Theoretical Background
cloth simulation on GPU에 대한 내용을 다루고, 구현 내용을 다루려 한다.
PBD에서의 시뮬레이션 모델을 다루기 전에, 기존 example repo에서 vulkan compute shaderf를 사용한 기본적인 cloth simulation 예제가 있어서 이 예제 구조를 먼저 살펴봤다.
Existing example implementation
참고한 SaschaWillems Vulkan example 코드
- Vulkan/examples/computecloth/computecloth.cpp at master · SaschaWillems/Vulkan (github.com)
- Vulkan/shaders/glsl/computecloth/cloth.comp at master · SaschaWillems/Vulkan (github.com)
이 예제에서는 cloth를 grid 형태의 particles로 보고, 이 particle 간의 상호작용을 compute shader에서 계산한다.
- cloth model: 간단한 grid 형태만 다루기 때문에, 별도의 cloth model을 load 하지 않고, 직접 grid의 particle position을 지정해서 생성한다.
- 우리는 이후 더 복잡한 형태의 옷을 다룰 것을 염두해 두고 gltf model로 cloth 구조를 불러오려 한다. (일단은 동일한 grid 형태의 간단한 구조만 먼저 추가하긴 할 계획이다.) 기존 animation에서 다뤘던 gltf load 구조를 그대로 사용하되, ssbo 중 vertex buffer는 사용하지 않고, index buffer만 사용하는 식으로 이용할 계획이다. model의 texture 등은 그대로 쓰면 된다.
- SSBO
- 예제에서는 생성한 초기 grid particle을 담을 input ssbo와 compute 결과를 담을 output ssbo를 별도로 둔다. 이 output은 graphics pipeline에서도 rendering에 사용한다.
- 우리는 input은 model load에서 불러온 값을 사용할 것이라 별도의 ssbo를 추가할 필요는 없고, compute와 graphics pipeline에서 공용으로 사용할 ssbo는 새로 추가해야 한다. 이를 위해 관련 자원을 담을 cloth model 구조를 추가할 계획이고, 이전부터 변경해왔던대로 frames in flight 수를 고려해서 자원들을 추가하면 된다.
- graphics pipeline
- 예제에서는 cloth를 rendering 할 pipeline과, 간단한 거리 collision interactiond을 위한 sphere pipeline을 가지고 있다.
- 우리도 cloth를 그려줄 pipelines (texture사용과 wireframe)을 추가해줘야 한다. 따로 sphere를 위한 graphics pipeline은 필요없고, 이전부터 사용해오던 phong shading을 적용한 다른 model들(사과나 여우 모델 사용) graphics pipeline은 유지한다.
- compute pipeline
- semaphores
- 이전에 particle 관련 compute shader 예제를 작성할때, 추가했던 부분과 동일한데, 코드 형태만 조금 다르다. compute dedicated queue를 사용하면서, 서로 다른 queue family 간의 공유되는 memory(ssbo)의 ownership transfer operation (acquire과 release)의 sync를 위해 graphics와 compute에 semaphore를 하나씩 (frames in flight 만큼) 추가로 사용했던 부분에 해당한다.
- 이전 particles 예제의 sync관련 내용
- 저번에 찾은 버그도 있어서 같이 수정할 계획이다. compute dedicated queue가 supported 되지 않으면 이 ownership transfer가 없어도 되고, pipeline barrier나 아니면 semaphore (compute와 graphics submit된 command의 사이의 sync를 위한) 로도 충분하기 때문이다.
- 우리는 일관된 구조를 위해서, transfer operation만 분기처리하고, semaphore를 그대로 사용한다. 대신 graphics에 두던 sema를 제거하고, 모두 compute로 옮겨 이름을 예제와 같이 ready, complete로 쓸 계획.
- uniform buffer
- dt, mass, stiffness, damping, rest distance, gravity, particle count
- 등을 쓰고 있고, 우리도 유사하게 쓰일 것들만 선택해서 추가한다.
- storage buffer
- cloth와 간단한 충돌에 쓰일 sphere 한개만 별도로 사용하고 있는데, 우리는 여러개의 sphere를 다뤄볼 예정이다.
- 기존 animating model과의 collision을 다룰 생각이라 별도 구조를 쓰지 않아도 될 수도 있다. 이 부분은 최적화를 위해서는 collision 처리에 대한 구현이 잘 되어야 하는데, hash사용이나 tree 구조 등 내용을 구현하기에는 cloth simulation 주제에서 벗어나는 부분이 많아 성능을 감수하고 최대한 간단하게 구현해볼 계획
- descriptor sets
- 2개의 readset을 두고 descriptor sets를 iteration에서 교차로 사용하는 구조로 구현되어 있다.
- input을 받아서 output에 쓰고, output을 받아서 input에 쓰는 형태 때문에 이렇게 구현된 것으로 보이는데, 우리는 double 혹은 N-buffering을 쓸거라 이전에 하던 것처럼 prevFrameIndex를 쓰면 된다. cloth ssbo에서도 input output 구분이 필요 없는 것과 같은 이유.
- 이전에 particle 관련 compute shader 예제를 작성할때, 추가했던 부분과 동일한데, 코드 형태만 조금 다르다. compute dedicated queue를 사용하면서, 서로 다른 queue family 간의 공유되는 memory(ssbo)의 ownership transfer operation (acquire과 release)의 sync를 위해 graphics와 compute에 semaphore를 하나씩 (frames in flight 만큼) 추가로 사용했던 부분에 해당한다.
- semaphores
PBD lecture summary
cloth simulation의 개념적인 부분은 모두 PBD의 내용을 따랐다. 3개 lecture에 해당하는 영상과 note를 보고 몇가지 내용을 선택, 변경해서 반영했다. 내용들은 이해한 부분들을 간단히 정리만 해두려 한다.
Lec 14
observation:
- cloth is stretchable
- 처음 5%까지의 힘에서만 길이가 늘어나고 그 이후로는 거의 일정함.
- 중력이 옷을 늘리는 일은 거의 없다.
- stretching이 너무 없는 cloth simulation이 많다.
- 하지만 너무 많은 stretching은 시각적 효과 측면에서 보기 좋지 않다.
- latex같은 재질은 dynamics가 없고 거의 정적인 motion을 이루기 때문에, skeleta skinning 방식으로 처리하는게 낫다고 한다.
결론:
- 복잡한 cloth model들은 그 늘어나는 5% 의 힘 구간을 simulation하기 위한 것.
- 우리는 stiffness가 inf인 material을 가정하고 simulation 하고자 함.
- force 기반의 방식은 explode하는 문제가 있음.
- 우리가 취할 방식은 zero compliance distance constraint on cloth mesh edges with XPBD
- 이 방식은 parameter tuning이 필요 없어서 좋다.
Bending Resistance
- 하나의 parameter가 필요함.
- 두 인접한 삼각형간의 constraing로 접근
- 반대편 두 점 (공유된 edge 가 아닌)의 거리 방식
- simple하지만 flat한 형태에서 constraint가 약함
- 두 삼각형이 flat하면 (거의 구부러진 각 없이 평행하면) 조금 접히더라도 각 두 삼각형의 반대편 두점 사이의 거리 변화가 작다는 뜻으로 이해함.
- 접힌 angle 방식
- flat 한 경우에서도 강한 조건이 됨. 하지만 계산 비용이 큼
- 우선 더 간단한 거리 방식으로 구현해보고 각도 방식으로 개선하면 좋을 듯 함.
- simple하지만 flat한 형태에서 constraint가 약함
- 반대편 두 점 (공유된 edge 가 아닌)의 거리 방식
triangle neighbor를 찾는 법
- global edge number를 부여한다. tri_nr * 3 + local_edge_nr
- edge에 연결된 (v_index 낮은 것, v_index 높은 것, global_edge_nr) 이 세개를 하나의 tuple로 묶는다.
- 이 edge 별 tuple들을 lexicographic order로 정렬.
- 이때 v_index 부분 두개가 같은 edge가 연속해서 나오면 adjacent edge임. 두 삼각형이 공유하는 edge
- 이 정보를 가지고 edge neighbor list를 구성한다.
- -1: edge is open
- 두 연속한 edge tuple이 adjacent edge면, 서로 반대편 global_edge_nr을 넣어준다.
- 이 global_edge_nr만 있으면, tri_nr과 local_edge_nr 둘다 얻을 수 있음.
- 이렇게 찾은 인접 삼각형 정보를 가지고 XPBD의 constraint로 계산하는데, 이 lec14에서는 CPU 계산으로 구현되어 있다.
Lec 15
cloth self-collision은 어려운 문제중 하나다.
- soft body에는 outside와 inside가 명확해서 충돌처리가 명확하지만
- cloth에는 in out 개념이 없다.
- global problem이다. 접근은 여러 방식이 있다.
- 시작이 valid 했다면 그걸 유지하도록 보장하는 방식.
완벽한 해법은 아니더라도, 5가지 트릭을 제시함.
- particles와 particle hash로 collision detection
- 복잡한 하나의 대상을 다루는게 아니라, 간단한 primitives(particle)을 여러개 많이 쓰는 접근
- cloth를 여러개의 particle로 보고 문제를 접근하라는 얘기 같다.
- 구현이 간단하고 자유도가 높아 fidelity가 높다고 한다.
- rest distance로 jiterring 피하기
- 보통 particle이 서로 2r 거리에 있기를 원하는데 그보다 가깝게 rest distance가 설정된 경우에 jittering 문제가 발생한다.
- 충돌 constraint와 거리 constarint가 싸우면서 jittering이 발생
- collision 거기를 더 작은 거리로 설정해서 어느 정도 해결되지만 메모리 사용이 커진다고 함.
- continuos collosion detection이 아닌 substeping 사용.
- 두 particle이 계산 시간간경의 처음에도 충돌하지 않고, 끝에도 충돌하지 않는 경우지만, 그 사이에서 충돌했을 경우가 있다.
- 이럴때 CCD라는 방법으로 충돌을 검출한다.
- swept volume의 overlap을 검사해서 검출되면 rollback하는 방식
- 이런 처리 대신 시간 간격을 더 쪼개서 substepping을 써서 이런 일을 방지하자.
- hash 계산은 substepping loop 이전에 한번만 하라고 한다. 안그러면 너무 느려진다고 함.
- 두 particle이 계산 시간간경의 처음에도 충돌하지 않고, 끝에도 충돌하지 않는 경우지만, 그 사이에서 충돌했을 경우가 있다.
- max velocity 부여
- 속도가 너무 커지면 substepping에도 불구하고 충돌을 놓치게 된다고 함.
- max vel을 r / t_substep 정도로 지정하면 좋다고 함.
- unconditionally stable cloth-cloth friction 기법
- damping coefficient를 넣어서 overshoot 하지 않도록 처리하는 기법
실제로 cloth simulation을 구현해보니, 이 self-intersection처리가 왜 중요한지 알게 됐다.
기본적인 stretch, bending, shearing 등 constraint를 구현하면 아주 간단한 dynamic만 확인이 가능한데, cloth가 중력으로 인해 펼쳐지거나 흔들리는 정도이다. cloth와 animating model이나, mouse interaction을 추가했을 때, cloth가 꼬이거나, 한쪽 끝이 cloth를 통과하는 등 문제가 생기면 아예 현실적인 느낌이 들지 않았아서 이런 처리를 위한 기법이 왜 중요한지 느꼈다.
여기서 소개한 trick들이 단순한 편이겠지만 self-intersection이 다른 constraint와 다르게 하나의 fancy 한 방식으로 처리되는게 아니라, 여러가지 기법을 중첩시켜 해결해야되는 문제라는 정도를 이해하고 넘어갔다.
Lec 16
전체적인 구조
- gpu memory로 particle의 v, p(업데이트 전 x), x(업데이트 된 position)를 저장해놓는다.
- main memory에는 x만 있으면 된다. (mouse interaction 등을 위해서 인듯). rendering은 GPU에서 할거라 사실 main memory에 x를 남길 필요도 없을 것 같음
- data copy는 DMA로 이뤄진다고 함.
- python + warp를 쓰고, nvidia omniverse를 써서 시각화 한다.
- gpu에서는 thread id를 각 particle index로 mapping해서 계산한다.
challenge 1
- per particle loop에서는 각 thread가 각 array entry에 적어서 문제가 없다.
- constraints는 여러 threads가 같은 array entry에 적을 수도 있는 문제가 있다.
- atomic add를 써야 함.
- 좀 느려진다.
challenge 2
- 동시에 읽는 것과 쓰는 것
- 여러 constraint에서 하나의 x에 대해서 읽는 것과 쓰는 것의 순서를 보장할 수가 없다.
- 예를 들어 1번 particle의 업데이트를 위해서, 0번 particle의 위치를 읽어서 1번과의 거리를 계산해야 한다고 해보자. 0번을 읽을 때, 다른 thread에서 0번에 뭐가 쓰여지고 있는지 이 순서를 알 수 없다는 것.
- Jacobi solver / graph coloring 두가지 방법이 있다.
Jacobi solver (vs. Gauss-Seidel solver)
- cpu 에서는 각 constraint에서 계산한 correction을 바로 particle에 더했다.
- 하지만 Jacobi solver에서는 d라는 correction vector에 모든 correction을 저장하고, 마지막에 한번에 particle에 적용한다.
- (이때도 correction vector에는 atomic add)
- 이렇게 하면 solve 도중에는 x가 변하지 않는다.
- 하지만 error propagation이 느려서 convergence가 느려진다.
- 그리고 overshooting 문제가 있어서 1보다 작은 계수를 곱해줘야 한다고 함.
- correction을 전부 평균내서 더해주는 방법도 있는데,
- (5개의 constraint가 한 particle에 적용되면 5로 나누자는 말)
- strength가 주변 constraint에 영향을 받게되고, momentum conservation이 위반되는 문제가 있다고 한다.
