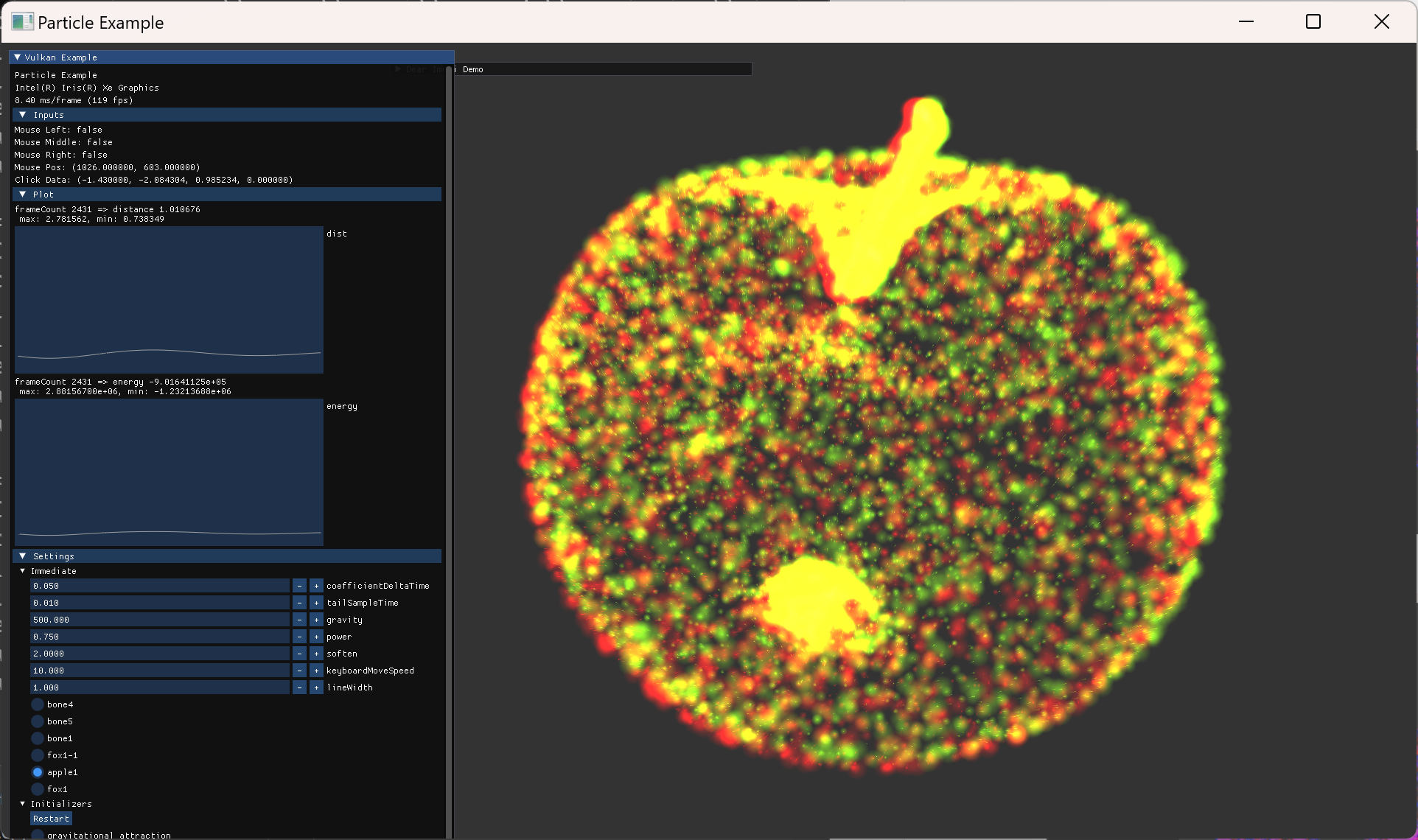
Physics and Numerical Integration
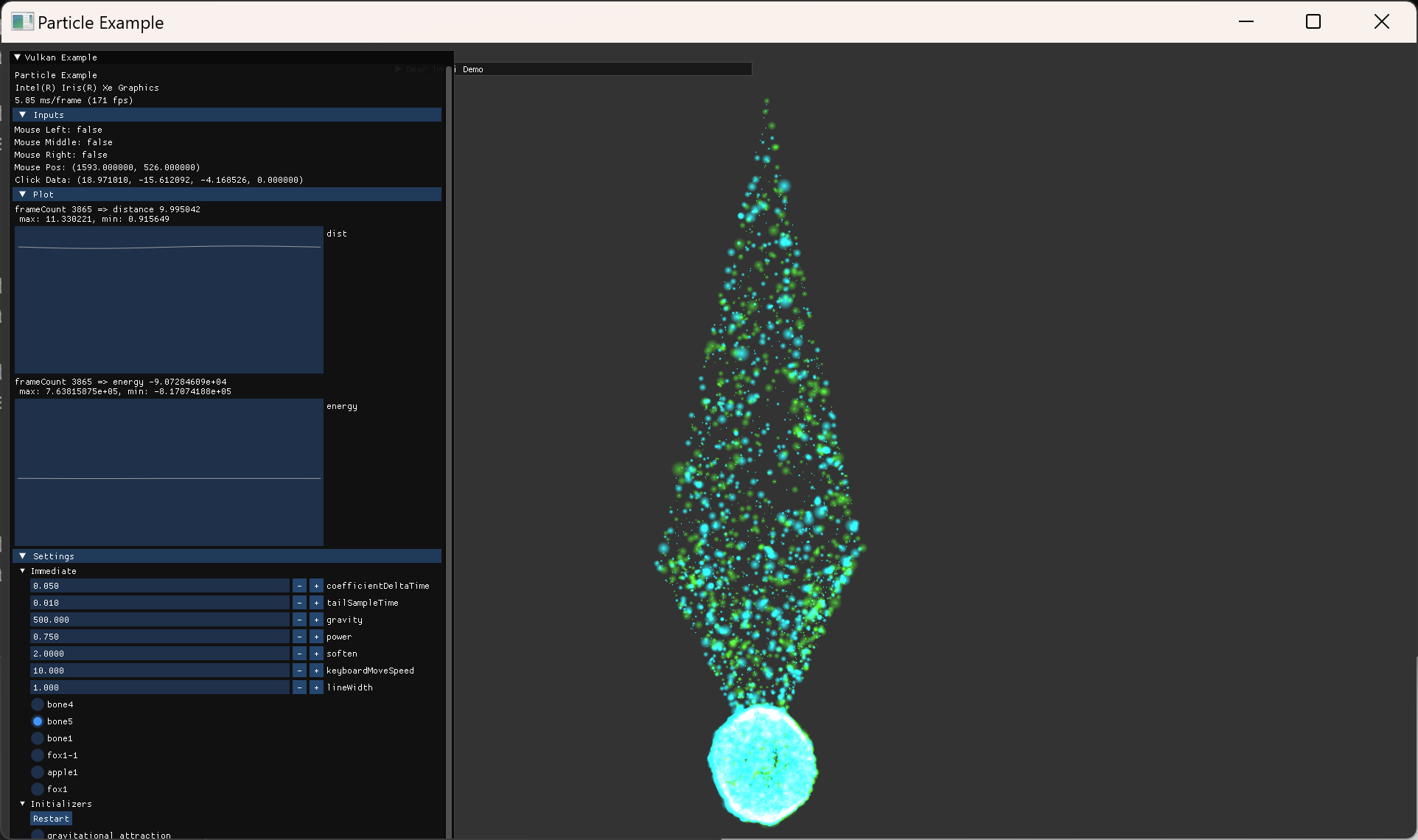
two-body simulation 결과를 가지고, integration method를 바꿔보면서 실험을 진행했다.
이를 위해 옵션 설정도 늘리고, 거리나 energy 등의 값도 plot 하도록 imGui 기능들을 추가했다.
Integration Method 비교
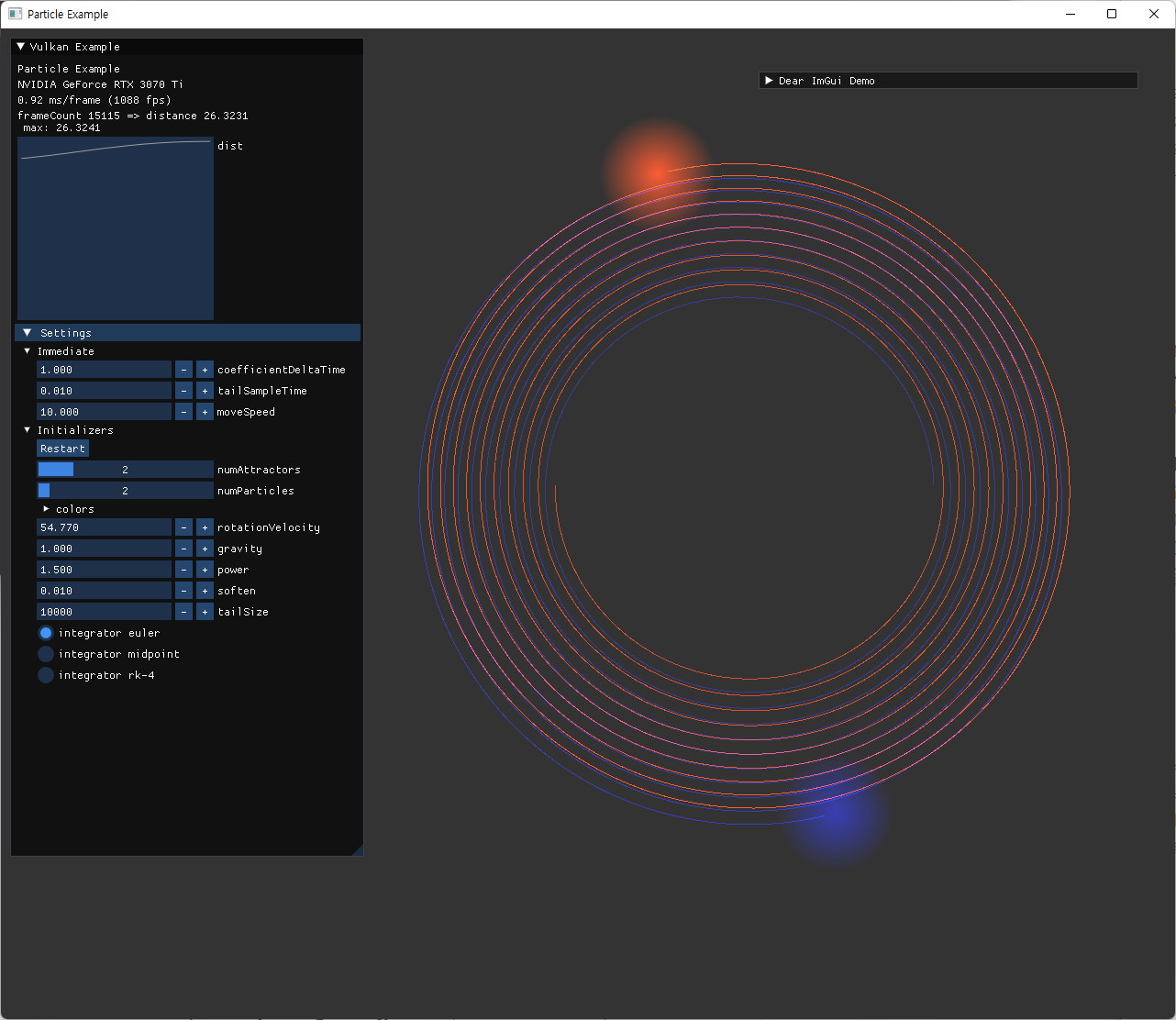
- 같은 시간 간격에서 error estimation order가 높은 방식을 사용할수록 오차가 줄어드는 것을 확인했다.
- 1차 -> 2차 -> 4차
- 같은 order라면, symplectic 방식이 장기적으로 더 안정적인 결과를 준다.
- Euler vs. simplectic Euler
- midpoint vs. Verlet
- Runge-Kutta vs. 4th-order symplectic
- 비교를 위해 시간간격 기준을 여러번 바꿔가면서 각 방식들을 실행해봤는데, 상대적으로 큰 시간간격을 사용하면 갑자기 큰 오차가 나올때도 있고, 상대적으로 작은 시간간격을 사용하면 차이가 나타나지 않을때도 있었다.
- 오차 수치들이 시간에 따라서 어떤 scale로 변하는지 등 구현과 상관관계를 보기위해서는 data를 export해서 더 자세히 분석할 필요가 있어서 어느정도 눈에 보이는 결과만 확인하고 정량적 분석은 하지 않고 넘어갔다.