- 계수는 1/4 가 적당하다고 한다.
graph coloring
- 계산 과정을 나눠서 전체 particle의 계산을 한번에 하지 않고 여러 pass로 나누는 방식
- 각 pass는 독립적인 constraints로 구성된다
- 보통 cloth를 4개의 pass로 나눈다고 함.
- 하지만 이 pass 구성을 찾는 건, graphc coloring 문제를 푸는건데,
- np hard라고 함.
- greedy로 적당히 작은 수의 group이 되도록 pass를 찾자.
- pass가 최소 한 node랑 연결된 edge 수 만큼은 필요하다
- degree.
- 구현은 stretching constraint만 graph coloring으로 하고,
- 나머지 bending 과 shear는 Jacobi로 하면 좋다고함. 이 조건들은 stiffness가 필요 없어서.
integration
- 여러 pass별로 계산한다
- distance constraint
- 이안에 stretching, bending, shearing constraint가 전부 들어있고, 각 pass 별로 constraints에 접근할 index만 구분해준다.
- 구현할때는 간단한 사각형 grid 형태 cloth여서 constraint 초기 구성을 해준다.
- distance constraint
- 이후에 vel update로 PBD구조 구현.
구현
- python구현 코드 구조를 보고 많은 부분을 참고했다.
- warp에서는 launch나 copy 등은 synch가 implicit하게 맞춰진다고 한다. (GPU-CPU synch https://github.com/NVIDIA/warp)
- distConstIds에 두 v index를 pass별로 나눠서 전부 저장해놓고 하나의 ssbo로 전달한다고 볼 수 있다.
- 이 ssbo는 read only로 둬도 될 것 같은데, 초기 rest length 계산을 gpu에서 해주려면 write가 필요하다.
Implementation
Plans
lec 16을 참고한 구현 구조 구상은 다음과 같다.
SSBO
- compute에 사용할 particle 구조. x, v, p (prev position) data
- render에 사용할 particle 구조. normal 등
- dist constraint ids
- vertex id 두개와 rest length
compute
- 각 작업의 command를 recording 하고, 이전 작업이 끝나도록 pipeline Barrier를 통해 sync 맞추도록 command 들 사이에 recording 해줘야 함.
- rest length 계산해서 저장
- 초기 1회만. CPU에서 해줘도 될 것 같음
- integration
- 매 substep마다
- solve distance constraints
- 매 substep마다. independent pass는 memory barrier없이 한번에 recording 되어도 될 듯 함.
- stretch 4개의 independent pass는 Gauss-Seidel solver를 쓰고 나머지 constraints들은 하나의 pass에 넣어서 Jacobi soler로 쓴다.
- add correction
- correction을 바로 반영할지, Jacobi solver로 할지를 pass independence에 따라서 처리
- vel update
- 매 substep의 마지막에서
- compute normal
- substep이 모두 끝난 후, rendering 이전에 필요한 normal등을 업데이트
Implementation items
처음에는 CPU에서 simulation을 작성하고, GPU로 옮겨보면서 성능 비교를 해보고 싶었는데, 애초에 메모리 구조나 실행 구조를 생각했을 때, 아예 서로 다른 프로그램이 될 것 같아서 GPU 구현에 중심을 두고 계획부터 GPU 사용쪽에 초점을 맞췄다.
- compute 부분 없이 graphics pipeline 작업
- cloth와 다른 animating model등, wireframe rendering등을 우선 작업
- render에 사용될 particle buffer 자원등을 생성하고 초기화 파트 구현.
- cloth buffer 등 자원 생성
- compute shader에 constraint 없이 gravity 만 추가.
- stretch constraint만 추가해서 동작 확인.
- 우선은 하나의 cloth에 대해서만 구현하되, 여러개의 cloth가 서로 distance constraint가 적용될 수 있도록 염두.
- model과 collision 처리
- 우선 하나의 model과 collision만 구현하되, 구조는 여러 model과 가능하도록 염두.
- mouse interaction
- mouse click info를 GPU로 보내서 compute shader에서 계산해야함
- cloth particle의 data가 전부 GPU에 있기때문에.
- 아니면 cloth particle 전체를 CPU로 copy해야하는데 굳이 그럴 필요가 없다고 생각했음.
- mouse click info를 GPU로 보내서 compute shader에서 계산해야함
SSBO draw
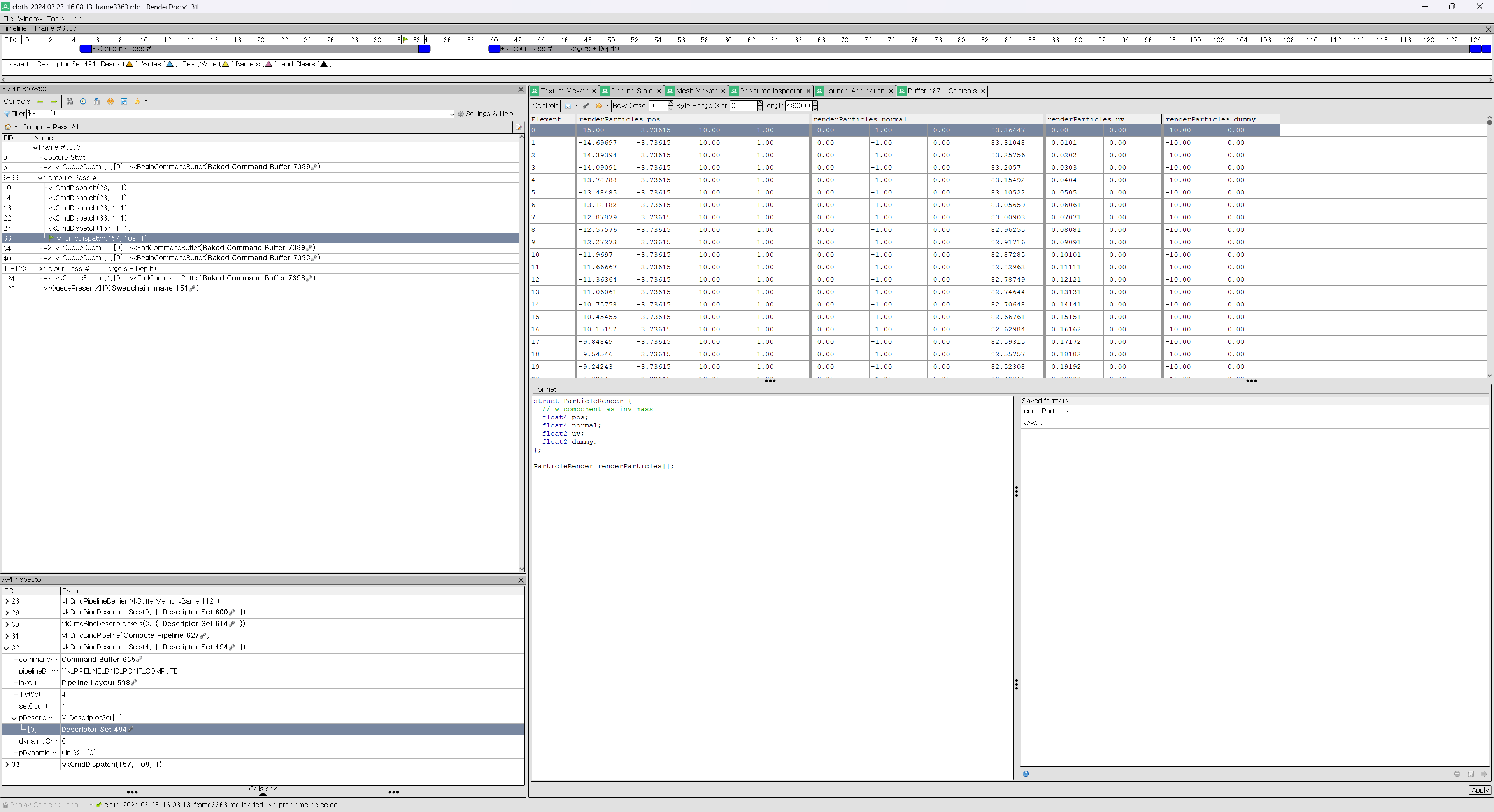
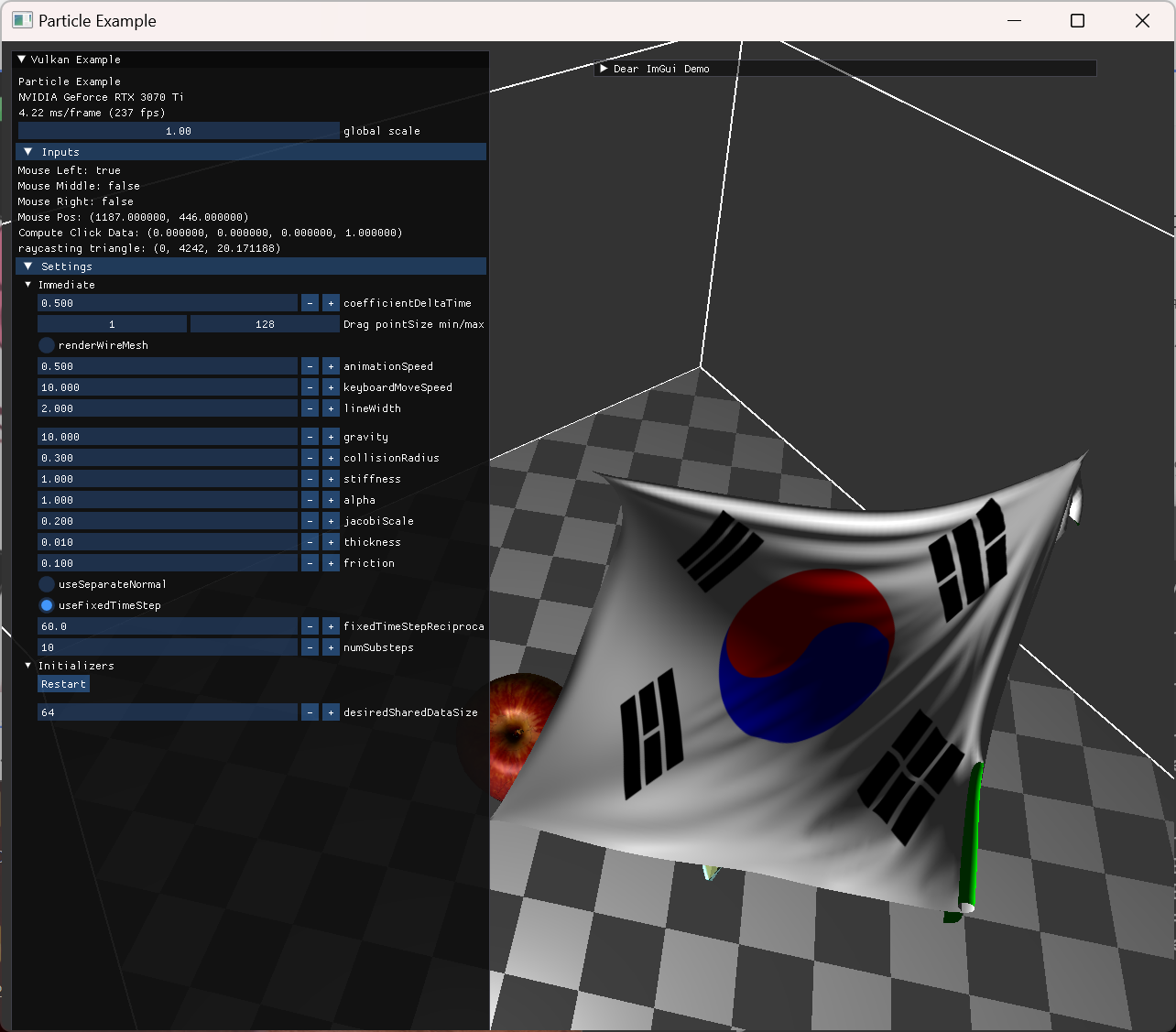
처음 cloth 데이터를 load 하고, 정지된 texture를 render하는 부분을 구현했다. 이후 바로 자원 생성하는 부분 작업을 해준 후, compute shader 에서 gravity에 영향 받는 부분을 작성했는데, 다음 이미지 처럼 particle 좌표가 이상하게 변동됐다.
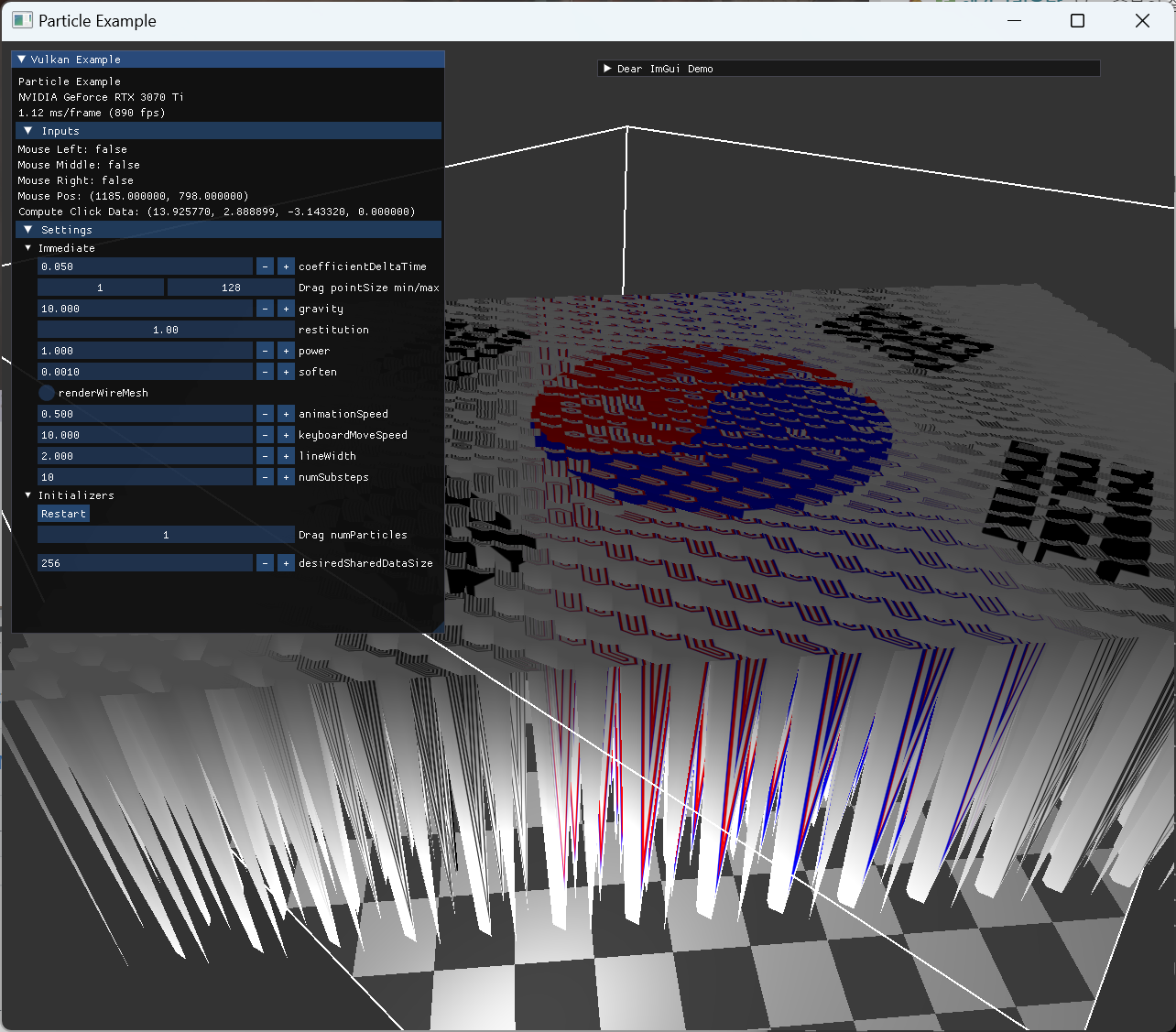 |
render doc을 열어서 particle buffer의 값들을 확인해보니 buffer에 데이터가 밀려들어가 있었고, 확인해보니 alignment 관련된 문제여서 수정할 수 있었다. |
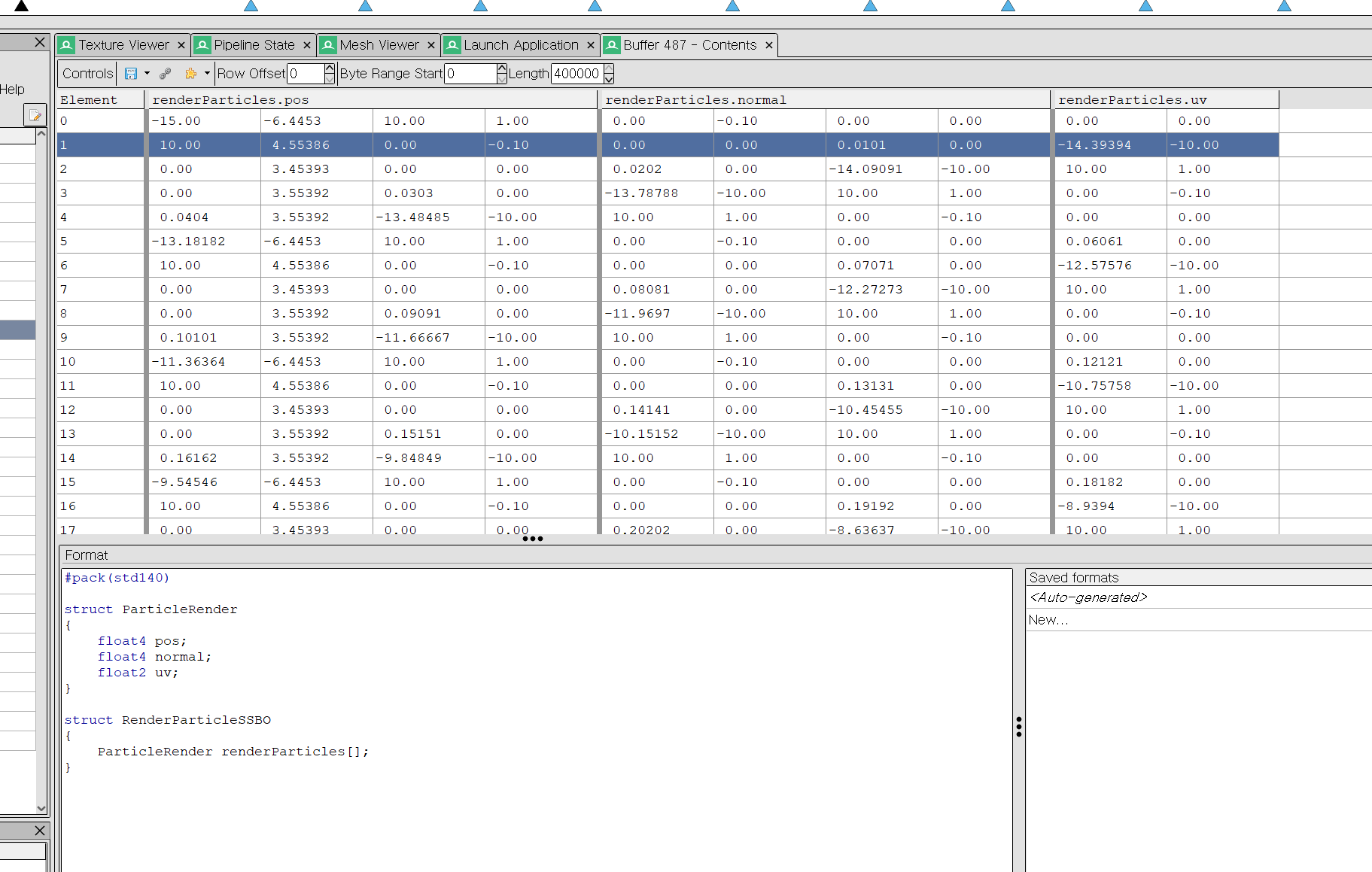 |
pos 나 normal의 .w 부분을 보면 1이 들어있어야하는데, 다른 값들이 들어있는 것이 보인다. structure 형태의 data를 가지는 buffer의 값을 보기위해서는 format을 지정해줘야 하는데, 코드에 맞춰서 하단에 적어줬다. |
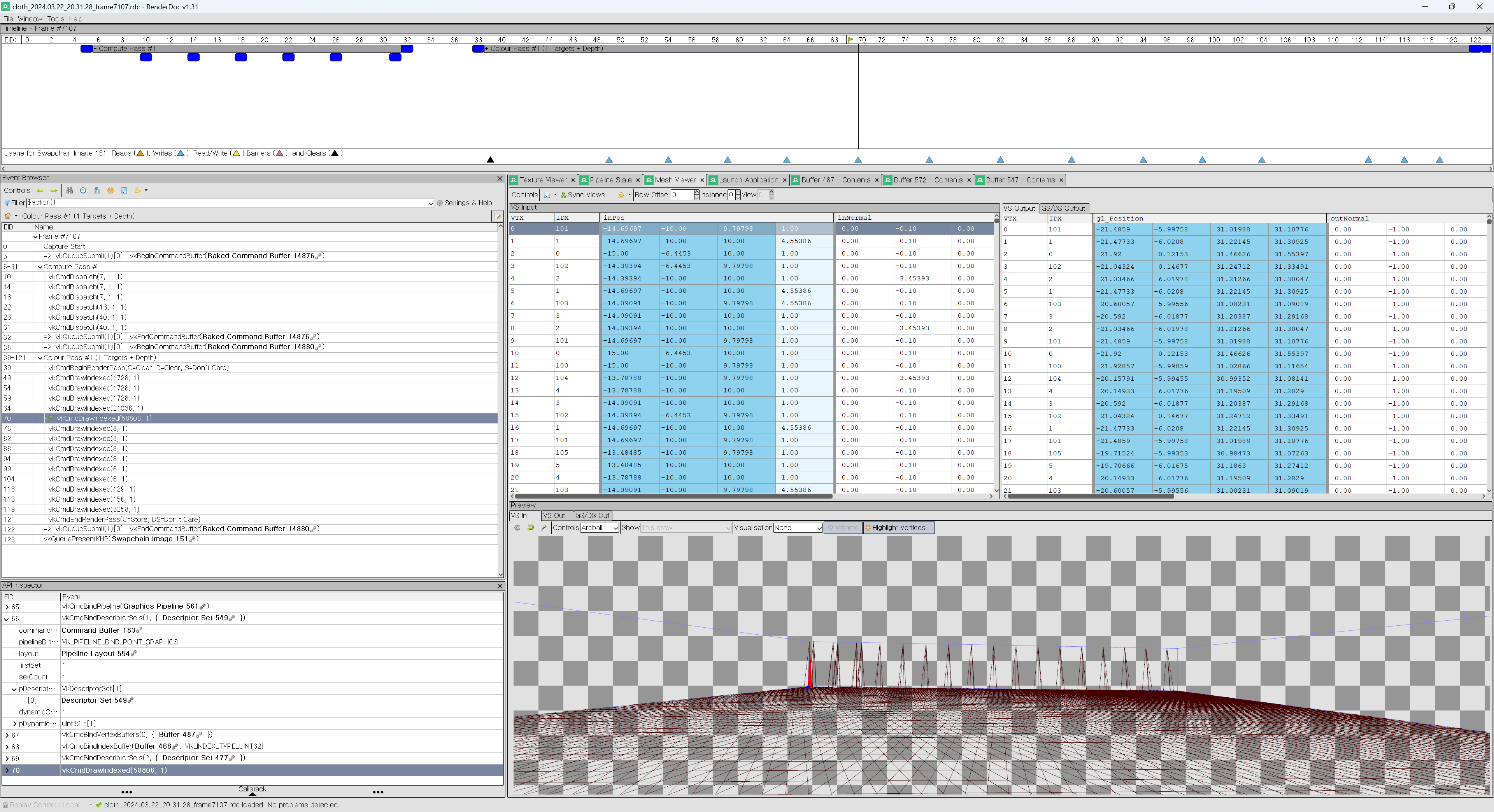 |
vertex buffer의 attribute 들은 위 처럼, vertex index와 함께 어떤 vertex가 render 되고 있는지를 같이 볼 수 있다. |
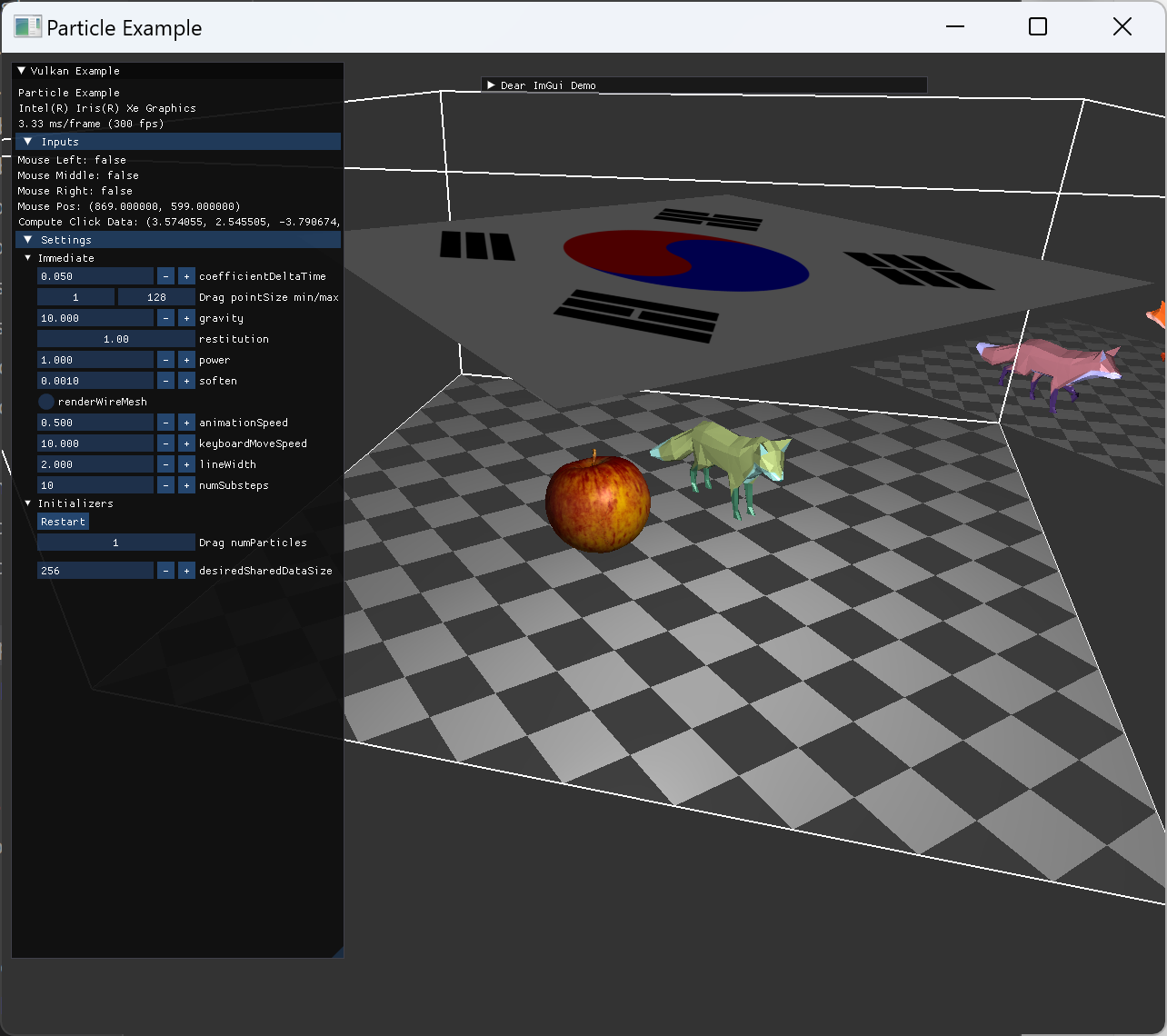 |
alignment 관련 수정을 해준 후, compute SSBO로 지정해준 pos와 normal, uv 등이 의도대로 설정되어서 rendering 시 원하는 texture와 vertex 형태가 나오게 됐다. |
Constraint compute
dispatch call 관련해서 처음에 size 관련된 오류가 발생했다. 이와 관련된 여러 limit이나 숫자들이 있는데, 내용을 좀 정리해두려 한다.