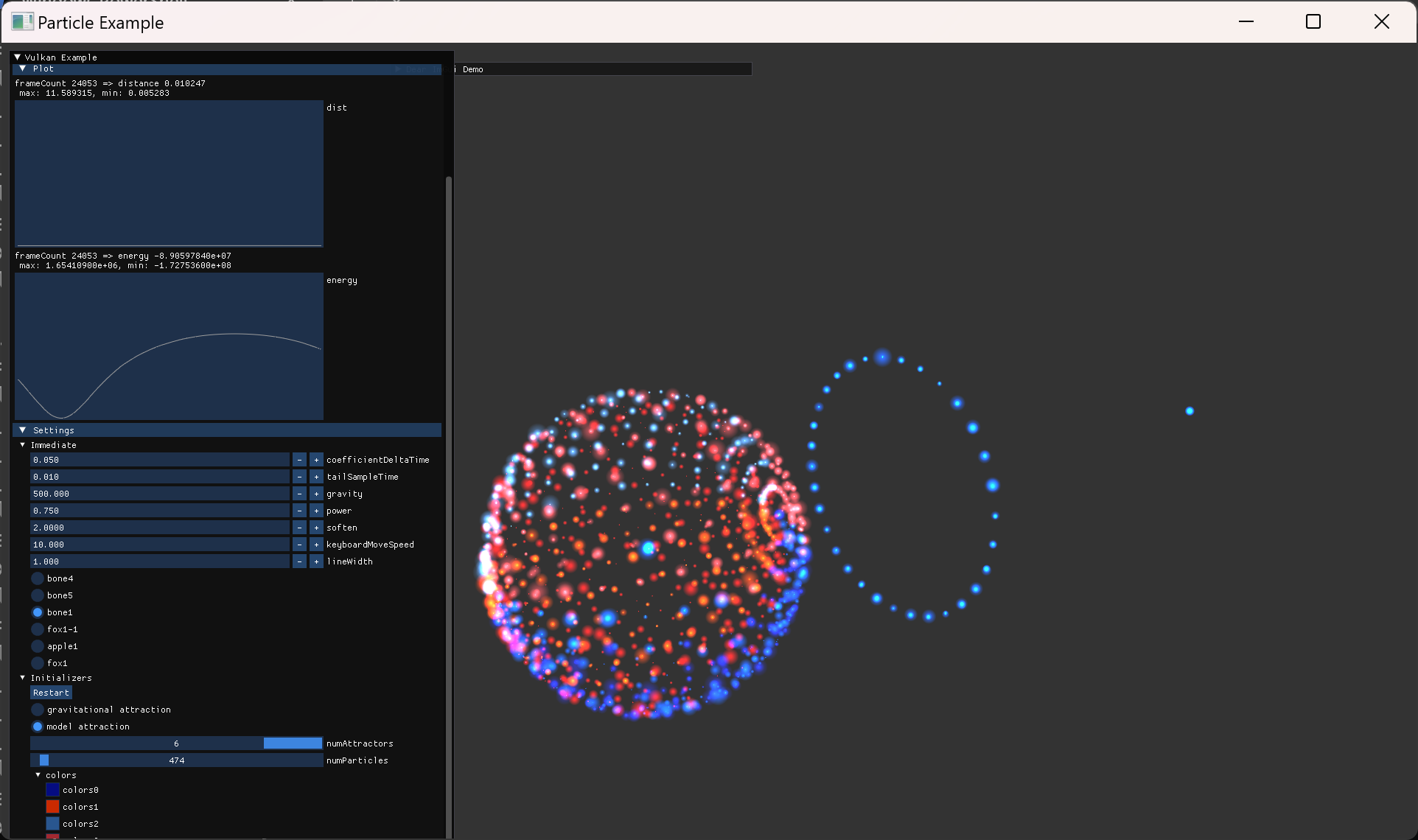
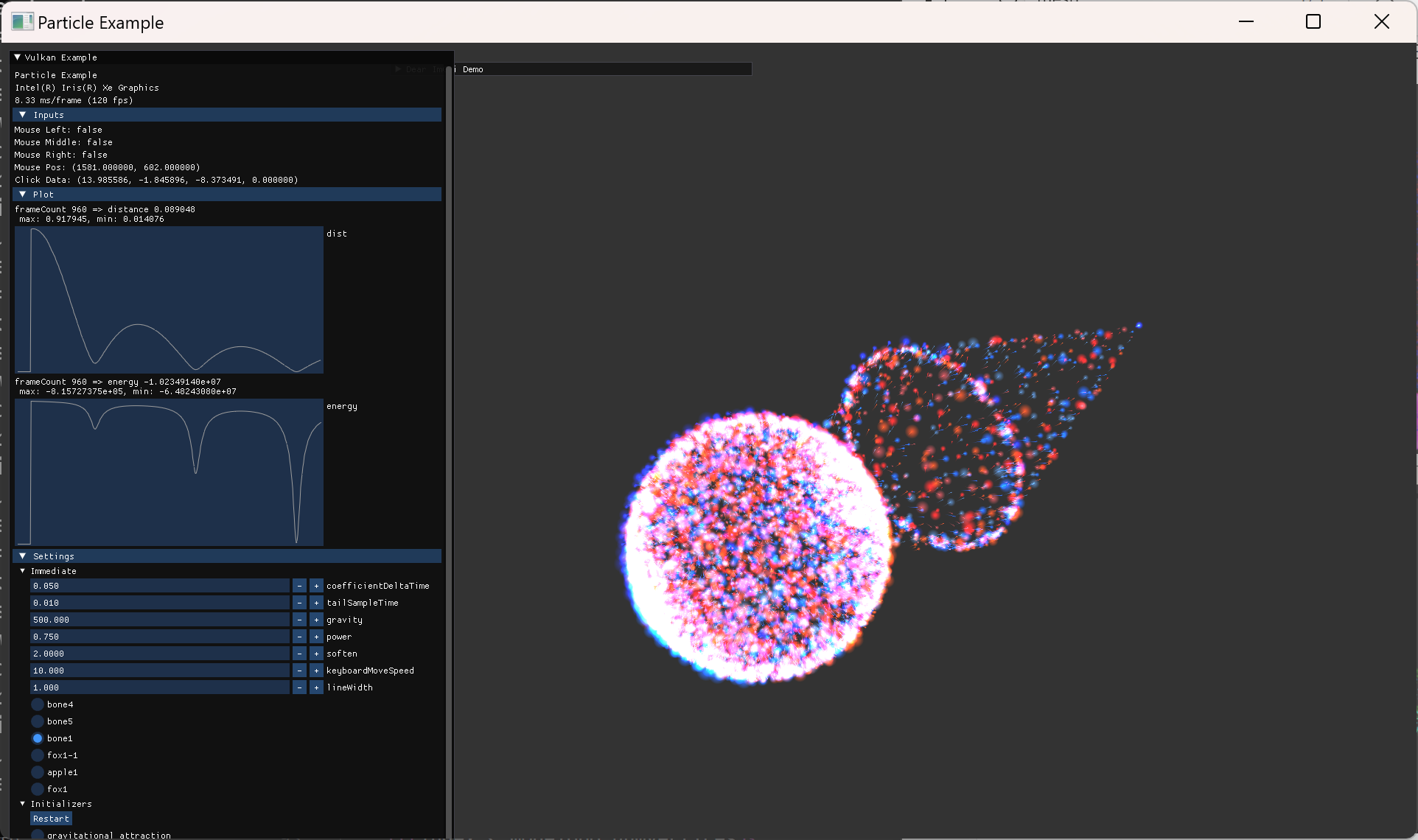
| symplectic 하지 않은 Euler method에서의 문제점 확인 | |
|---|---|
 |
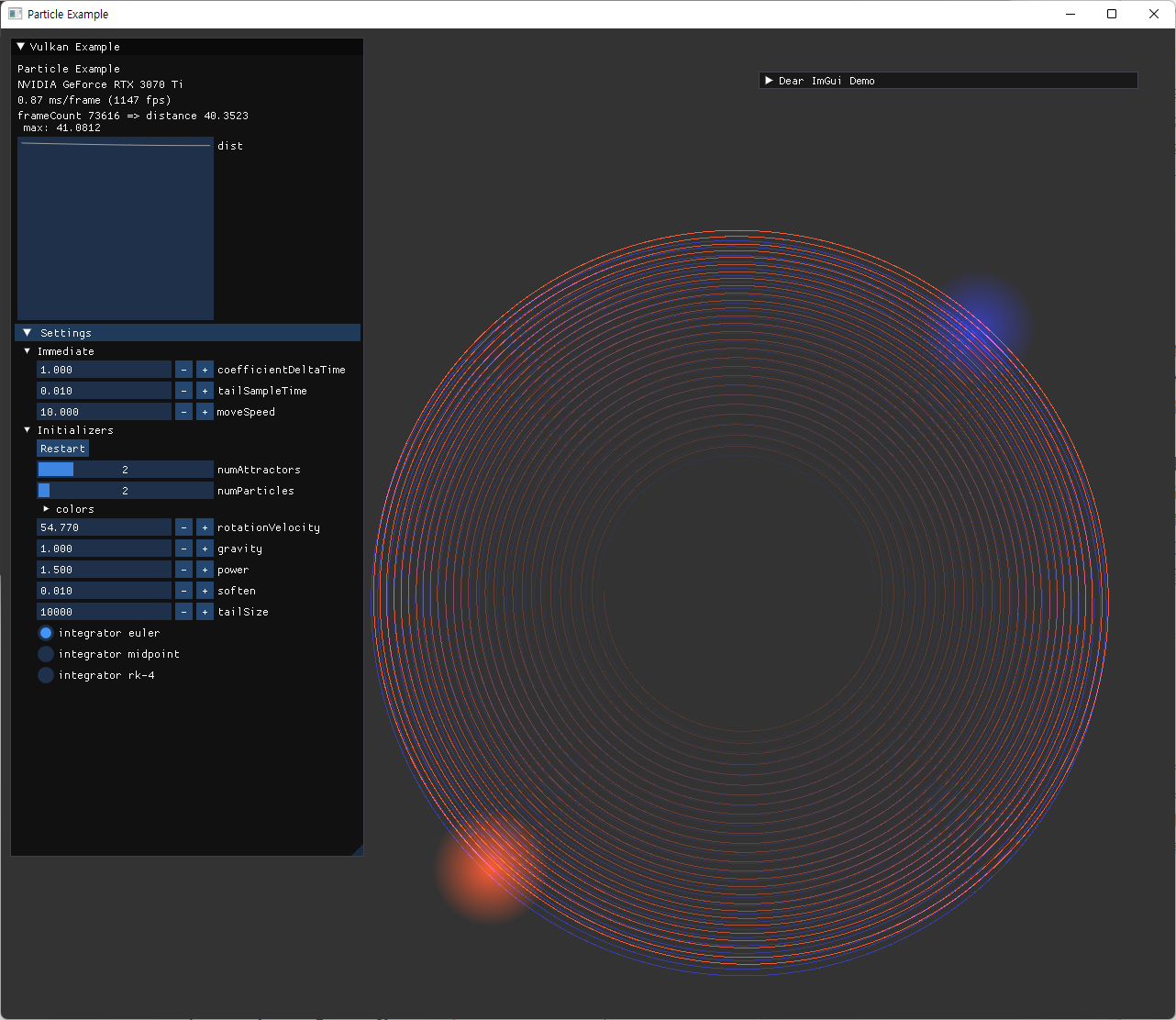 |
| symplectic 하지 않은 euler method에서 장기적으로 점점 energy가 커지는 현상. tail particle 수를 늘려서 확인함. | |
 |
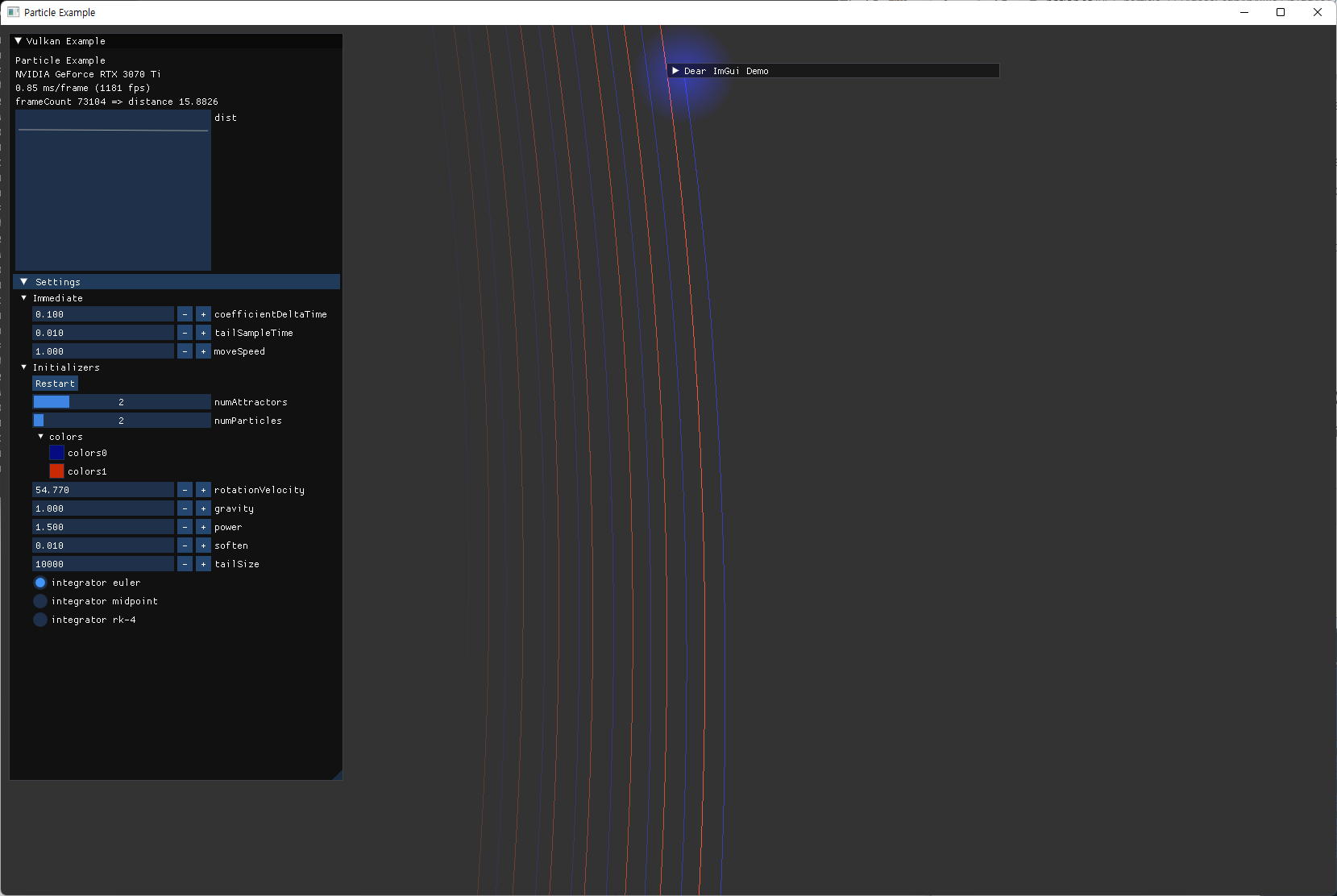 |
| 어느정도 정상적인 궤도가 나오더라도 확대해보면 멀어지고 있음 | |
높은 차수의 integrator 들을 실험한 내용은 다음과 같다.
- delta time 간격이 큰 경우에 가끔씩 큰 오차가 나타남. 정확한 원인 파악하지 못함.