- 참고 검색 자료
- 한 dispatch call 한번에 여러 work group의 dimension이 명시된다.
- 각 work group에는 work item 여러개 (invocation)들이 실행될 것이다.
- 예를들어
dispatch(num_verts/256+1, 1, 1)이런 호출에서num_verts가 2560이라고 가정해보자 - work group은 11개가 될 것이고, 한 work group 안에는 256 (이건 따로 local_size_x로 명시해뒀다고 가정)의 invocation 이 있다.
-
maxComputeWorkGroupInvocations는 이 local_size_x * local_size_y * local_size_z에 연관된 limit이다. - 이 각각의 xyz는
maxComputeWorkGroupSize각자 xyz 별로 다른 제한도 있다. ex. (1024, 1024, 64) -
maxComputeWorkGroupCount는 dispatch 할때 work gorup의 수 제한이다.- ex (2147483647, 65535, 65535)
위 내용은 total invocations의 수에 대한 개념이고, 한번에 single execution core에서 동시에 실행가능한 invocations의 개념에는 subgroup 개념이 필요하다.
- 이게 중요한 이유는 결국 shared data를 잘 활용해서 최적화 할 때 실행 단위를 알아야 하기 때문.
- 한 subgroup내에서는 invocation들이 inter-communicate 가능하다.
- 한 lockstep에서 실행 가능한 invocation들 수와 같은 의미로 이해했는데, 이 subgroup 개념은 hardware support를 먼저 확인해야한다고 한다.
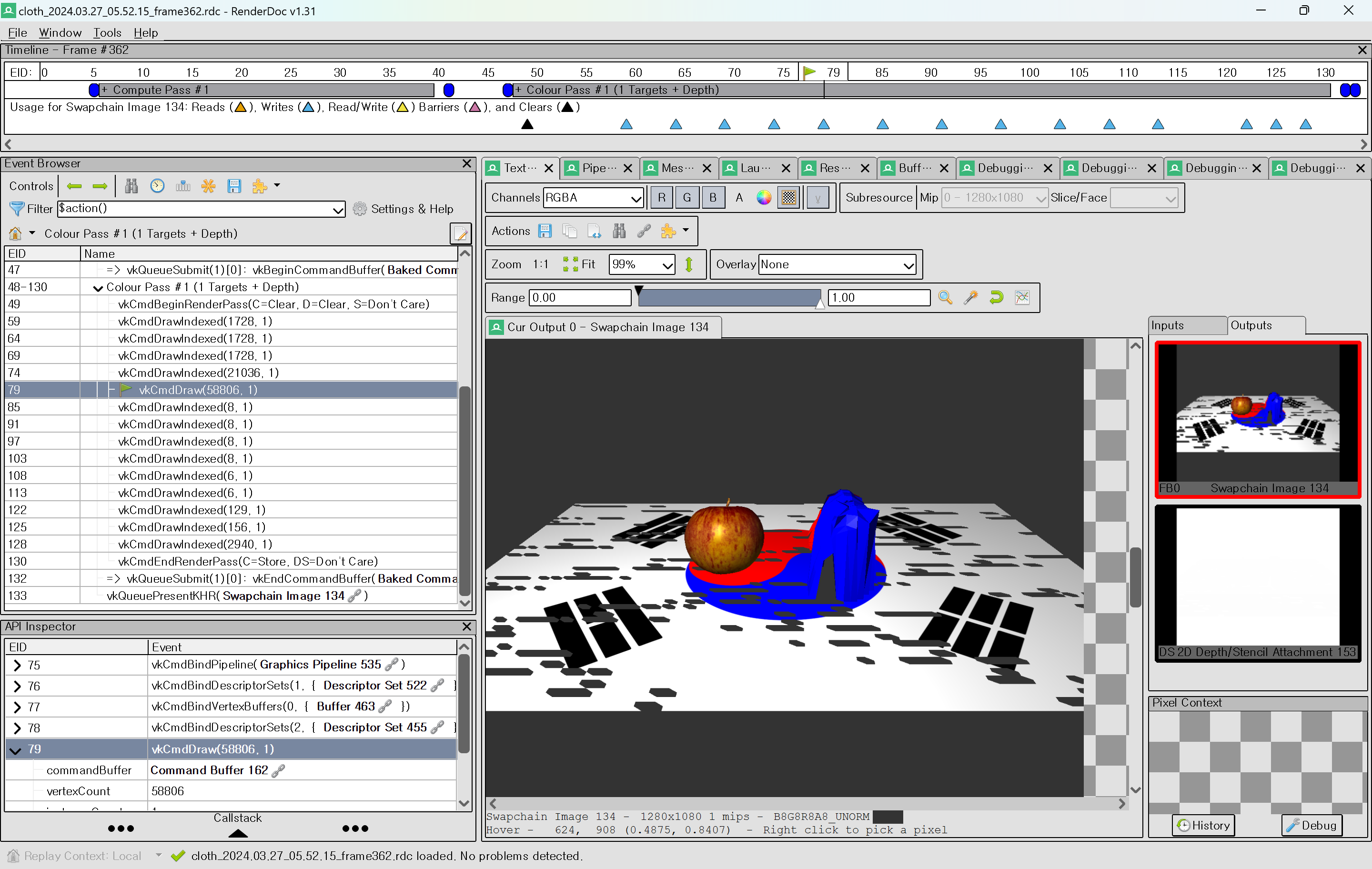
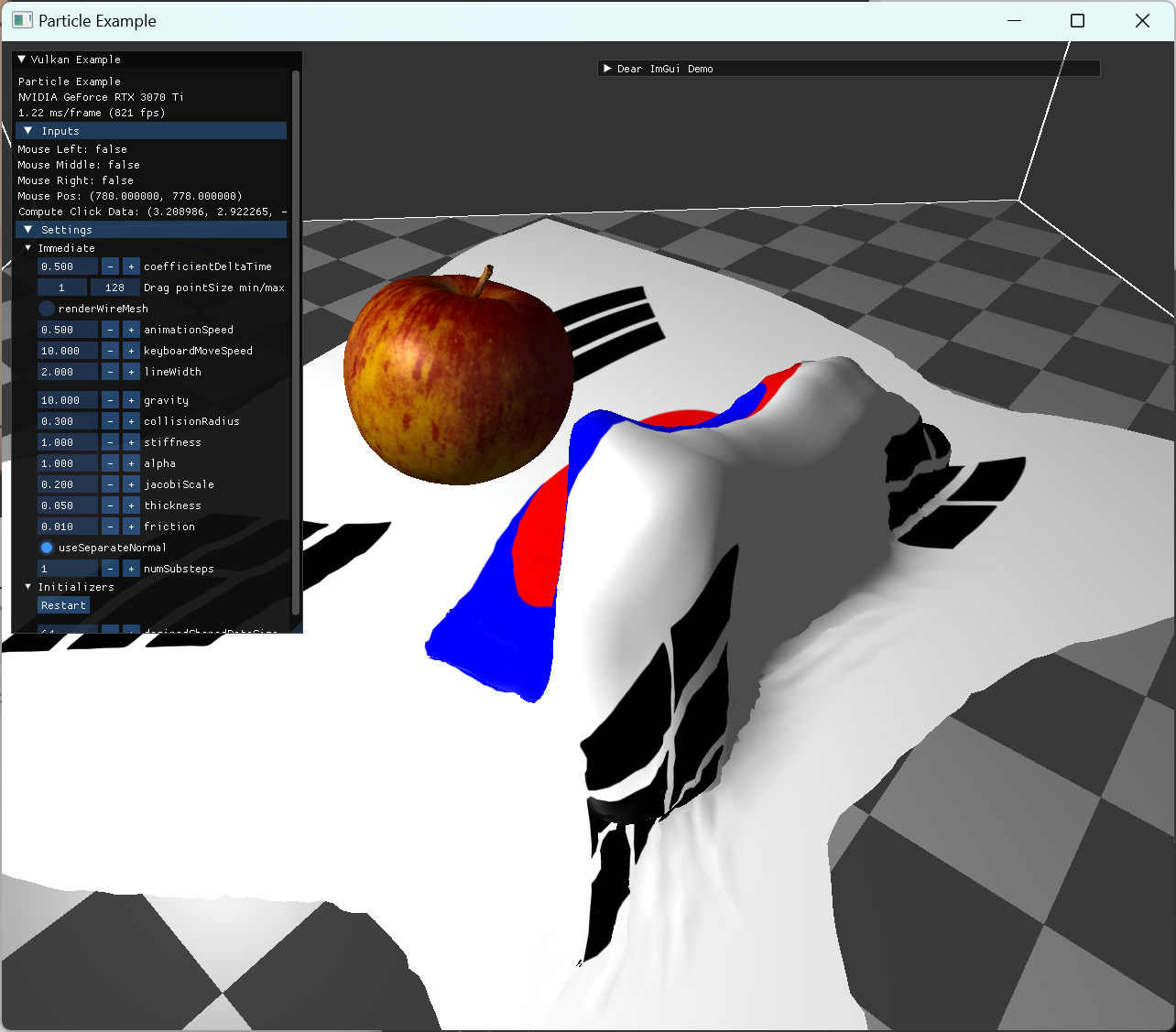
이후 model의 각 vertex와 일정 거리를 유지하는 간단한 collision 처리를 구현해서 dispatch했다. x를 cloth particle, y를 model vertex로 mapping 해서 호출했는데, 충돌 처리가 아예 적용되지 않는 문제가 생겼다.
 |
먼저 render doc에서 compute pipeline debugging 기능을 사용해서, distance가 일정 거리 이내엔 condition에 들어오는지를 확인했는데, 아예 분기로 들어오는 경우가 없었다. 그래서 거리 값을 normal의 w에 넣어 값을 확인해봤다. normal의 w에 보이듯 거리가 전부 예상보다 큰 값이 들어있어서 각 좌표를 확인해봤다. 확인 결과 모델 vertex의 좌표가 변환되지 않은채였는데, model matrix는 animation에서 곱해주지 않고, vertex shader에서 곱하도록 이전에 구현했던 부분이 원인으로 파악됐다. (이전에 NOTE를 써놔서 다행이다.) |
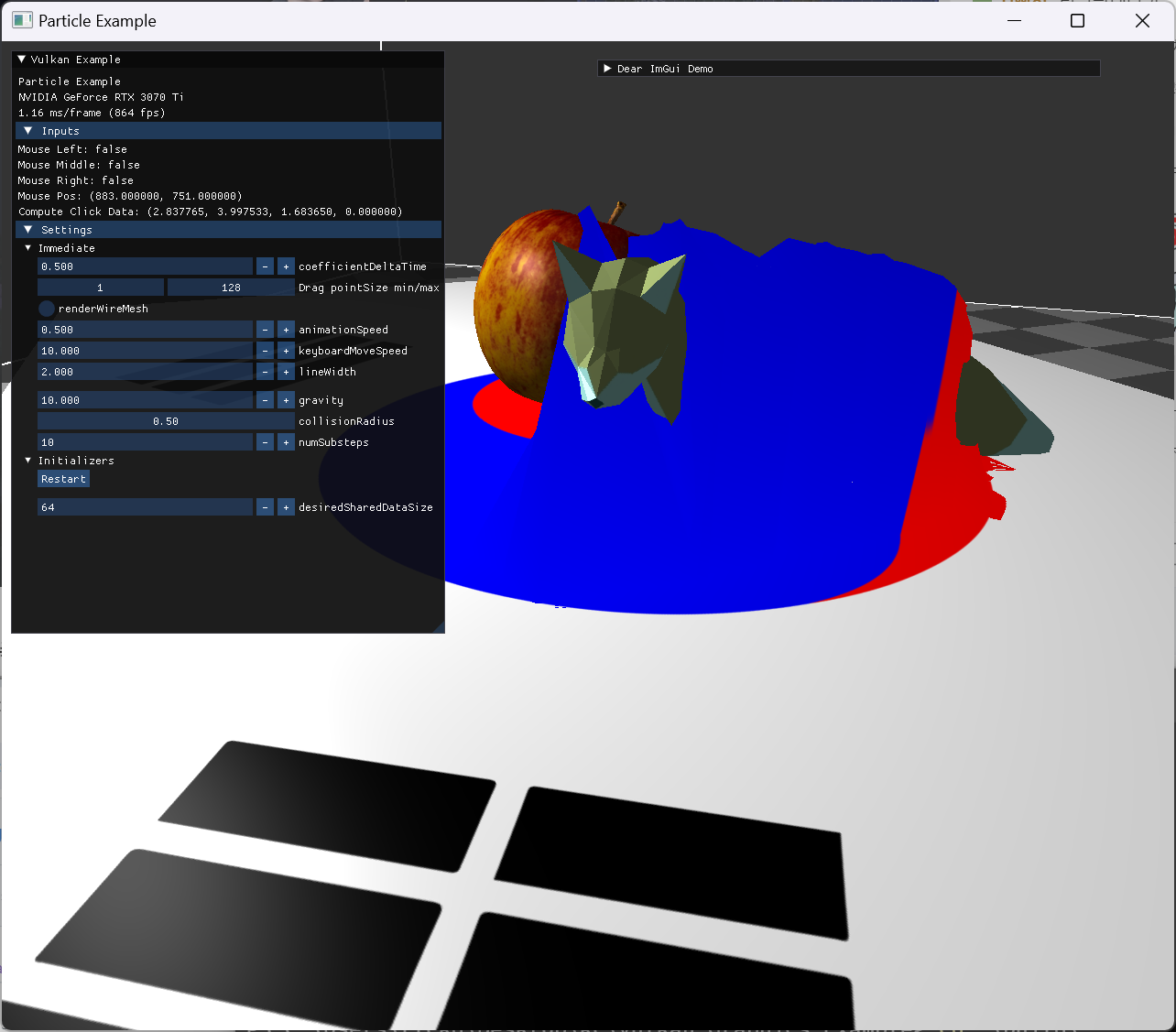 |
vertex shader에서 compute shader로 model mat 적용을 옮겨주니 지정한 거리 이내에 들어왔을 때 처리되는 것을 확인했다. 아직 normal update가 따로 없어서 눈으로 확인하기 한계가 있다. 하지만 단순한 collision 처리이기에 모델과 cloth가 뚫고 들어가는 현상은 확인했다. |
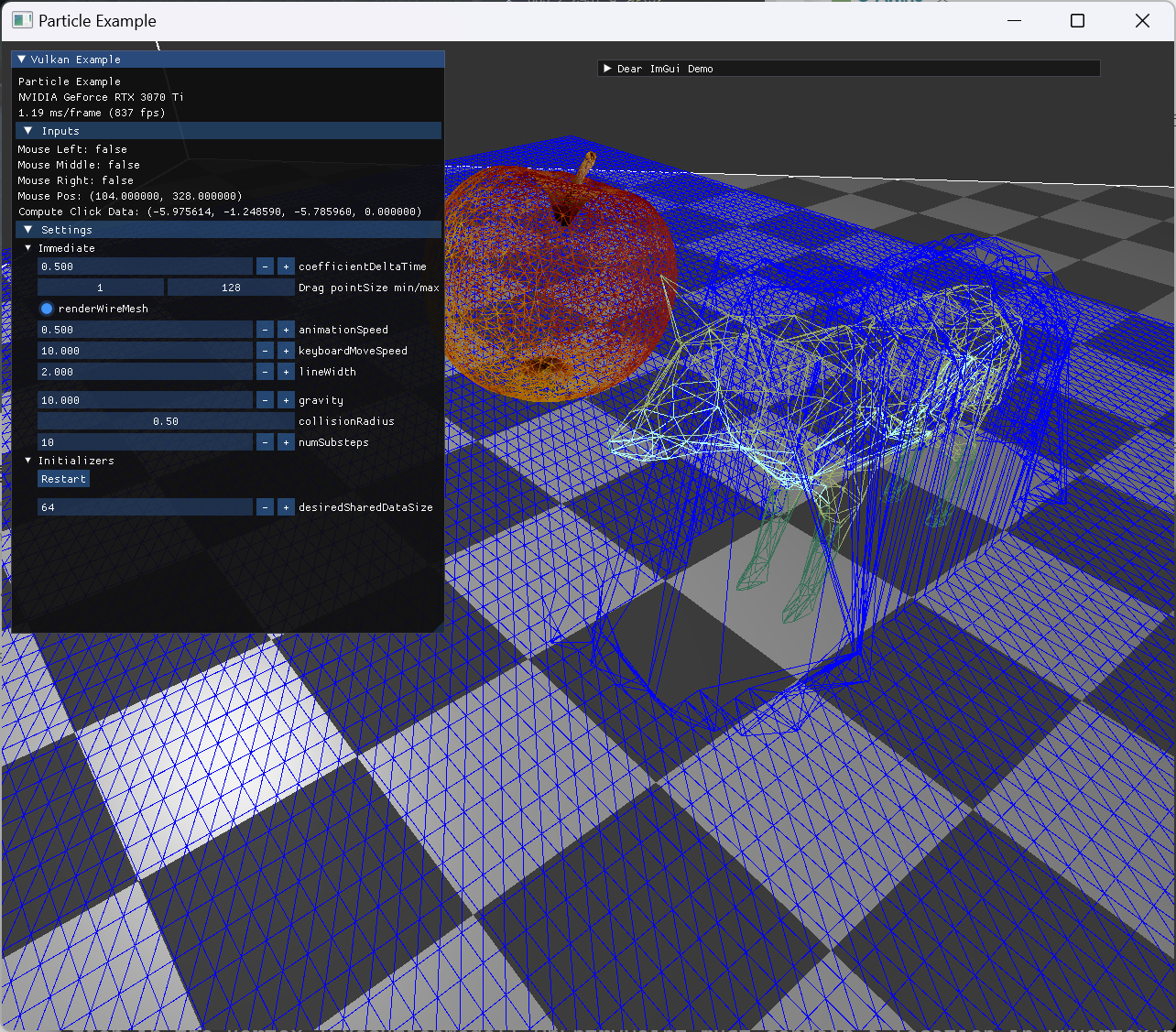 |
normal 관련 구현 전 까지는 wireframe 형태로 확인하는게 더 잘 보였다. |
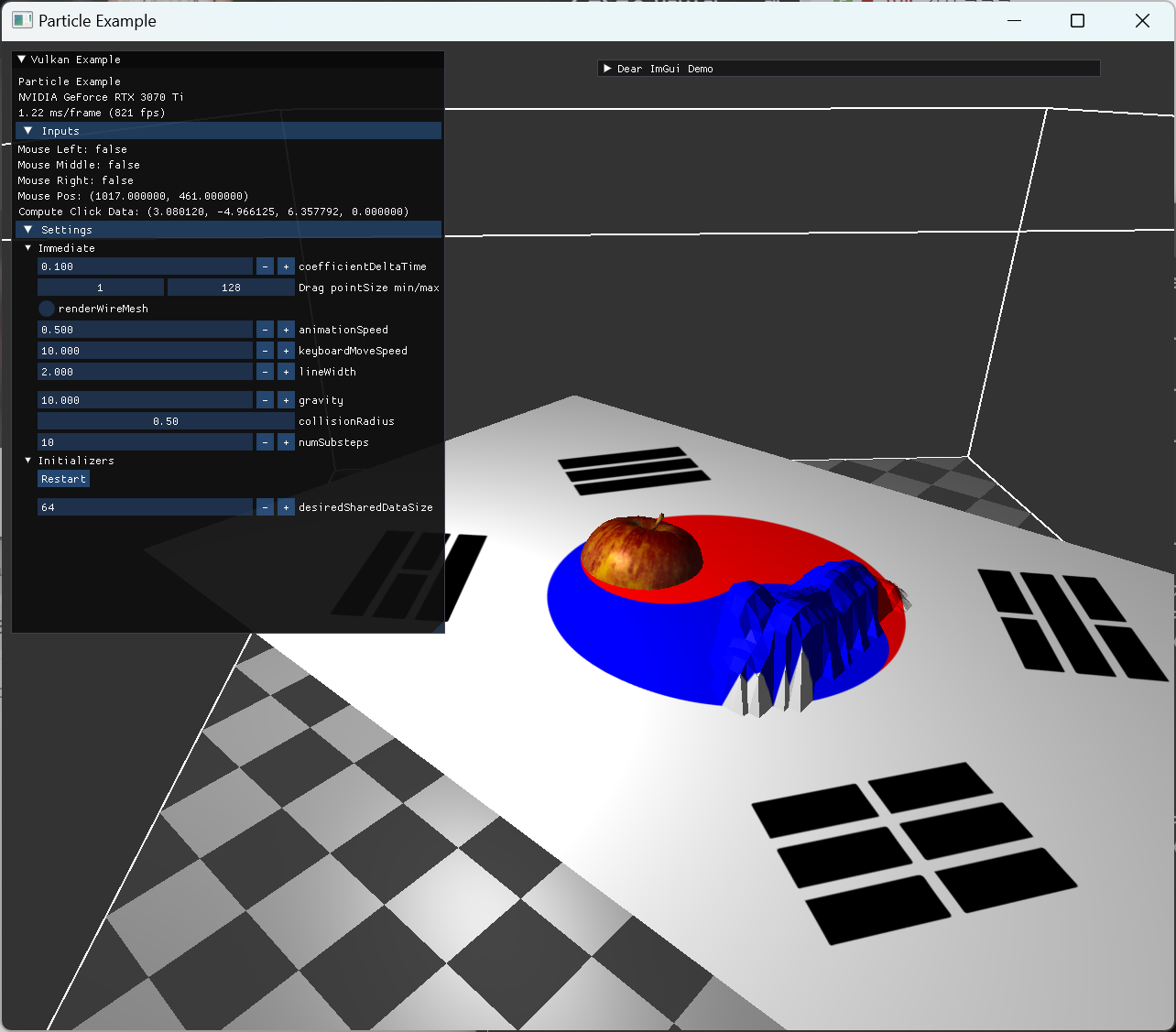 |
normal과 관련해서는, gltf export 시 normal을 포함하지 않도록 해서, 같은 position을 가지면 하나의 vertex가 되도록 내보내서 사용했다. 이렇게 구성된 모델을 쓰고, normal 계산은 이후 compute shader에서 직접해주는 방식으로 구현했다. compute 과정에서는 간단한 collision handle만 추가해줘서, 모델의 vertex들과 일정 거리안에 들지 않도록 처리된 모습이다. |
 |
이후 distance constraint 부분을 compute shader에 추가해주기 전에, particle 정보를 initialize 하는 부분을 cpu에서 하고 ssbo로 copy 해주는 부분을 변경했다. |
| 아직 constraint 초기화에서 rest length 계산은 cpu에 있는 상태인데, 일부 pos에 nan 값이 들어있어서 비어있게 보이는 문제가 발생했다. |
원인은 초기화 되지 않은 값이 pos에 들어가서 사용된 것이었다. prevPos attribute를 shader에서 초기화 해주는 부분이 빠져서 발생한 문제여서 쉽게 수정 가능했다. |
 |
constraint를 전달할 때, solve type (Jacobi or Gauss-Seidel) 정보는 각 constraint 별로 저장하지 않았고, constraint의 index 범위를 나눠서 pass에 저장해둔 independence 여부로 구분했다. 이 구조에서 solve type은 별도의 pipeline으로 구성을 했고, 이때 dispatch할때 계산할 constraint의 index들이 invocation ID로 쓰이기 때문에, 각 dispatch 시, first constraint 정보가 필요했다.
- solve type은 아예 specialization constants로 미리 구분해둔 별도의 pipeline으로 나눠놨다.
- constraint의 first와 num 정보를 push constants로 넣었서 각 dispatch command 제출에 사용했다.
- ubo 형태나 ssbo 형태로 bind가 가능할 지 생각해봤는데, 한번 recording 할 때 사용할 constraints들 group 수 만큼의 ssbo에 이 정보를 담아두면 가능할 것 같긴했다. dynamic 형태
- gltf 모델 load 구조에서 node마다 texture material image와 descriptor set이 있는 것 처럼.
- 어차피 전달할 data 크기가 적기때문에 push constant를 사용하기 적합하다고 생각했다.