- soften 을 크게하면 잘 나타나지 않음
- 다른 coefficient 설정에서도 동일한 양상이 나타남. 특히 거리가 가까워져서 속력이 큰 경우 오차가 커지는데, 이런 설정에서는 높은 order의 method가 더 정확한 계산을 해주는 것이 두드러짐.
| 큰 delta time에서 가끔 발생하는 오차 | 다른 coefficient 설정 |
|---|---|
 |
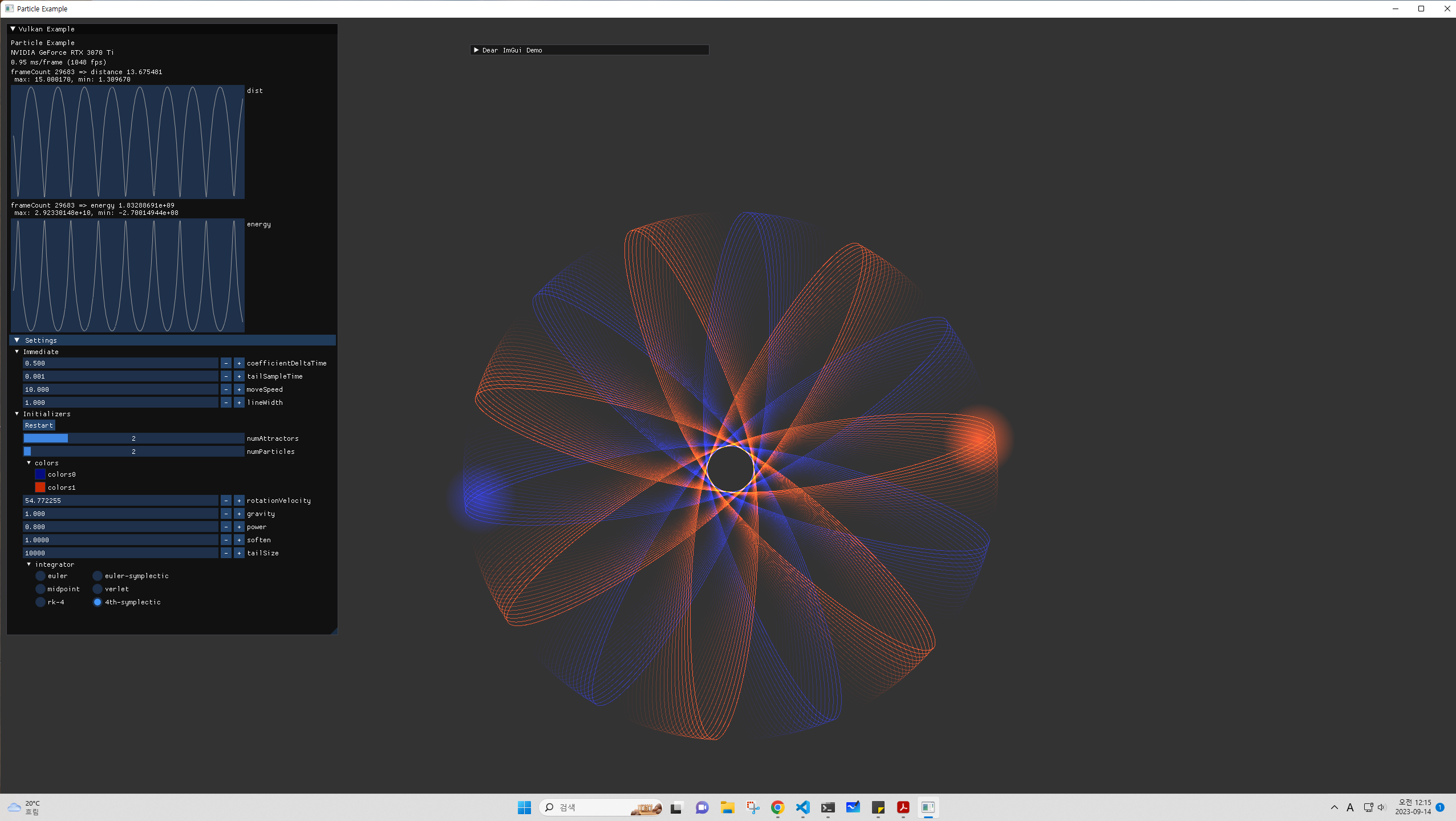 |
Mesh Attraction
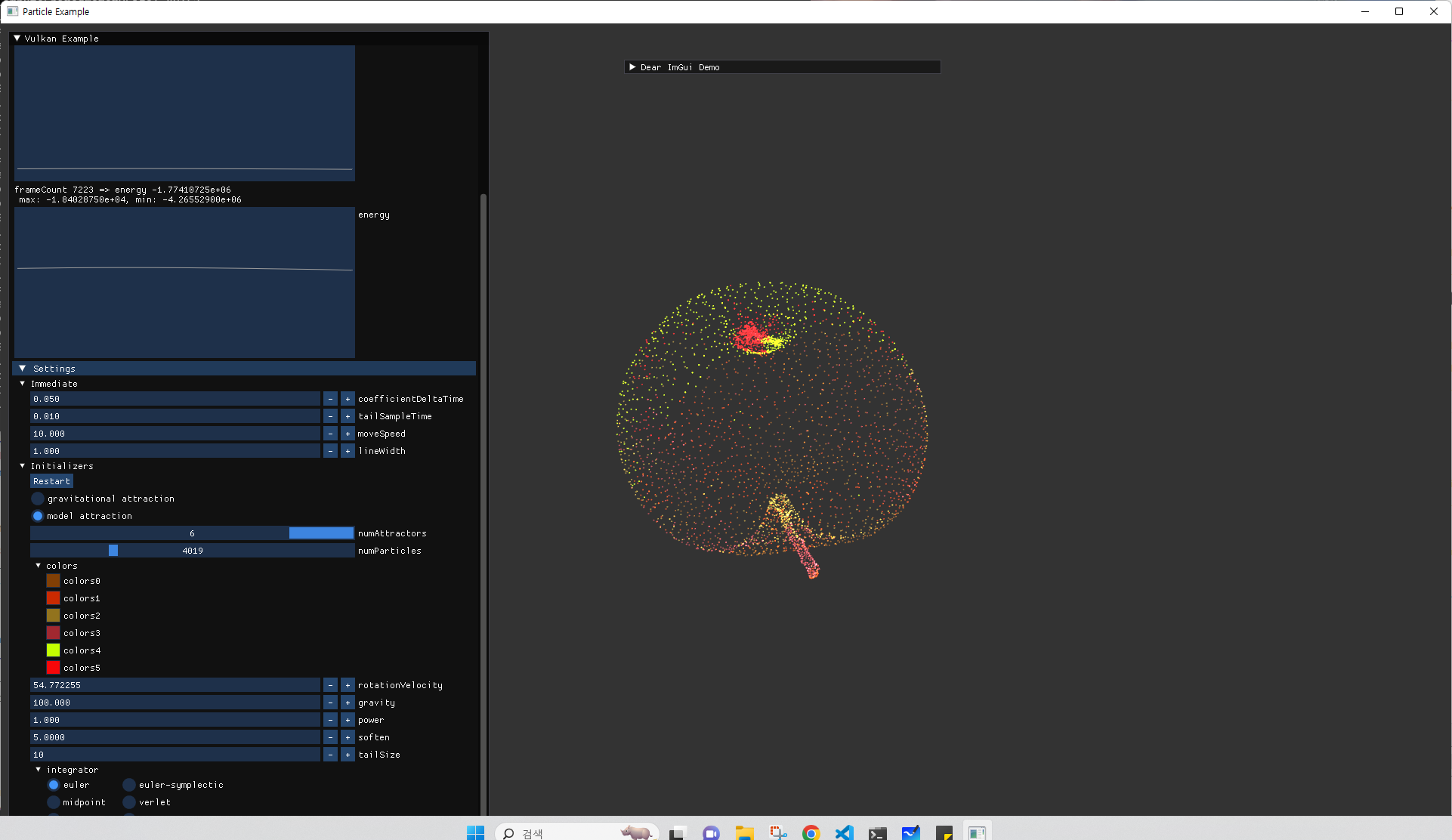
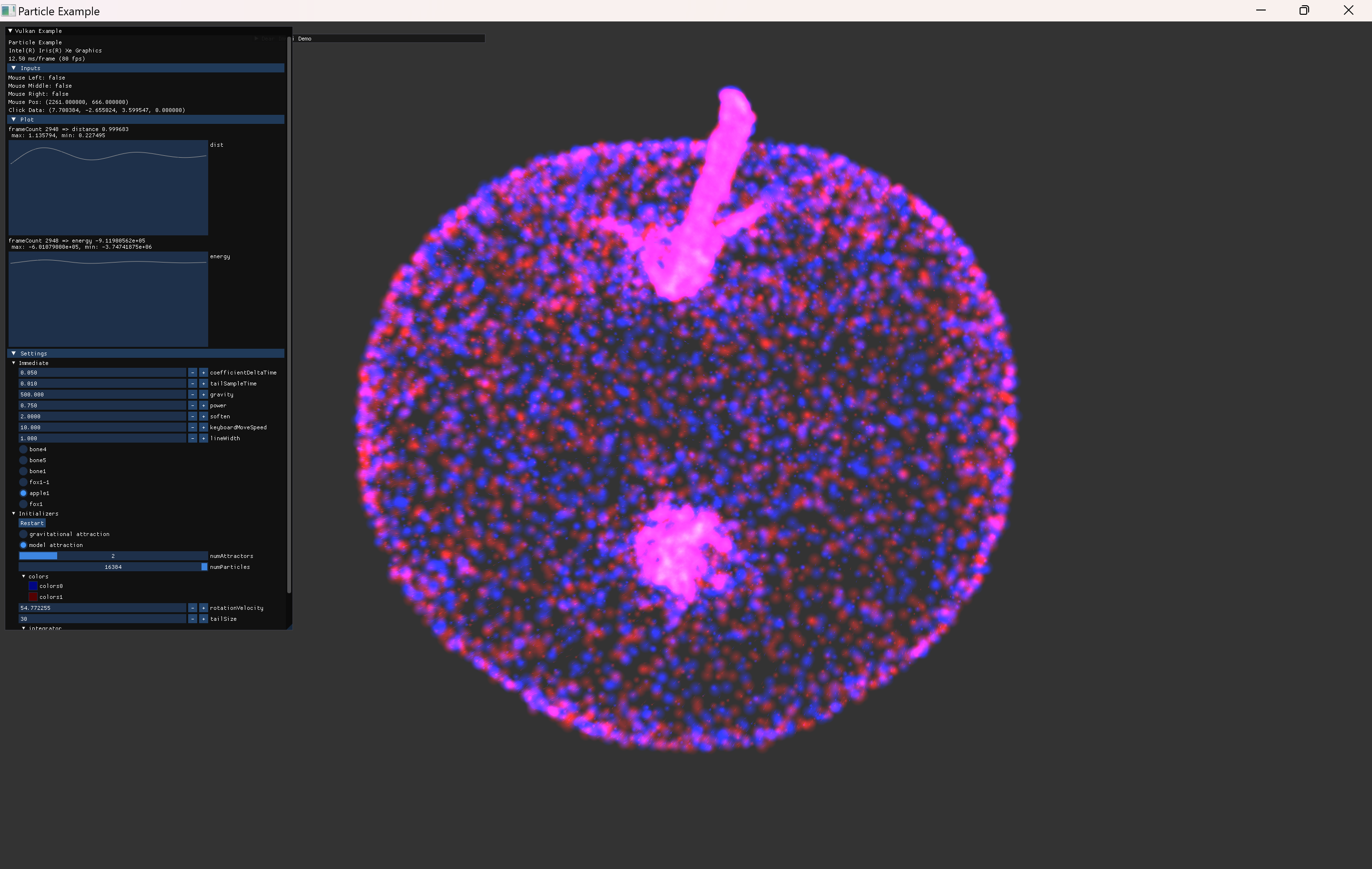
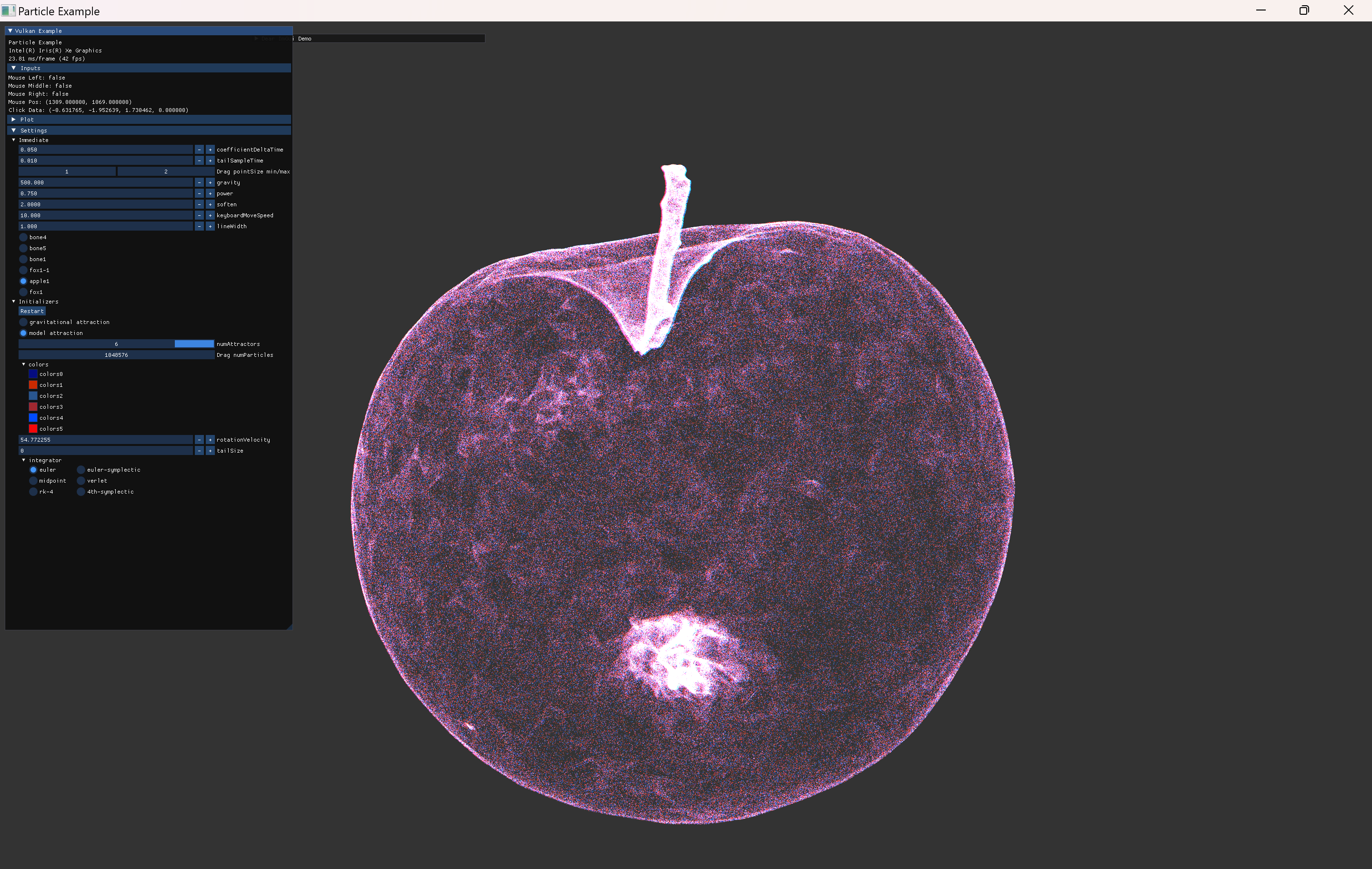
위의 이미지는 이전부터 사용하던 사과 model로 particle들을 위치시킨 것이다.