- ubo 형태나 ssbo 형태로 bind가 가능할 지 생각해봤는데, 한번 recording 할 때 사용할 constraints들 group 수 만큼의 ssbo에 이 정보를 담아두면 가능할 것 같긴했다. dynamic 형태
Triangle mesh & Normal vector
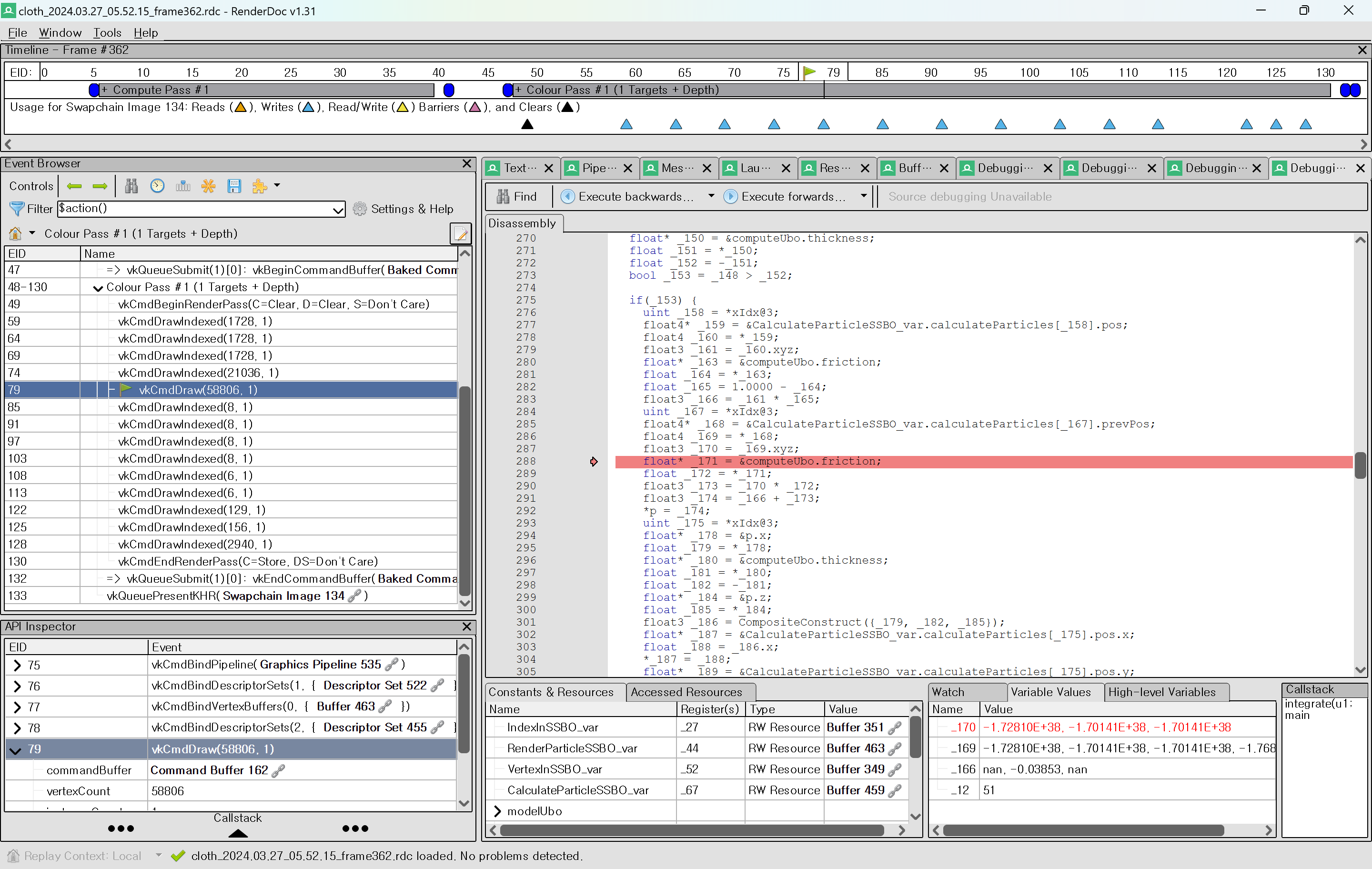
distance constraints를 처음 적용했을 때, 이상한 결과가 나왔다. 처음에는 simulation precision 문제로 예상했는데, rest length 자체가 내가 지정해준 방식과 달라보였다.
- rest length check
- solve dist constraint 과정 디버깅
rest length 계산은 처음에는 cpu에서 진행하다가, 초기화 부분을 particle 과 마찬가지로 compute shader에서 계산하도록 옮겨주었고, 이부분을 render doc에서 capture 해서 확인했다.
 |
distance constraint 추가 후, 각 particle 거리가 rest length로 유지되도록 stretch constraint가 적용된 모습이다. 하지만 잘못된 거리가 들어가있는 결과이다. 처음에는 simulation의 float이 precision 문제가 있는 것으로 생각해서 double precision으로 늘려봤지만, 문제가 해결되지 않아 되돌렸다. |
 |
초기화 과정을 render doc에서 캡쳐하기 위해서는 직접 frame을 지정해서 launch가 가능하다. |
 |
constraint ssbo의 데이터 값인데, 앞 두개는 id0, id1을 마지막 항목이 rest length distance를 저장하고 있어야 한다. 이때 5.45라는 예상되지 않은 값이 들어있는 것을 확인했다. |
 |
디버깅과 buffer 내용을 보고 모델의 vertex index가 의도와 다르게 정렬됐다는 사실을 알게됐다. 해당 index에 맞는 vertex를 blender를 열어서 확인했다. 의도된 순서라면 y로 먼저 정렬하고, 같은 y는 x 순으로 정렬되어 있어야 하는데, 그렇지 않았다. |
 |
blender에 추가했던 model의 vertex index를 정렬하는 파이썬 스크립트에서 해당 부분의 (-y, x)를 출력해봤다. blender에서 position float의 precision문제로 제대로 정렬이 안됐던 문제였고, 이를 4자리 까지로 줄여서 문제가 사라진 것을 확인했다. |
아래는 사용한 blender script 이다.
# https://blender.stackexchange.com/questions/36577/how-are-vertex-indices-determined/36619#36619
import bpy
import bmesh
import random
ob = bpy.context.object
assert ob.type == "MESH"
me = ob.data
bm = bmesh.from_edit_mesh(me)
# https://docs.blender.org/api/current/bmesh.types.html#bmesh.types.BMesh.verts
print("====== sort vertex id ======")
print(len(bm.verts))
print(bm.verts[449].index)
print(bm.verts[449].co)
print(bm.verts[300].index)
print(bm.verts[300].co)
posList = []
# https://docs.blender.org/api/current/mathutils.html
for v in bm.verts:
# upto3
coord = v.co.to_tuple(4)
posList.append((-coord[1], coord[0]))
# precision check
print(posList[300])
print(posList[449])
sortedIndices = [item[0] for item in sorted(enumerate(posList), key=lambda x:x[1])]
for rank, i in enumerate(sortedIndices):
bm.verts[i].index = rank
bm.verts.sort()
bmesh.update_edit_mesh(me)
bm.verts.ensure_lookup_table()
print("====== after sort ======")
print(bm.verts[449].index)
print(bm.verts[449].co)
print(bm.verts[300].index)
print(bm.verts[300].co)
이후 constraint size에 문제가 있던 오류를 수정한 이후로, 의도된 결과를 확인할 수 있었다.
확인을 위해 normal vector update를 flat shading 과 average normal을 써서 smooth shading이 되도록 두가지 옵션을 구현했다.
 |
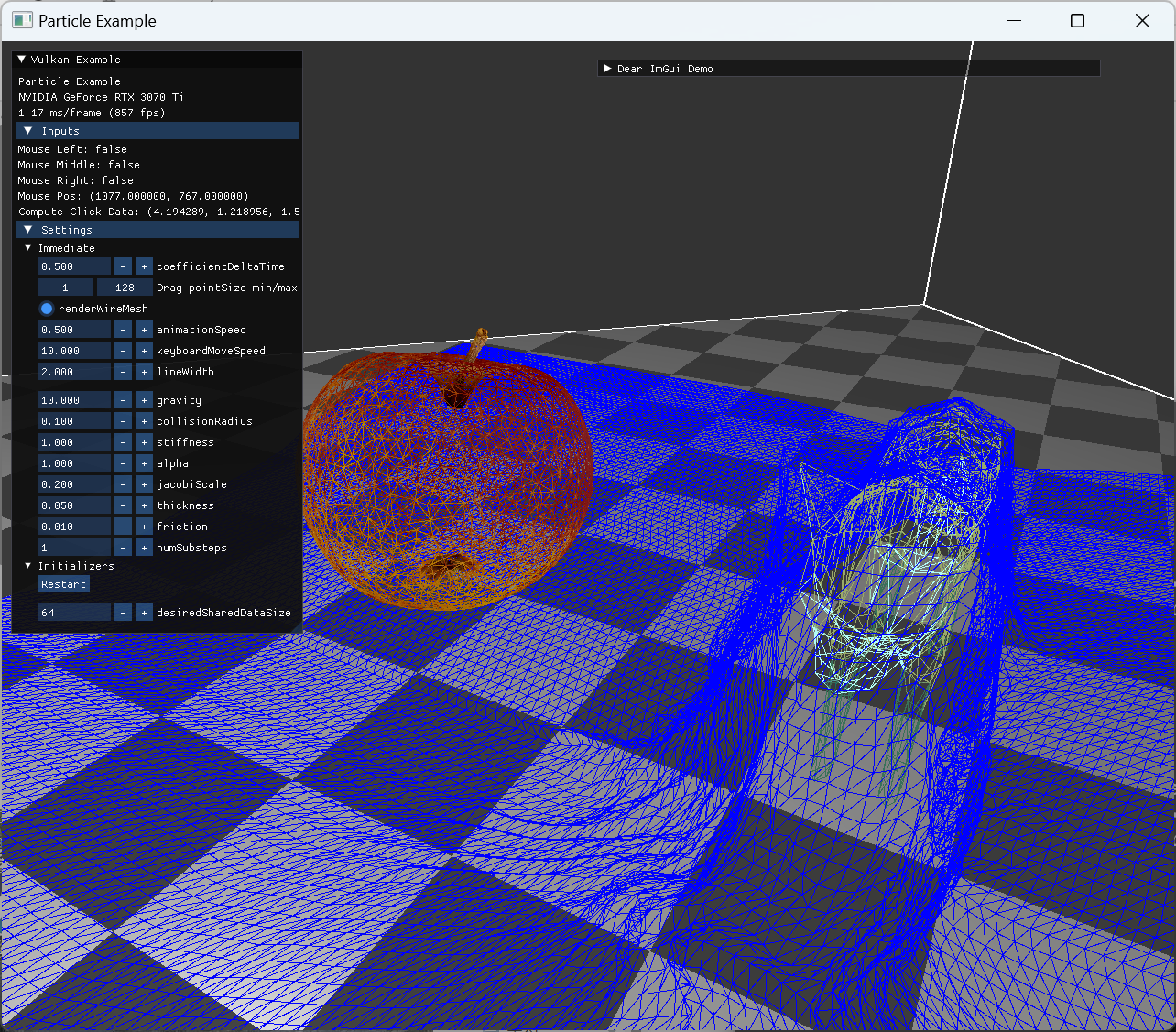 |
stretch constraint demo
stretch constraint (grid 형태에서 인접한 두 particle 간 rest length 만 유지되도록 하는 constraint)만 추가한 모습이다. bending이나 shear는 빠져있으서 실제 cloth와는 이질감이 드는 부분이 있을 수 있지만 어느정도 눈에 보이는 결과를 얻기 시작했다.
Atomic operations
atomic add가 normal update에서도 사용되고, constraint solver 에서도 사용됐는데, laptop에서는 atomic add가 하드웨어에서 지원되지 않아서 프로그램이 아예 실행되지가 않았다.
이와 관련해서, vulkan feature와 extension관련된 코드를 리팩토링해줬고, logical device 생성시에 atomic add 관련 부분을 명시해줬다.
vulkan에는 instance extension도 (device extension)있는데 이와 헷갈렸던 것 같아 개념을 좀 찾아봤다.
- instance extension은 vulkan loader support가 필요한 것들이고, graphics card와는 독립적인 개념이다. loader는 vulkan api에 포함된 내용.
- device extension을 사용하려면, physical device가 그 기능을 support 하는지 먼저 확인하고, logical device 생성할 때 명시하면 된다.
- validation layer 사용시 debug extension을 추가하는 내용 샘플
- https://docs.vulkan.org/guide/latest/enabling_features.html#enabling-features
- https://registry.khronos.org/vulkan/specs/1.3-extensions/man/html/VkPhysicalDeviceShaderAtomicFloatFeaturesEXT.html
atomic add 가 지원되지 않을때, 그냥 프로그램을 종료해도 되는데, 우회할 수 있는 방법이 있을지 조금 확인을 해봤다.
atomic load/store나 atomic exchange는 사용이 가능해서 이 operation들을 잘 사용하면 glsl 상에서 해결 가능한 방법이 있지 않을까 싶어서 찾아보던 중, spinlock을 구현해서 사용하는 방법이 있어 추가해봤다.
결론부터 말하면 실행은 확인했는데, 코드 구조에 따라서 결과가 이상한 경우도 있었고, (compiler optimizer에 의해서 뭔가 달라지는 것 같음), invocation들의 execution order를 지정해주려는 방식 자체가 공식 spec에 undefined behavior라는 의견도 있었다.
- https://www.gamedev.net/forums/topic/681459-compute-shader-memory-barrier-fun/5306851/?page=1
- https://community.khronos.org/t/using-spinlock-to-control-image-read-writes/69299
- https://stackoverflow.com/questions/51704683/glsl-per-pixel-spinlock-using-imageatomiccompswap
구현한 내용은 다음과 같다.
- shared data를 하나 둬서 spinlock으로 쓴다 (여러개 둬도 될 것 같음)
- 실제로 병렬로 실행되는 thread 개념이 subgroup 단위인데, 이 subgroup은 한 local work group 내에서 나눠진 것임
- 결국 동시에 실행되는 단위나 접근은 local work group 내에서만 신경쓰면 된다고 생각해서 이를 공유하는 shared data를 spinlock으로 써서 하나의 invocation만 critical area에 접근하도록 atomic exchange로 감싸줬음.