이처럼 정적인 위치에 particle을 위치시키는 것은 단순히 초기값만 사용하면 되지만, 앞으로 추가할 기능들을 위해서는 다음의 내용들을 구현해야한다.
- particle이 mesh로 attract되는 기능
- 위 이미지 처럼 model의 vertex만 사용하면 촘촘한 정도를 조정할 수 없기 때문에, mesh내부의 attract될 target position을 추가로 계산해내야 한다.
- particle이 움직이는 기능은 이전의 gravity simulation과 동일한 구조로 작성하면 되고, 하나의 target pos로 attract되기만 하면 돼서 더 간단하다.
- interaction
- 특정 위치로 particle들이 모이거나, 특정 위치를 기준으로 멀어지는 기능들은 mouse interaction으로 가능하다.
- model을 변경했을 때, 선택한 모델로 particle들이 이동하는 기능을 구현해야 한다.
- skinning과 animation
- 정지된 모델로 이동하는 것을 구현하고 나면, model instance를 옮기거나, model의 animation된 vertice들로 attract 되는 기능을 추가한다.
- 이를 위해서는 미리 compute shader를 활용해서 계산된 animated model vertices를 저장하고 있어야 한다.
- tail optimization
- \(O(n^2)\) 연산이 필요 없으므로 vertex수가 이전보다 훨씬 많을 수 있는데, 이를 반영했을 때 이전과 같은 방식의 trajectory 기능을 사용하면 너무 느려진다.
- trajectory 관련 구현인 tail의 내용을 GPU 계산으로 옮겨서 연산 속도를 높이자.
Interaction
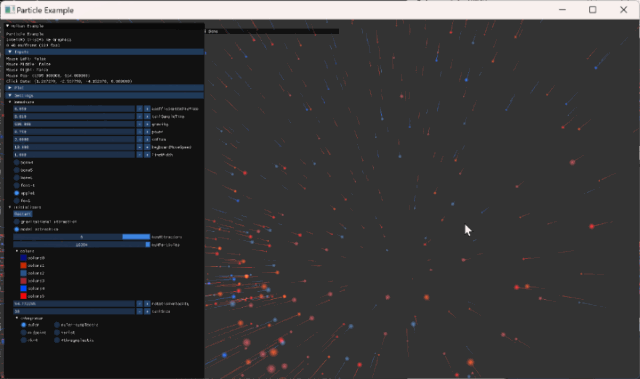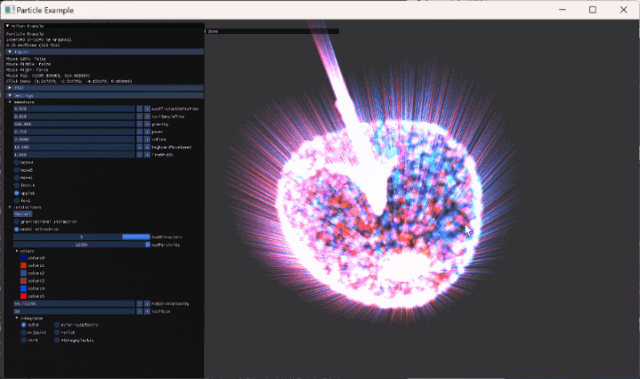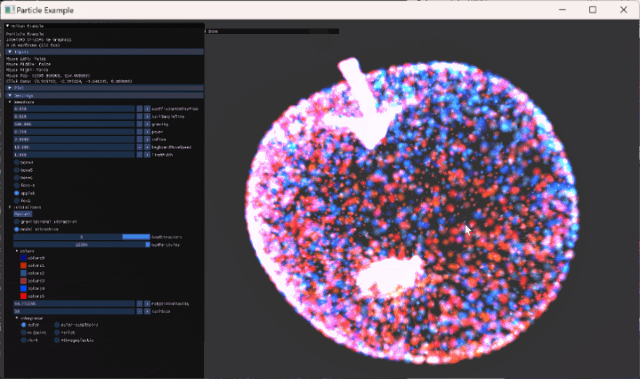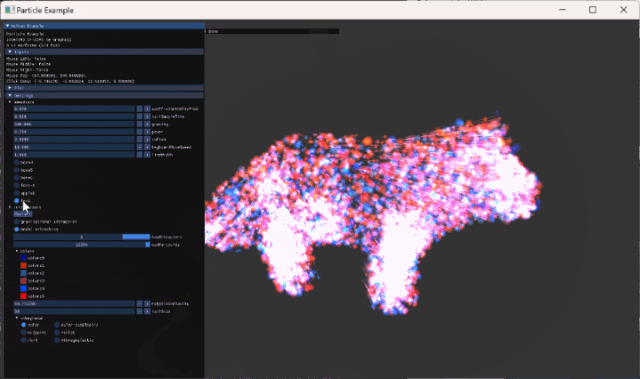
크게 두 가지 interaction을 추가했다.
- imGui option에서 model 변경
- 모델은 모두 시작 시 load 해 놓고, option에서 선택한 model instance를 bind하는 기능만 추가하면 된다.
- mouse click
- glfw의 mouse input을 사용했다.
- left: 해당 position으로 모든 vertices가 끌리도록 구현
- right: 해당 position의 반대 방향으로 밀려나가도록 구현
- middle: vertices들이 초기위치로 이동하도록 구현
Ray-Casting
mouse left와 right 기능을 위해서는 click된 위치를 world space로 mapping 해줘야 한다.
개념적인 부분은 해당 opengl-tutorial을 참고했다.
구현된 기능들을 살펴보면, commits
- mouse position을 normalize해서
normalizedMousePos를 계산한다. - 이 값을 사용해서, ray의 방향과 시작/끝 점을 구한다.
-
rayPlaneIntersection()함수를 통해, ray와 (camera의 view 방향을 normal로 하고 원점을 지나는 평면) 사이의 교점을 구한다. - 해당 지점을
clickPos로 사용해서 compute UBO에 전달한다.- 이때, w값을 click의 종류로 지정해줬다.
- compute shader에서 이
clickData를 사용해 지정된 attraction/repulsion 을 가속도에 반영한다.
Triangle Uniform Distribution
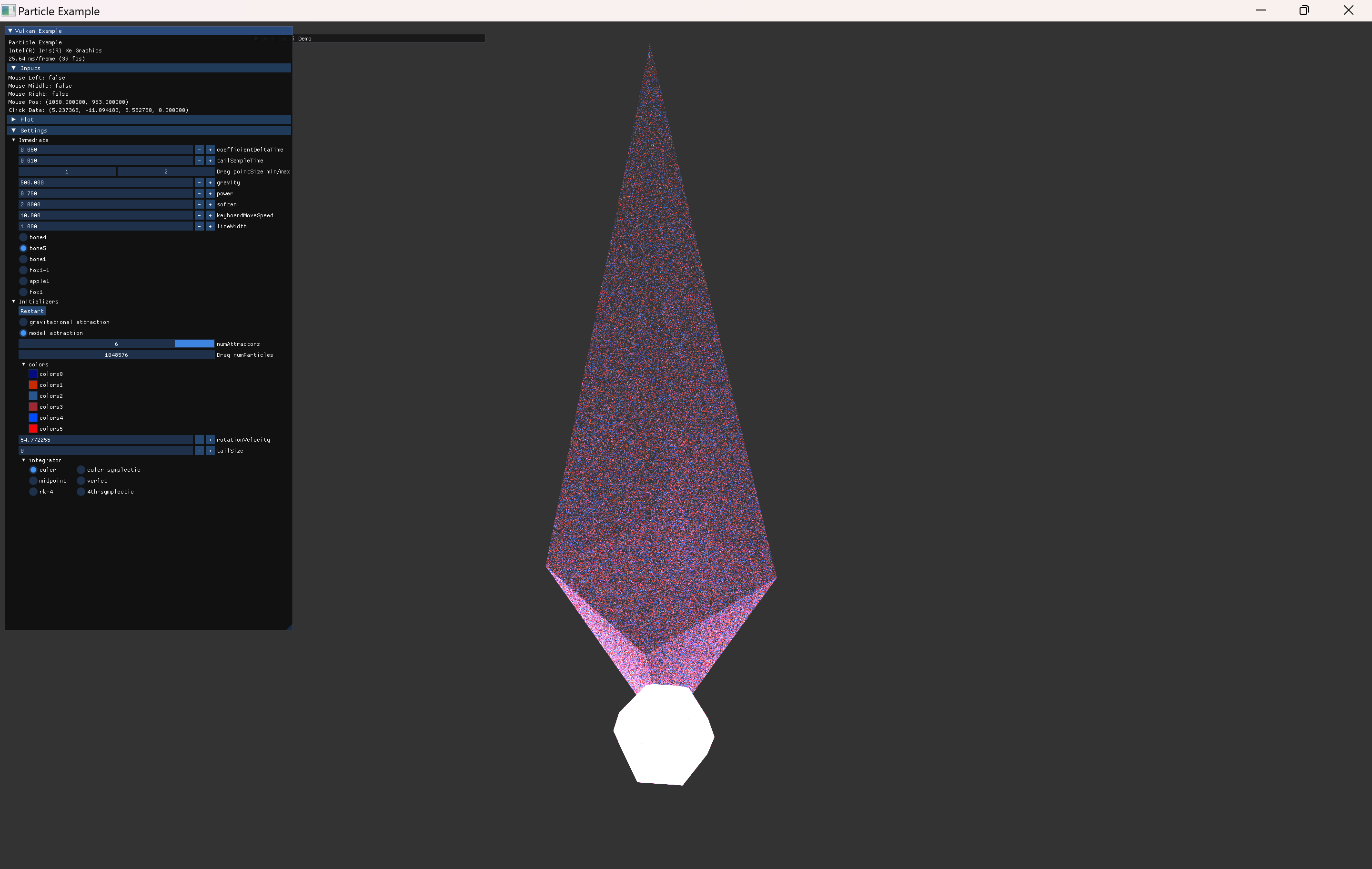
위에서 정리한대로 삼각형 내부의 uniform한 distributon을 따르는 random한 point로 particle의 target을 추가해줬다.
- 전달해줄 data는 이 random weight 밖에 없다.
- shader에서 index를 그대로 model의 vertices로 mapping 했기 때문인데 shader에서 target position을 계산하는 방식을 보면 다음과 같다.
-
vec3 targetPos; if(index < modelUbo.numVertices){ targetPos = vertices[index].pos.xyz; }else{ uint modIndex = uint(mod(index-modelUbo.numVertices, modelUbo.numIndices/3)); vec3 p0 = vertices[indices[modIndex*3]].pos.xyz; vec3 p1 = vertices[indices[modIndex*3+1]].pos.xyz; vec3 p2 = vertices[indices[modIndex*3+2]].pos.xyz; // center of triangle vec4 attractionWeight = particlesIn[index].attractionWeight; targetPos = p0 + attractionWeight.x * (p1-p0) + attractionWeight.y * (p2-p0); } targetPos = (modelUbo.modelMatrix * vec4(targetPos, 1.0)).xyz;- particle의 index가 model의 vertices 수보다 작을때는 mesh 내부 점을 사용하지 않는다.
- particle이 남는 경우는, 그 남는 index를 3개씩 묶어서 삼각형 하나씩을 찾는다.
- 그 삼각형을 기준으로 전달한 random weight에 따라 삼각형 내부의 위치를 계산한다.
- 위 방식에 의해, particle 수가 많으면 많을 수록 더 촘촘하게 model에 mapping 된 형상을 볼수 있게 된다.
- 이 방식은 후에 추가할 animation in compute shader도 고려한 방식이다.
- target vertex의 위치를 미리 지정해놓는게 아니라, index를 통해 vertex를 찾고 그 vertex위치를 기반으로 내부의 점을 계산한다.
- 이 vertices 대신 animated vertices가 들어가기만 하면 animation된 mesh의 내부 좌표가 target으로 설정될 것이다.
예시 command
.\particle.exe --np 4019 --na 6 -g 500.0 -p 0.75 -s 5.0 --tst 0.01 --ts 10 --width 1920
 |
 |
- |
 |
 |
- |
 |
 |
 |
 |
 |
 |
Skinning in Compute Shader
Recap: Mesh and Skin
- node가 mesh를 소유하고, skin을 참조한다.
- mesh의 primitives에 vertex, joint index, weight 등의 정보가 들어있고, 실제 데이터는 vertex buffer에 들어있다.
- skin은 여러 joint node를 참조한다.
- skinning의 정보가 mesh UBO에 들어있다.
- 기존의 구조는 node 단위로 bind 하고 draw하기에 가능한 구조.