- atomic 연산에 memory scope와 semantics 개념이 들어가는데,
- scope: atomicity를 지켜야할 shader invocation들의 범위
- 다른 어떤 agent들에 대해서 atomic 해야하는지를 지정
- device, workgroup, subgroup, invocation, queue family
- semantic: 다른 메모리 접근들의 순서를 제한하는 flags
- relaxed, acquire, release, acquire release
- storage semantic
- buffer, shared, image, output
- https://registry.khronos.org/vulkan/specs/1.3-extensions/html/chap53.html#memory-model-scope
- https://github.com/KhronosGroup/GLSL/blob/main/extensions/khr/GL_KHR_memory_scope_semantics.txt
atomic operation 관련한 개념을 좀 더 살펴보는 계기가 됐는데, 기능적으로 이런 spinlock을 invocation들의 순서를 강제하기 위해 shader 내부에서 쓰는 것은 지양해야하는 방식인 것 같아 실험적으로 구현해본 것에 의의를 두고 넘어갔다.
 |
atomic add 관련 제대로된 처리가 안되어 있을때는, normal이 계속 바뀌면서 밝기가 flickering 하는 현상이 있었는데, 사라진 모습니다. 하지만 normal에 의한 밝기가 미묘하게 밝은 듯 한 느낌이 있다. |
 |
fragment shader에서 texture를 쓰는 대신, back face 구분도 지정해줬다. |
 |
normal 관련 initialize를 제대로 해주지 않는 오류가 있어서 수정해주고 나니, 이전 보다 더 명확한 면들의 밝기 차이를 볼 수 있었다. |
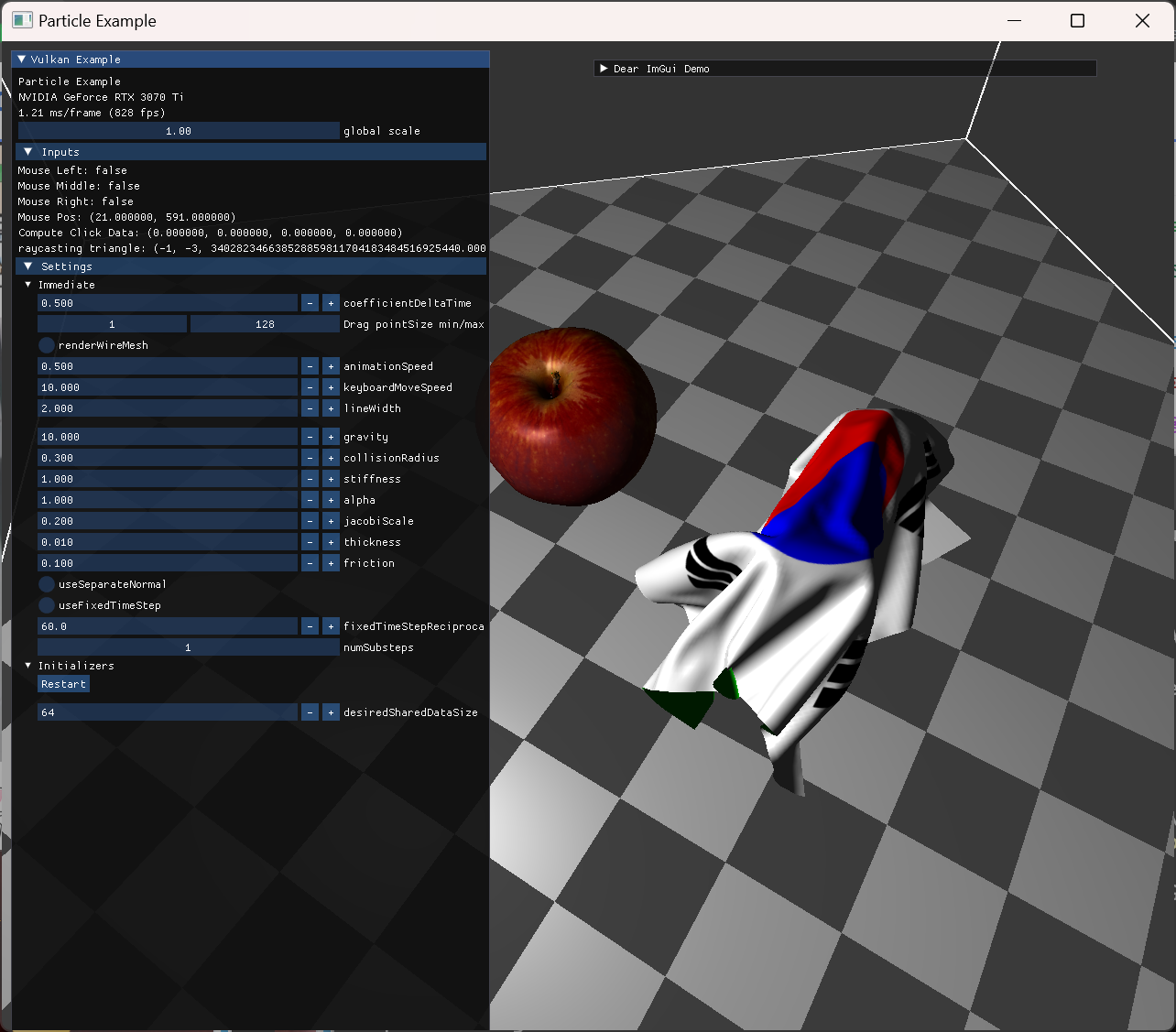
Mouse Ray casting interaction
fixed point는 임시로 hard-coding 된 형태로 inv mass를 0.0으로 줘서 동작을 확인했다. (상단 좌우 두 점을 고정했다.)
이후 mouse interaction은 계획대로 GPU 상에서 삼각형과 barycentric coords 계산을 통해 처리했다.
- click 정보로부터 ray start와 ray dir를 compute shader로 넘김. ubo 사용
- compute shader에서 ray와 모든 cloth triangle로의 projection 거리를 계산.
- 삼각형과 ray가 만나지 않으면 -1.
- 이를 위해 barycentric coords 이용
- cpu에서 거리 정보만 copy해서 가장 가까운 depth가 몇인지를 확인한다.
- 그 triangle주의 임의 한 particle만 depth 만큼 길이를 유지한 채로, 옮긴다. (integrate 시)
- 옮길 정보 역시 ray start와 dir로 ubo로 넘겨준 값 사용.
- 이 과정이 compute ubo update에서 depth 계산이 이뤄져야하는데, 이때 single time submit으로 compute queue에 제출하고 기다리도록 구현을 했다.
- 사실 이 부분 구현을 어디에 둬야하는지 고민이 좀 됐는데, 우선 간단하게 구현하는 대신 compute queue가 매 frame 계산되길 기다려야하므로 double buffering 구현 목표와 상충되게 됐다.
- 이 부분을 제대로 구현하려면 async compute 관련 구현을 먼저 익혀야할 것 같은데, 이후 새로운 주제로 알게되면 다시 언급할 예정이다.
 |
 |
Geometry shader
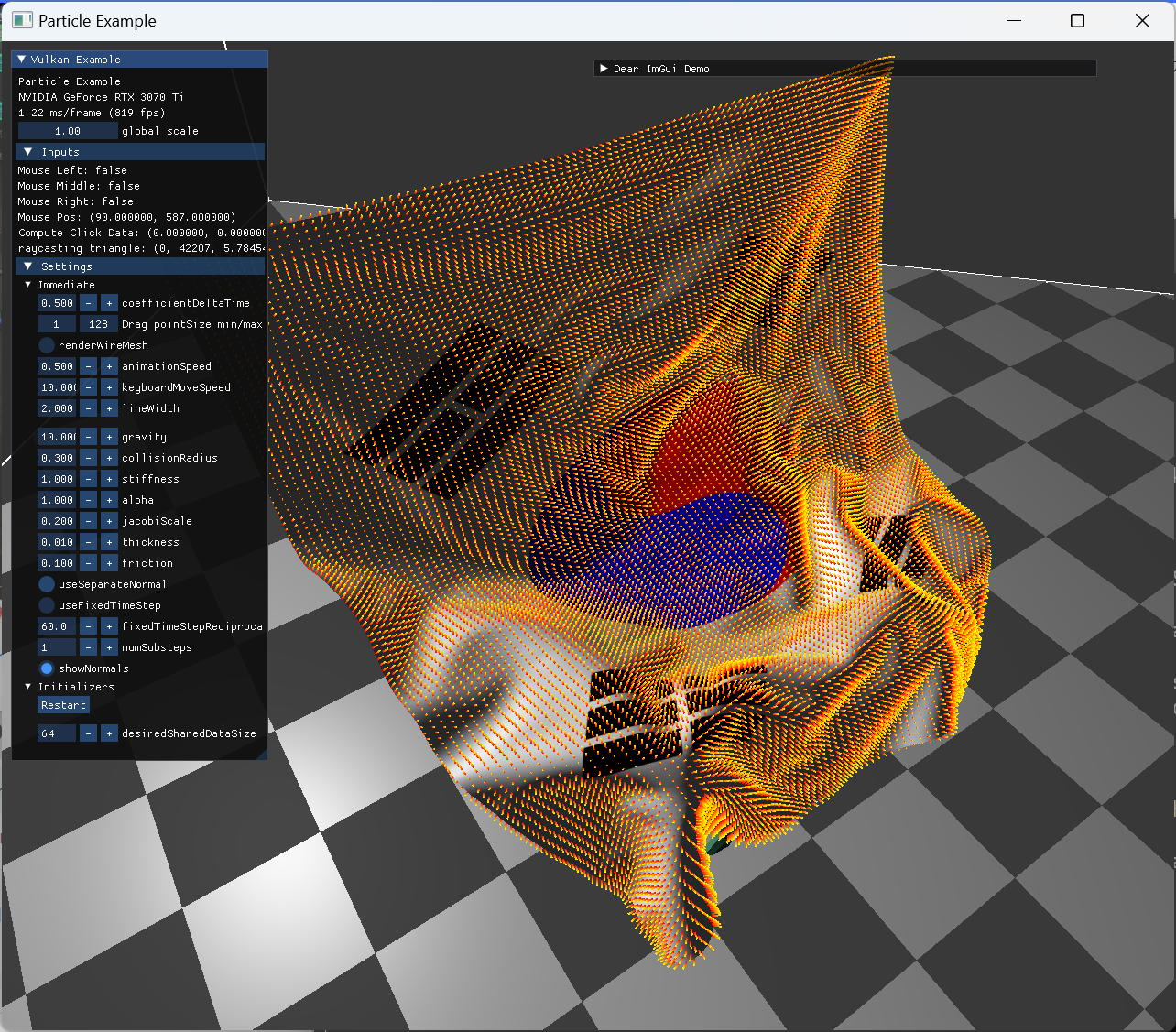
구현한 cloth render시, smoothing shading형태의 normal을 사용하면, 일부 둥글게 나와야할 부분에 이상한 패턴이 보이는 경우가 발생했다.
average 한 normal에서만 보이는 문제이고, flat shaing에서는 문제가 없어서 normal의 값이 문제는 아닌것으로 봤지만, 우선은 좀 더 확인을 해봤다.
normal을 간단하게 확인하는 방식으로 geometry shader를 구성해서 normal line들을 생성하는 방법이 있어 추가해봤다.
geometry shader는 입력으로 primitive를 받아서 새로운 primitives를 출력해주는 shader stage인데, 이런 normal debugging에 자주 쓰인다고 한다.
- 새로 normal을 위한 buffer나 descriptor set을 구성하면 번거롭다.
- geometry shader가 성능상 좋지 않아서 debugging용도로만 자주 쓰인다고 한다.
- input primitive를 받아서 새로운 primitive를 방출할 수 있는데, 여러개를 하거나 방출을 안할 수도 있따.
- 이번에는 vertex 하나를 두개의 vertex primitive로 보내서 normal line을 만들때 쓴다.
- geometry shader stage는 vertex shader stage와 raterization 사이에서 일어나는데, tesselation shader와 유사하지만 더 유연하다고 한다.
 |
smoothing shading을 위한 normal을 시각화 한 것. normal이 한 vertex에 하나 씩만 있다. |
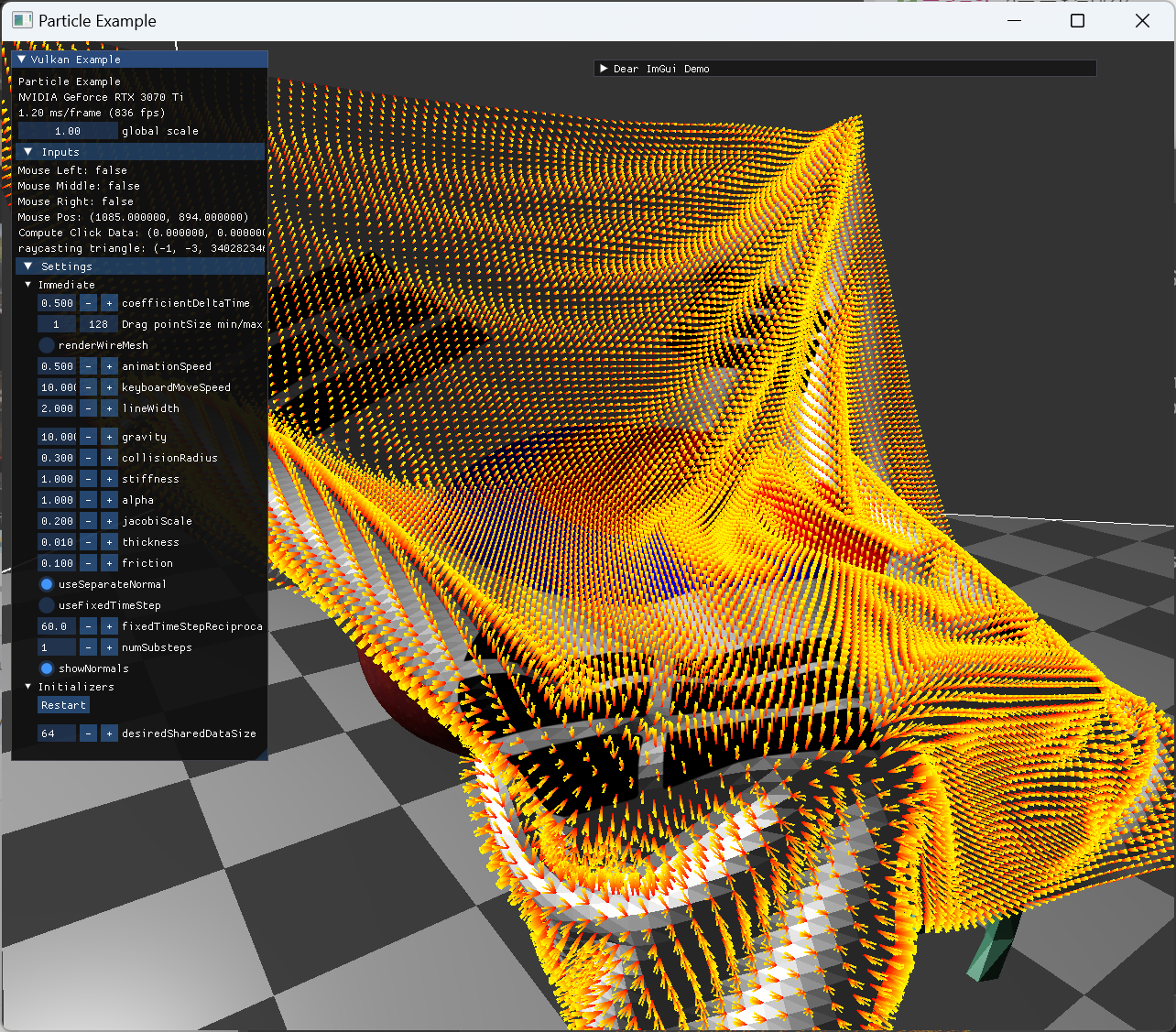 |
flat shading을 위한 경우는, 각 triangle 면 마다 normal이 있어야 하므로, 한 vertex당 최대 6개 까지 normal이 보인다. |
normal에는 문제가 없는것을 눈으로 확인했다.