- node가 skinned mesh를 가지는 경우는 skinIndex값이 해당되는 skin의 index를 가르키고, 아닌 경우는 -1 값이다.
- mesh가 여러 node에 나눠져 있고, skin 없이 node hierarchy만 사용하는 모델에 대한 구현은 아직 미구현이다.
- animation update는 CPU에서 joint node의 matrix를 변경해준다.
Implementation
이전 구현 상태에서 변경해줄 사항들이다.
- glTF 모듈의 vertex/index buffer를 shader storage usage도 가능하게 한다.
- 이 값은 여러 animation 상태에 따라서 입력으로 재사용되어야 한다. 이를위해 glTF model class에서 descriptorSet bind 기능을 외부로 노출해야 한다.
- 그리고 이 vertex가 어떤 skin을 사용하는지에 대한 정보는 compute shader에서 알 수 없으므로, attribute에 skinIndex를 추가해준다.
- 또한 이 buffer 외에, out
animatedVertexBuffer와 그에따른 descriptorSet이 필요하고, frames-in-flight를 고려해서 자원을 할당해야 한다.
- node 단위의 joint matrices UBO정보를 한번에 bind할 수 있어야한다.
- compute shader에서 skinning을 계산하기 위해서는, node 단위로 draw하지 않고, work group size로 dispatch한 결과를
animatedVertexBuffer에 저장해야하기 때문이다. - glTF model class에서 이 모든 skin의 jointMatrices data를 외부로 반환하는 기능을 추가해야 한다.
- 그리고 이 data는
skinMatricesBuffers와skinDescriptorSet를 통해 SSBO로 binding 되어야 한다.
- compute shader에서 skinning을 계산하기 위해서는, node 단위로 draw하지 않고, work group size로 dispatch한 결과를
- 구현 과정에서, memory layout 관련 오류가 발생해서 정리하면서 참고했던 내용이다.
- 계획
- model vertex attribute에 skinIndex 추가 및 저장
- 구현할 때는 따로 추가하지 않고, position의 w 값을 이용했다.
- vertex의 descriptorSet 추가
- 기존 vertex buffer는 그대로 사용하고 usage만 추가하면됨
- read only로 사용할 것이므로, 기존 자원 구조 변경이 필요없음
- mesh face attraction
- 이 부분은 미리 고려해서 구현했기 때문에 추가할 내용은 없음.
- skin SSBO 생성
- animation update를 매 frame하는 경우, 이 skin SSBO도 매 frame update 되어야하므로, frames-in-flight 수 만큼 생성한다.
- 이 SSBO에는 모든 model instance의 모든 skinMatricesData가 저장된다.
- 주기적인 update가 필요하고, 크기가 비교적 크지 않으므로, host-coherent한 타입의 buffer로 생성했다.
- animated vertex buffer 생성
- 위 skin SSBO와 같은 이유로 같은 크기로 생성한다.
- 각 model instance의 vertexCount 만큼의 크기가 되도록 생성하고, type은 GPU dedicated로 생성한다.
- animated vertex data에는 pos, normal, tangent attribute가 모두 고려되어야 한다.
- compute shader에 필요한 데이터 binding
- model vertices는 model class에서 구현한 bind 함수를 사용해서 bind한다.
- skin SSBO와 animated vertexs SSBO는 하나의 set에 다른 binding으로 지정해서 bind한다.
- compute shader 구현
- 기존 vertex shader에서 하던 skinning 계산을 compute shader로 작성한다.
- skinIndex가 -1인 경우는 아무런 연산을 하지 않는다.
- pipeline 구성 및 command buffer recording
- 기존 compute pipeline들과 유사한 방식으로 생성하고,
step-1이전에 recording 하고 실행이 완료되도록 pipeline barrier도 설정해준다.
- 기존 compute pipeline들과 유사한 방식으로 생성하고,
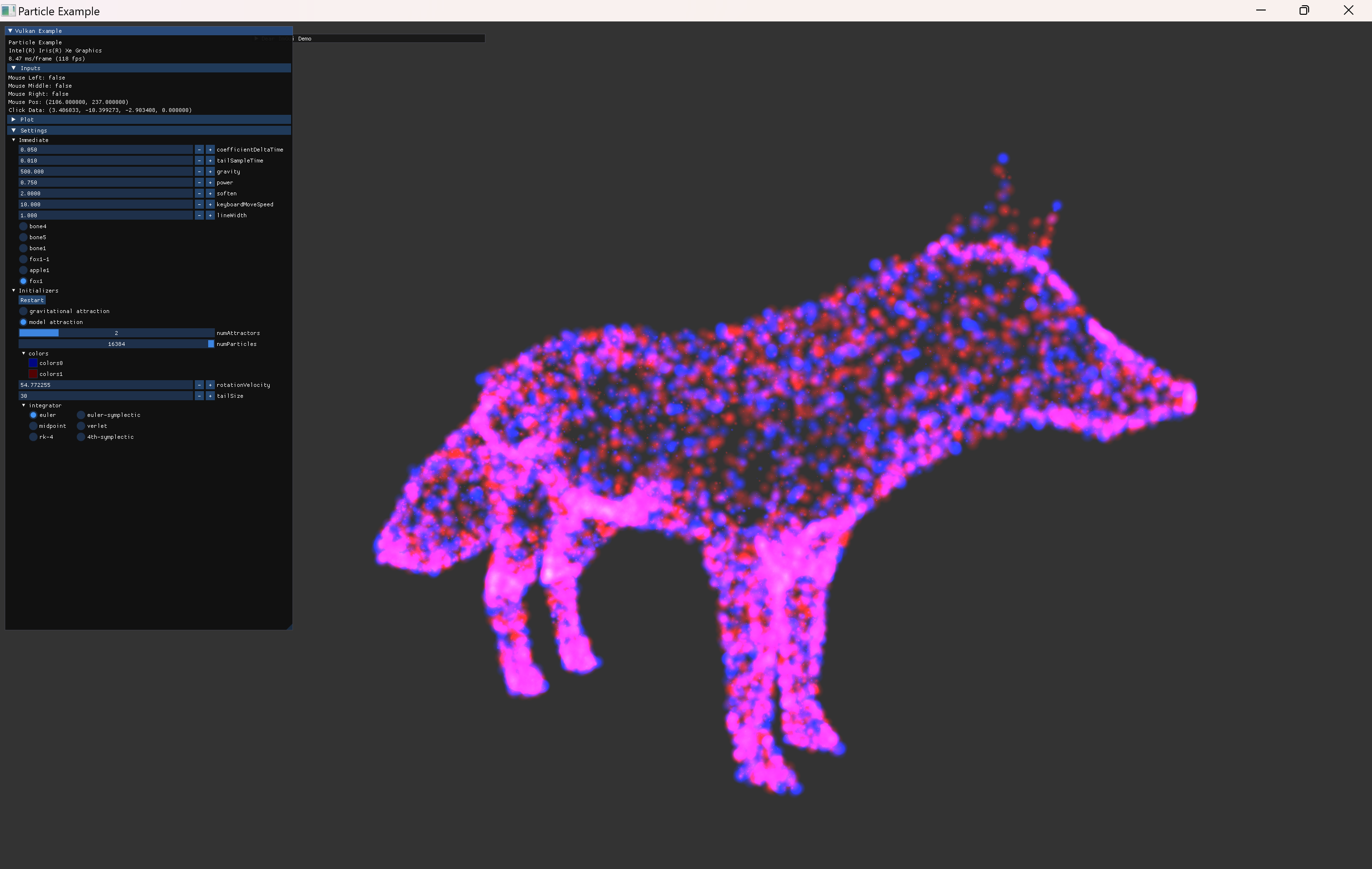
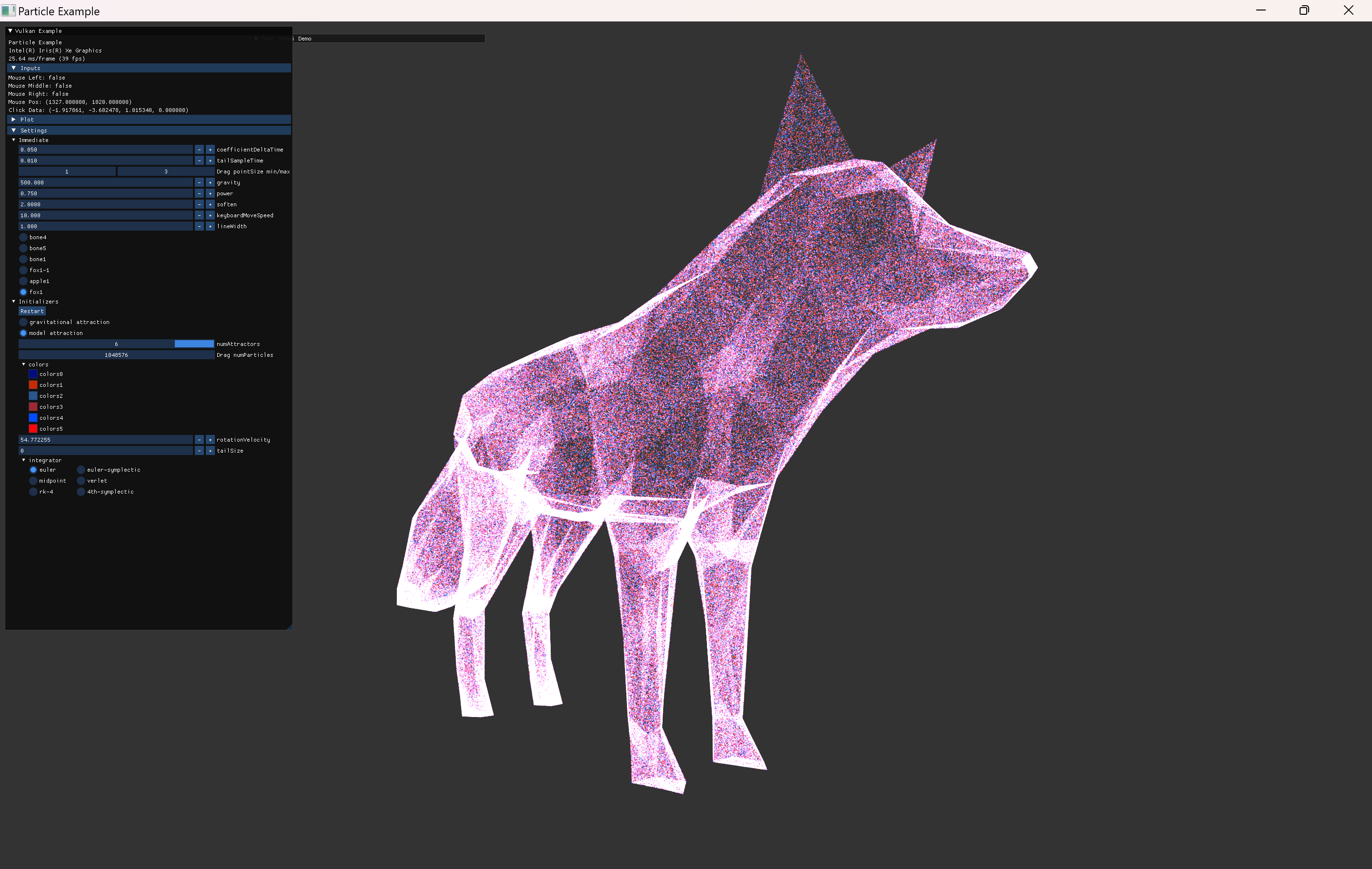
- animation 관련 내용 추가.
- fox model의 세가지 animation을 모두 사용할 instance를 생성해서 확인한다.
- 더 많은 vertex를 가진 ship model을 추가해서 회전하는 external animation을 하도록 추가했다.
- particle 수를 늘려서 테스트한다.
- 2^20 까지로 늘려서 확인.
- 이번 변경으로 인해 이전에 작업해둔 내용들의 실행도 문제 없는지 확인한다.
- n-body simulation
- model attraction without skinning
- model vertex attribute에 skinIndex 추가 및 저장
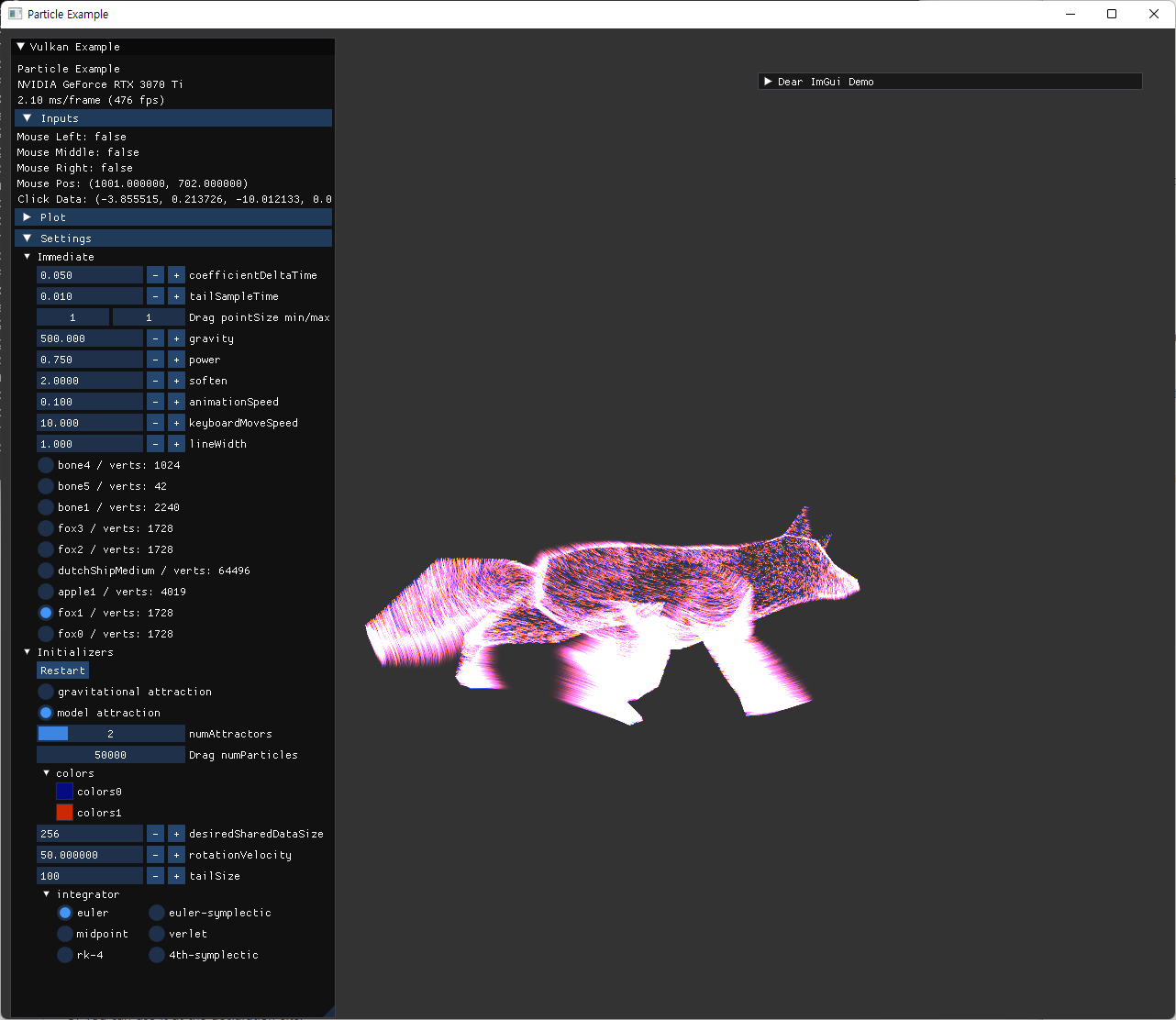
| fox | ship |
|---|---|
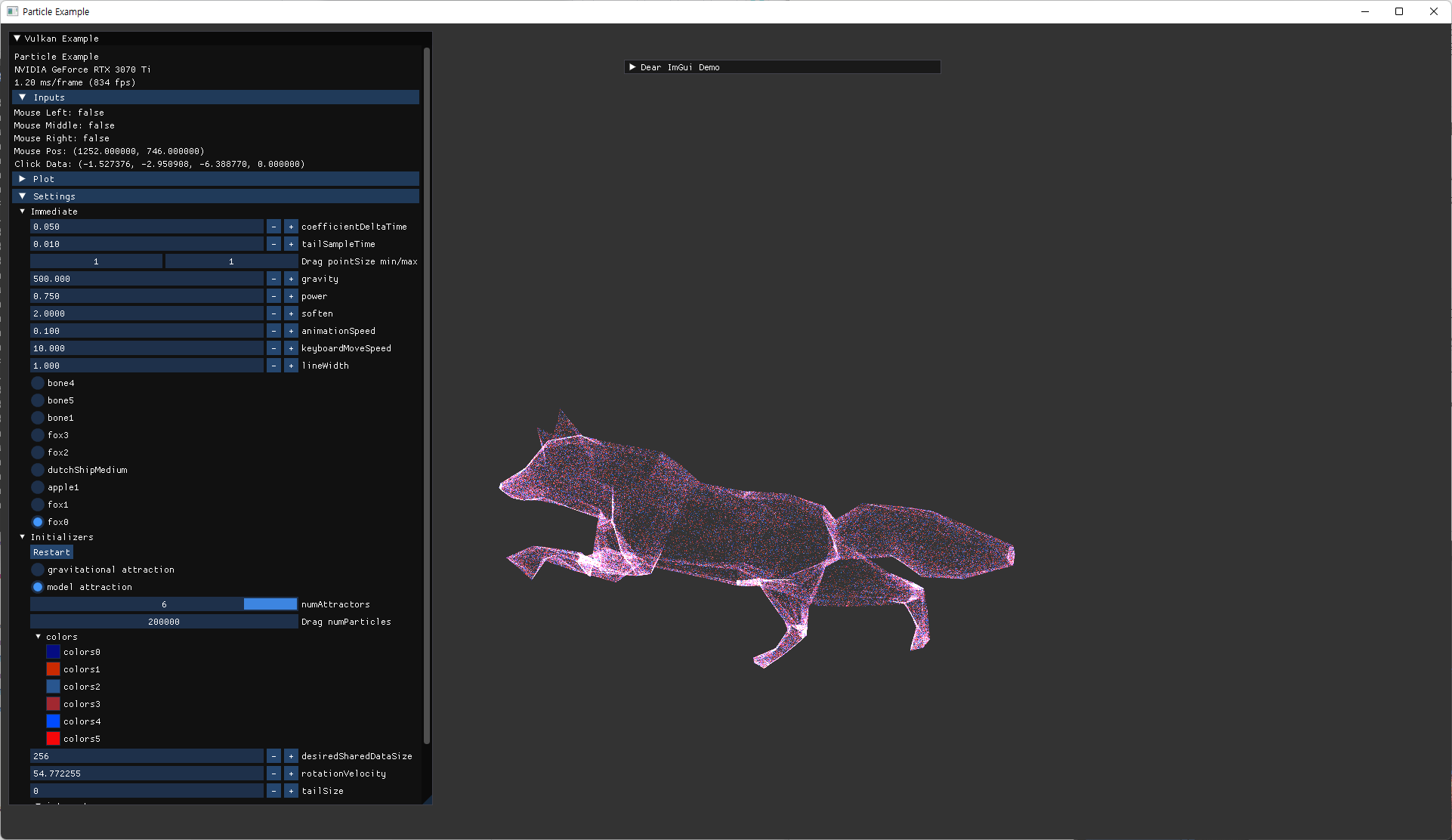 |
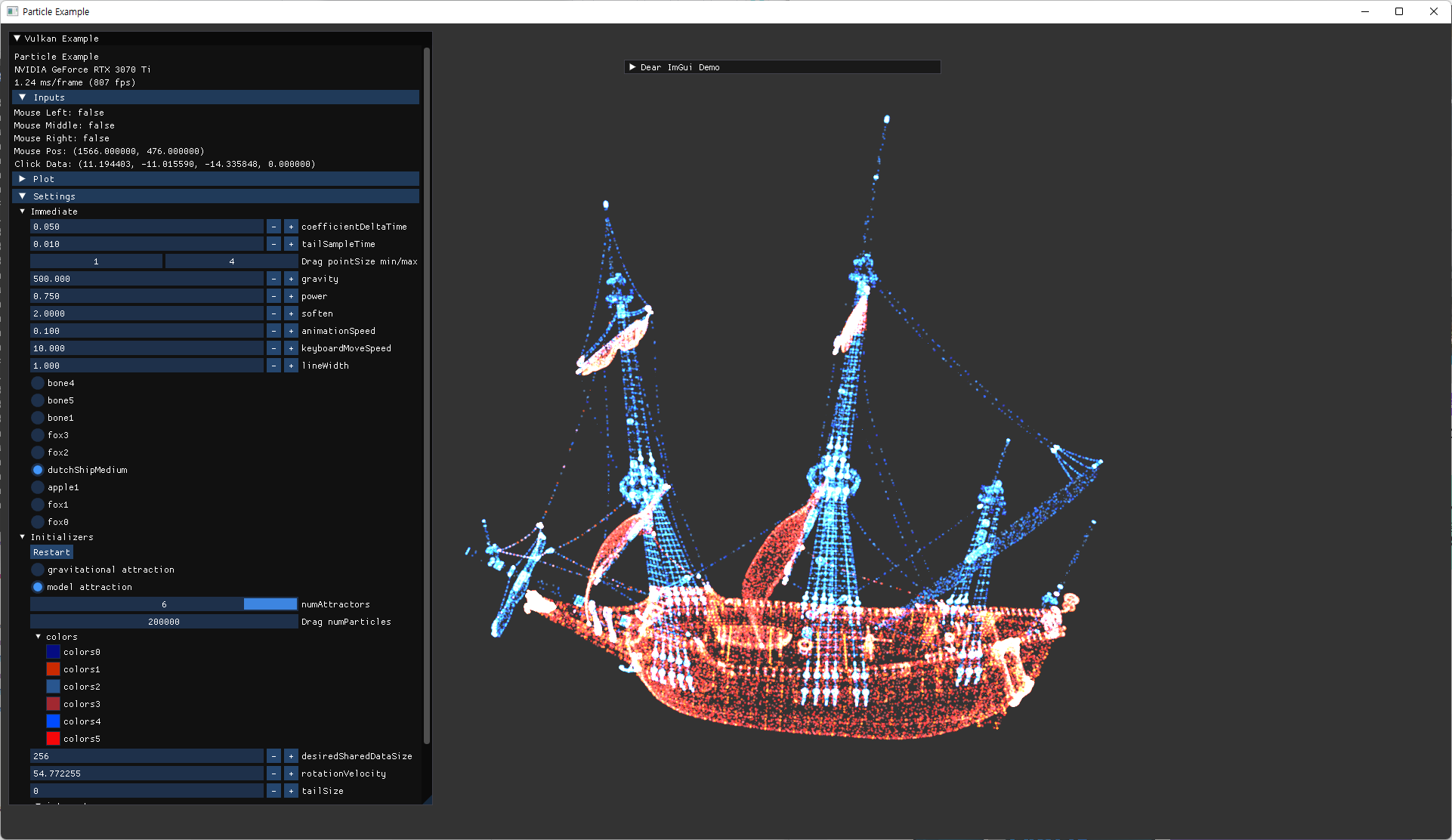 |
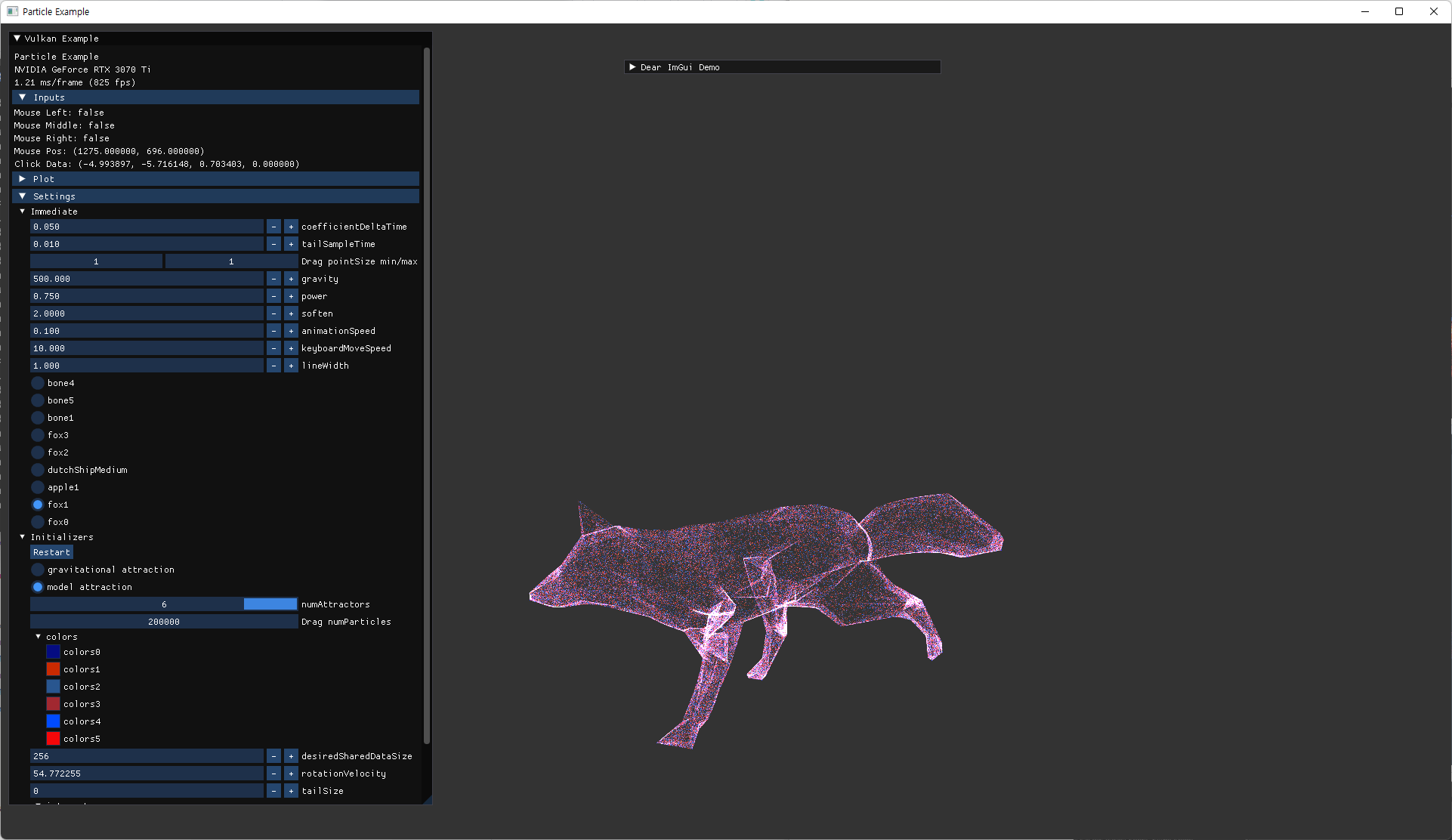 |
 |
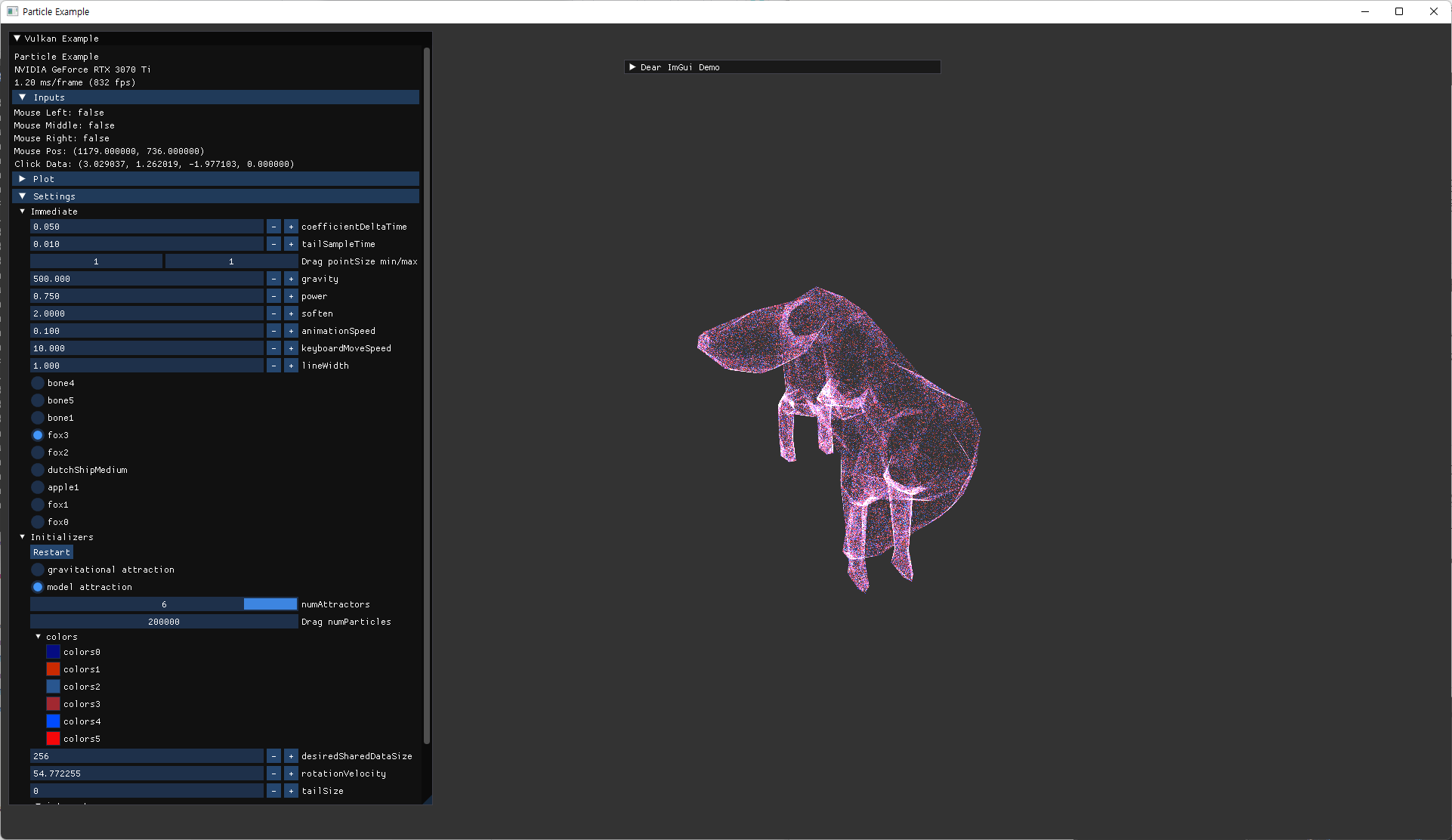 |
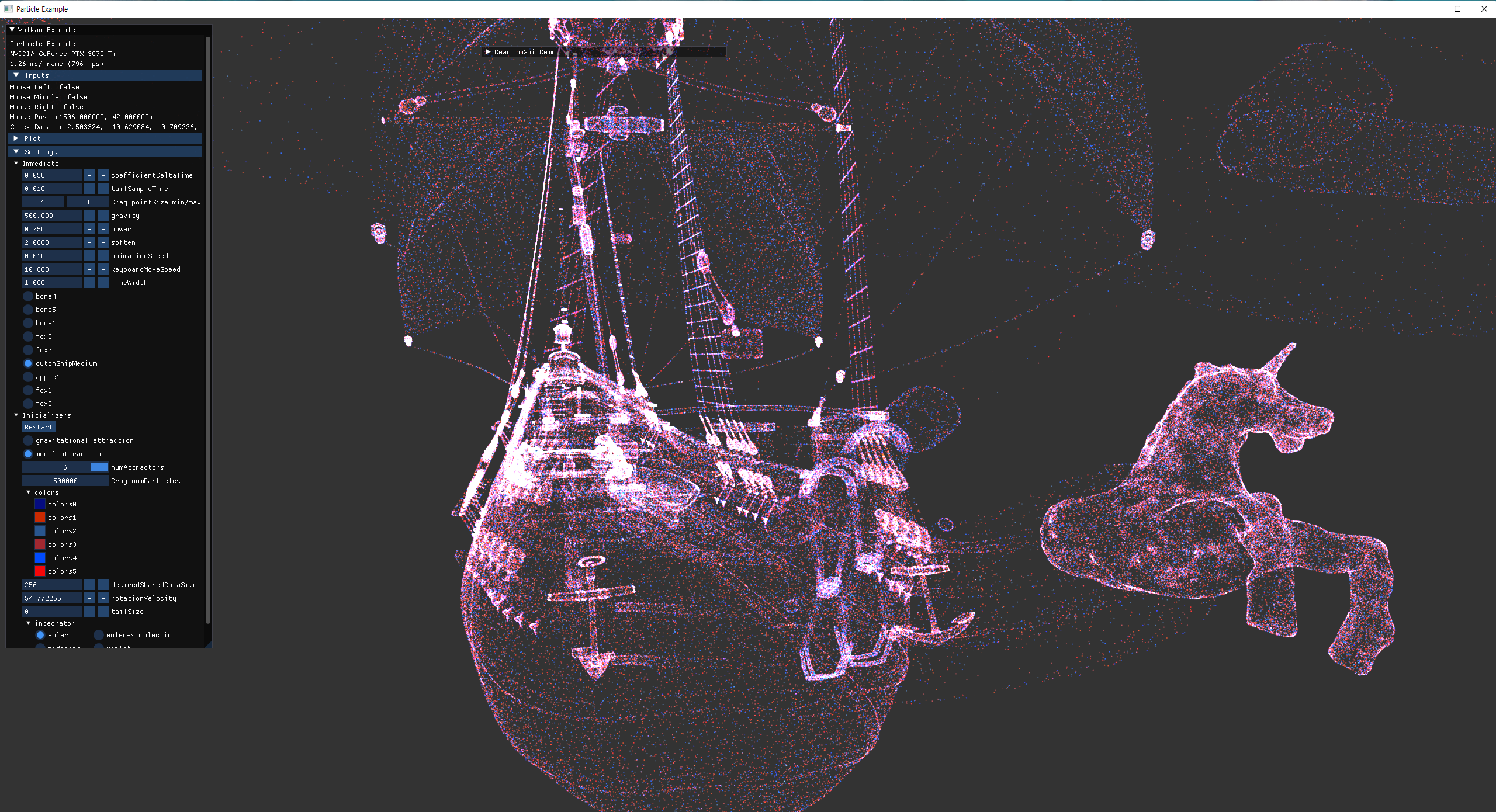 |
Trajectory in GPU
particle 수를 늘려서 실행했을 때, fps가 매우 낮아지는 경우를 확인했다. 그리고 최대 particle 수에서는 tail길이 만큼 그 buffer 크기가 배로 커지기 때문에 너무 큰 크기로 인해 buffer 할당이 실패하는 경우도 있었다.
우선 적당한 particle 수에서 적당한 tail 길이에서의 성능을 높이기 위해, GPU로 해당 계산을 옮겨 tail 계산과 memory transfer 비용을 줄이기로 했다.
여러 방식을 고민해봤는데, 구현하기 간단한 방식을 채택했다.
- tail buffer data에는
numParticles*tailSize만큼의 vec4가 들어간다. (position + w값 color) - tail buffer는 frames-in-flight 수 만큼으로 생성한다.
- compute shader에서 변경하고, rendering에 사용되므로 중복된 자원이 필요하다고 봤다.
-
step-2의 integrate이 완료된 후, 계산된 새로운 particle의 position을 tail SSBO의 해당 particle index 값들 중 첫번째에 위치시켜 준다.- 이전에 있던 값들은 한칸씩 뒤로 밀어주고 마지막 값은 버려지게한다.
- update할 주기가 아니라면, 아무것도 하지 않아도 된다.
- 이때 frames-in-flight를 고려하면 이전 frame의 tail buffer도 같이 bind 해줘야 하므로(particle SSBO에서
preFrameIndex를 쓴 것 처럼) 비효율적인 부분이 발생한다.- update하지 않아도 될 경우에도, 이전 frame의 tail buffer 값들을 전부 복사해줘야 한다.
- 구현 전부터 염두하던 부분인데, tailSize 만큼의 iteration이 각 particle 마다 추가되지만, particle에 대한 계산이 compute shader에서 병렬적으로 이뤄지므로 실험해볼만 하다고 생각했다.
- 그리고 buffer 크기 한계로 인해 particle 수가 많은 경우에는 어차피 큰 tailSize를 사용할 수 없어서 성능이 치명적인 경우로 실행시키지는 않을 것 같았다.
- 이 과정을 개선시키기 위한 구조를 구상해봤는데, 구현이 복잡해지기도 하고, 이 상태로도 이미 원하는 수준의 성능 개선이 가능해서 더이상 최적화 하지 않았다.
- update하지 않아도 될 경우에도, 이전 frame의 tail buffer 값들을 전부 복사해줘야 한다.
- queue family ownership transfer 관련 처리는 이전과 동일하게 해줘야한다. (compute queue와 graphics queue 모두에서 사용되는 SSBO이므로)
|
image
|
explanation |
|---|---|
 |
tailTimer값을 증가시키면서 tailSampleTime 값을 초과하면 0.0으로 reset 시켜주고, 이 값을 UBO로 shader에 전달해, 0.0이면 tail update를 수행하는 구조로 구현했다. 초기 구현에서는 이 0.0으로 reset을 하는 코드가 frameTimer만큼 increment하는 코드보다 위에 있어서 shader로 전달된 값이 0.0이 되지 않았고 tail update가 되지 않으면서 undefined 된 값이 들어가는 문제가 있었다.
|
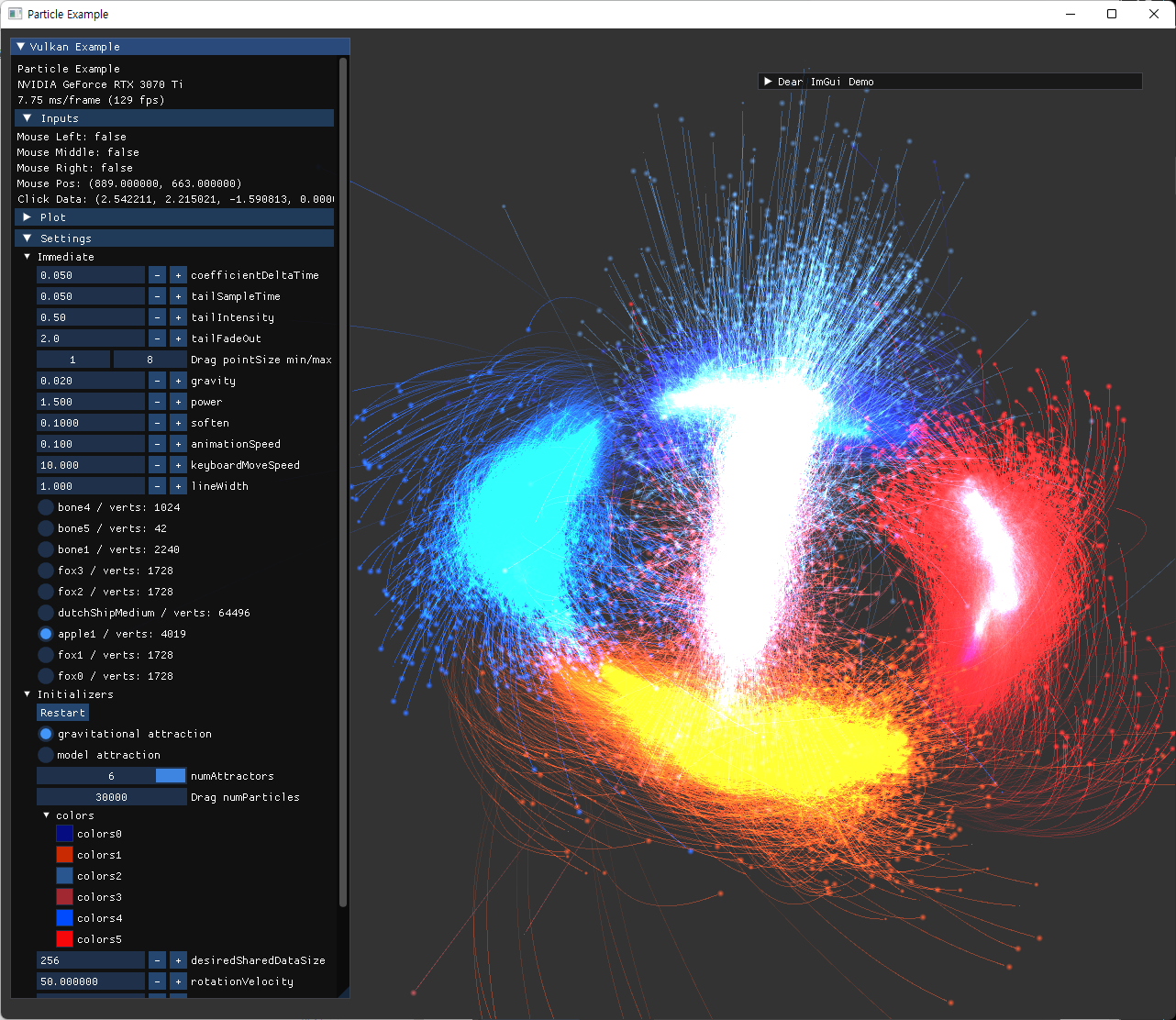 |
구현된 tail 기능을 활용해 기존 trajectory rendering이 가능했던 것 보다 더 많은 수의 particle과 긴 trajectory도 좋은 성능으로 나타낼 수 있게 됐다. 이후에 tail 관련 alpha값과, fadeout 정도, 선 width 등 수치도 수정할 수 있도록 추가해줬다.
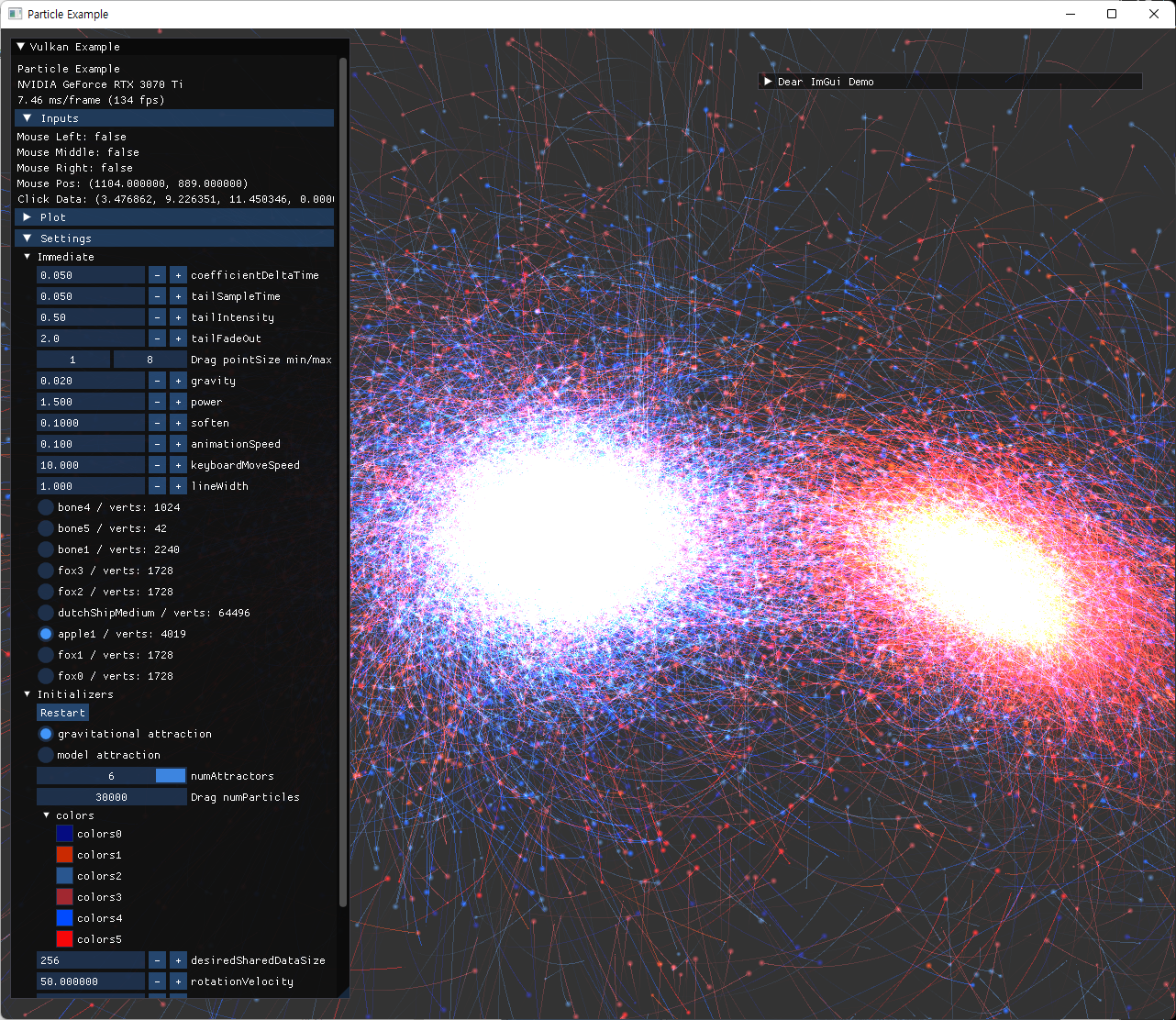 |
 |
 |
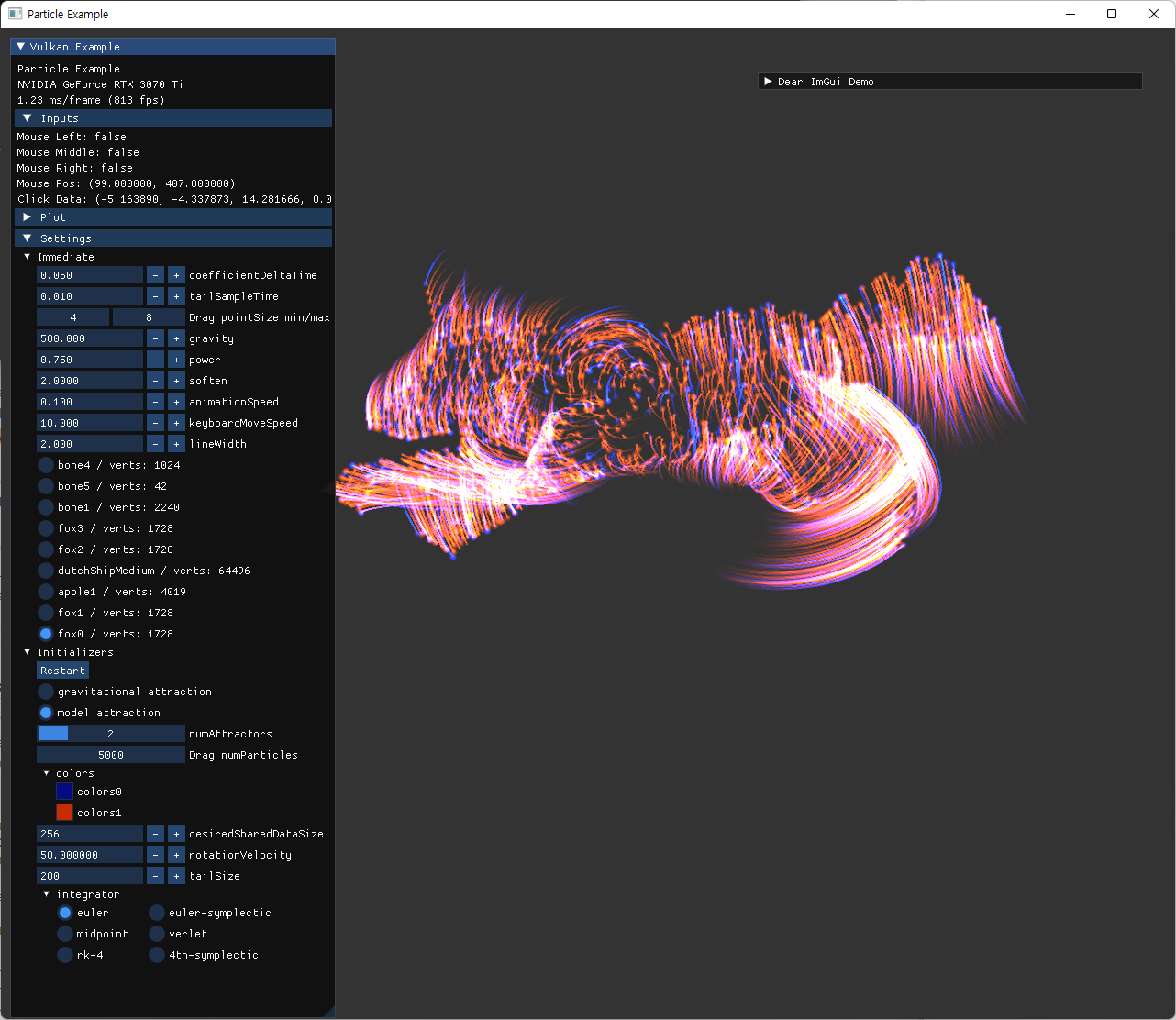 |
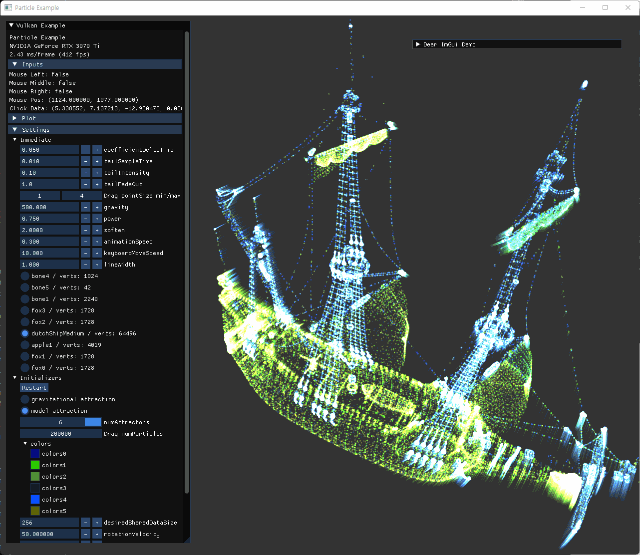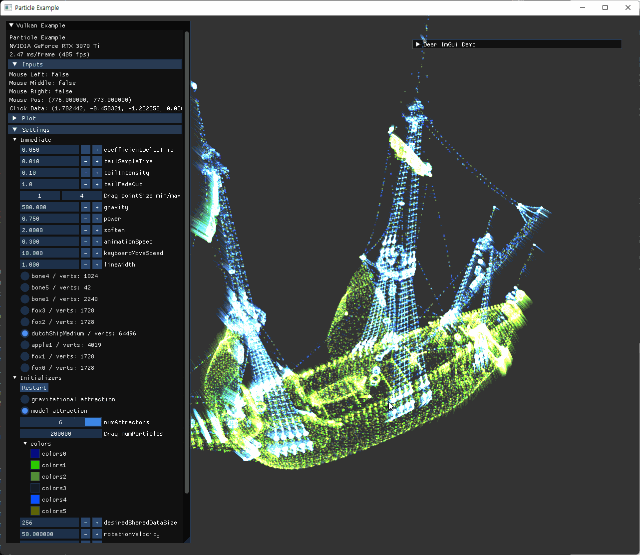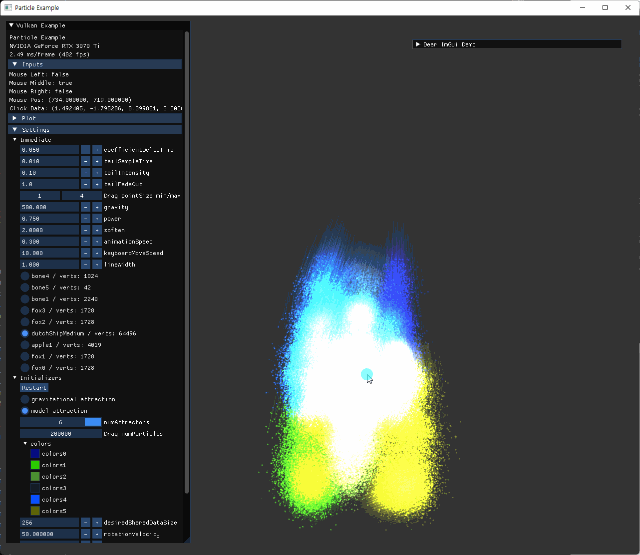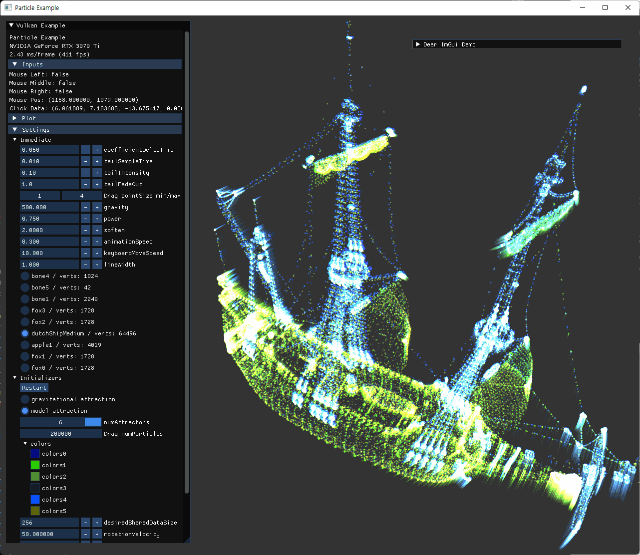
Demo
animation의 속도가 너무 느리면, particle이 이동하기 전에 target 위치가 바뀌면서 예상된 animation을 알아보기 힘든 경우가 나올 수도 있다. 관련 설정 수치들 모두 imGui 패널에서 수정가능하도록 구현되어 있다.
마무리
이번 compute shader 예제 작성을 하며 지난 tutorial과 이전 예제 작성에서 다뤘던 내용들이 대부분 다시 쓰였다. 그래서 애매했던 개념들은 다시 정리하면서 보충할 수 있었다. 특히 GPU memory 구조나 compute shader에서 쓰이는 기능들을 좀 더 알게되었는데, 이전 tutorial의 간단한 compute shader 구현에서는 지나쳤던 내용들을 많이 보충할 수 있었다.
예제에 여러기능을 추가하면서 테스트하고, 계획을 수정하다 보니 시간소요가 되는 구간들이 있었다. 처음 구조 계획을 할 때와 어느정도 기능을 구현 후 덧붙여 나가는 과정에서 좀 개발 속도가 느려진 감이 있었고, 중간에 계획한 내용들을 구현하고 조사 및 공부를 하는 과정에서는 루즈해지지 않았던 것 같다. numerical integrator 관련 이론을 공부 할 때 필요한 것 보다 더 많은 내용을 보게 되기도 했는데, 오히려 시간은 오래 걸리지 않았었다. 앞으로 필요할 때 다시 공부를 재개한다면 분명 도움이 될 것 같다.
이 예제 작성 완료 후 미뤄져 있던 blog 글들을 많이 쓰게 됐는데, 주로 공부나 tutorial을 따라서 연습했을 때는 게재할만한 내용이 적다는 생각이 들어서였던 것 같다. 시간이 좀 지나서 글을 쓰니 처음 기록했던 내용들이 기억에서 조금 잊혀졌을 때 다시 복습하는 느낌이 들었던 것은 좋았지만, 글을 정리하거나 여기저기 흩어진 사진이나 자료들을 모으는 시간은 더 들긴 했다.
이후에는 PBD와 관련된 내용의 예제를 만들어 볼 생각인데, 진행상황 기록을 좀 더 작은 단위로 나눠서 해도 좋겠다는 생각이 들었다.