혹시 모를 미세한 수치차이로 인한것인지 의심되어 interpolation qualifier 관련된 문제가 있는지 찾아봤지만 비슷한 케이스를 찾지 못했다.
shaing 방식의 한계인지도 모르겠어서 검색해본 결과 비슷한 예시를 찾았다.
답변에는 slerp 관련 문제라고 하는데, 결국 normal 각도가 너무 커서 rasterize에서 interpolation시 오차가 발생한 것으로 설명한다.
간단하게 이것이 원인이 맞는지 검증해볼 방법이 생각나지 않아서 질문 글의 stanford bunny 모델을 받아서 확인해봤는데, blender에서도 비슷한 현상이 보였다.
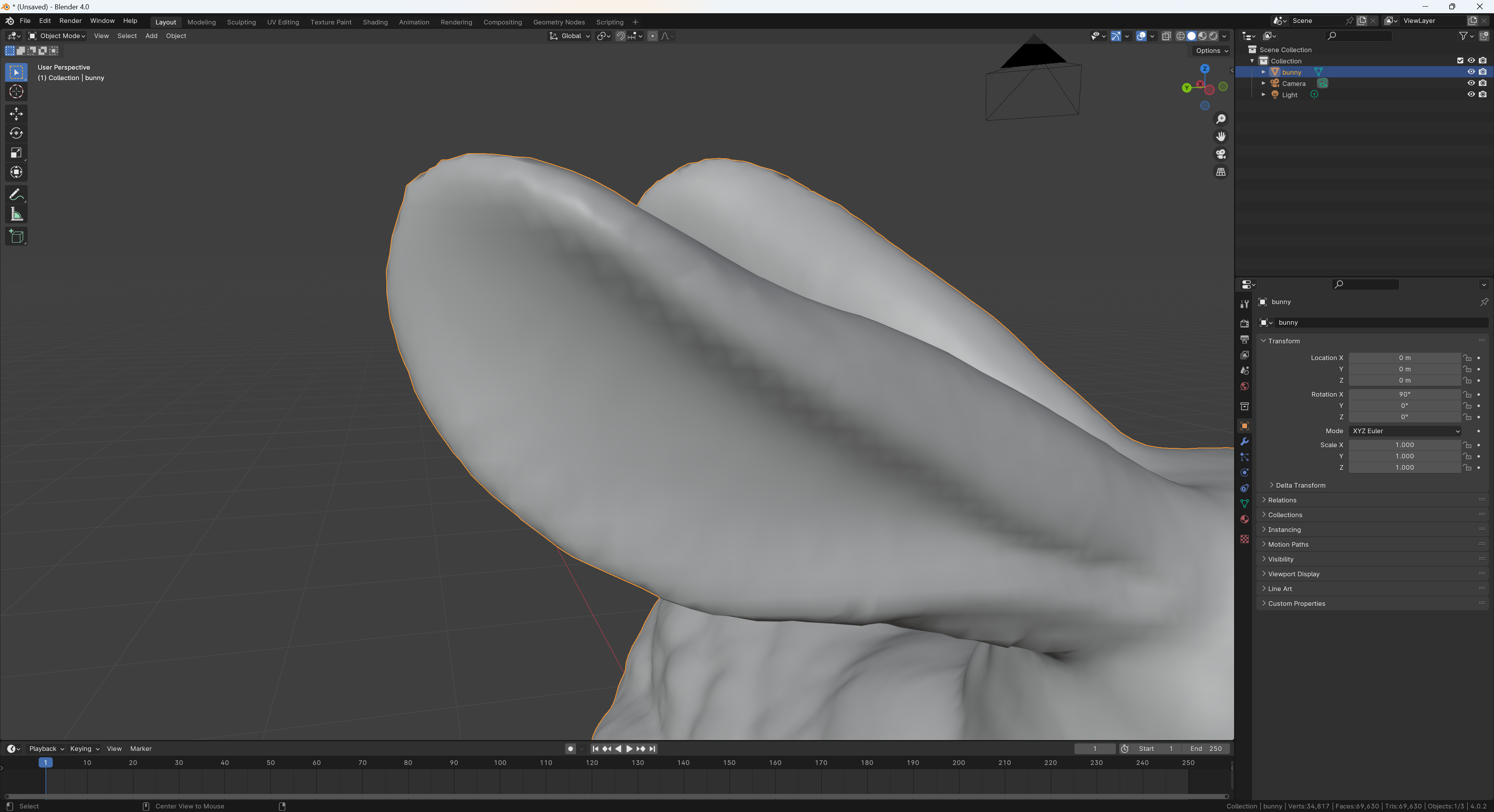
결국 cloth normal이나, shading 구현에 오류가 있는 것은 아니라고 안심하고 이런 패턴이 발생하는 원인은 파악하지 못한채로 넘어가기로 했다. 라이팅 방식이나 rasterizer의 interpolation 방식에서 오는 한계가 아닌가 싶은데 그런것 치곤 cloth에서 저런 패턴이 너무 자주 보여서 원인 파악이 좀 더 필요한 상태다.
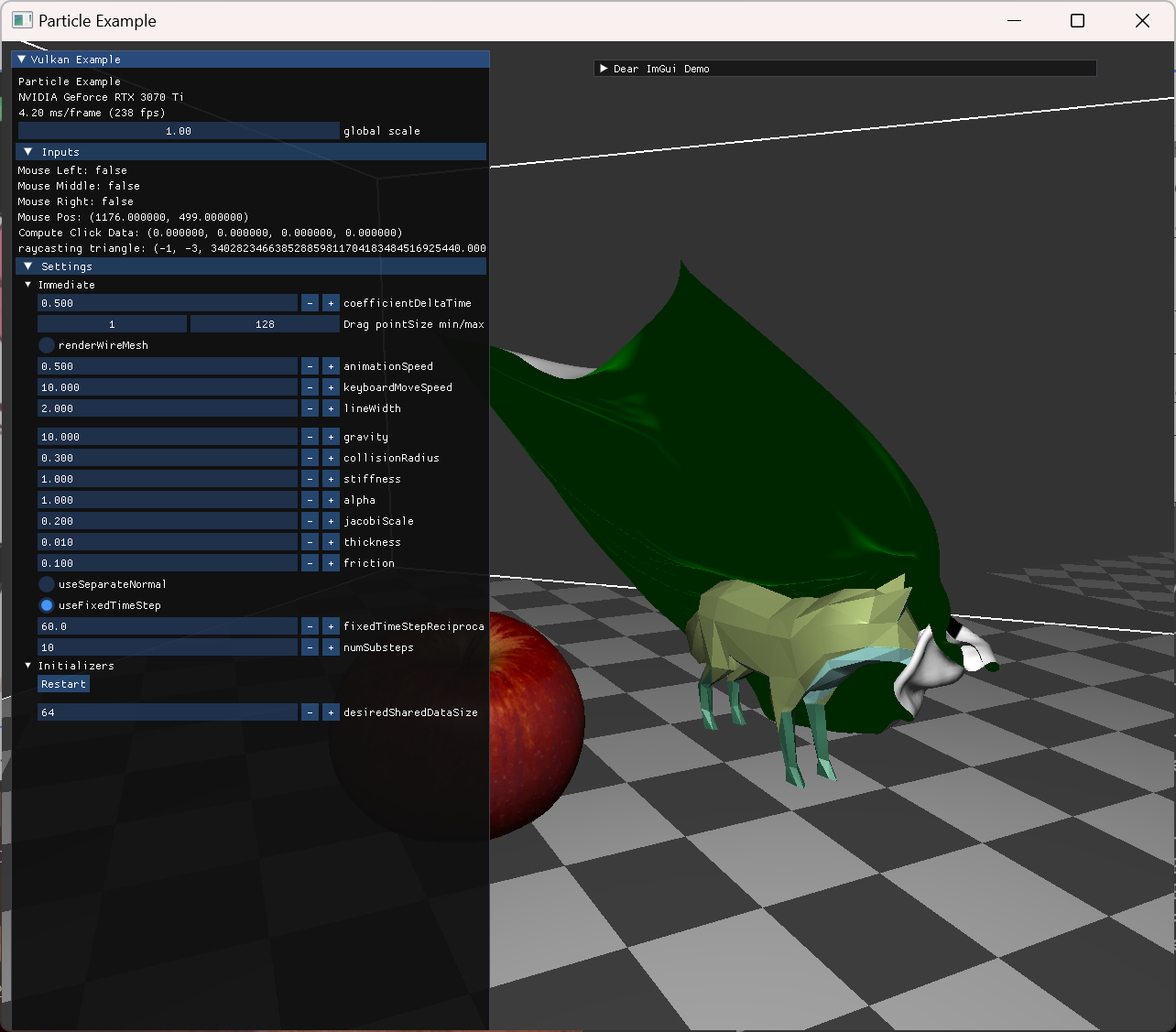
Results & Further study
최종 결과로 확인한 장면들이고, 아래 demo에 해당 영상을 넣어놨다.
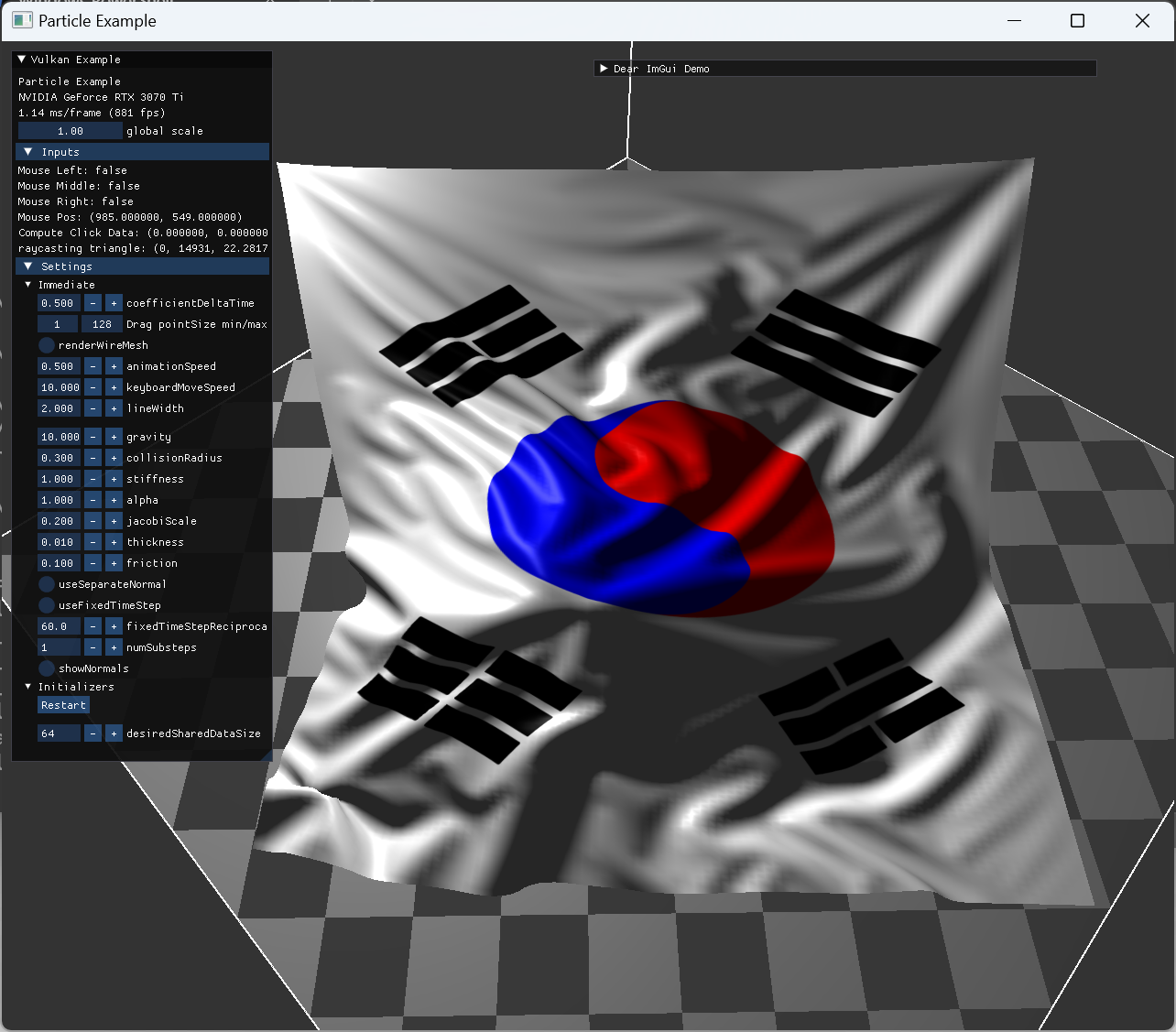 |
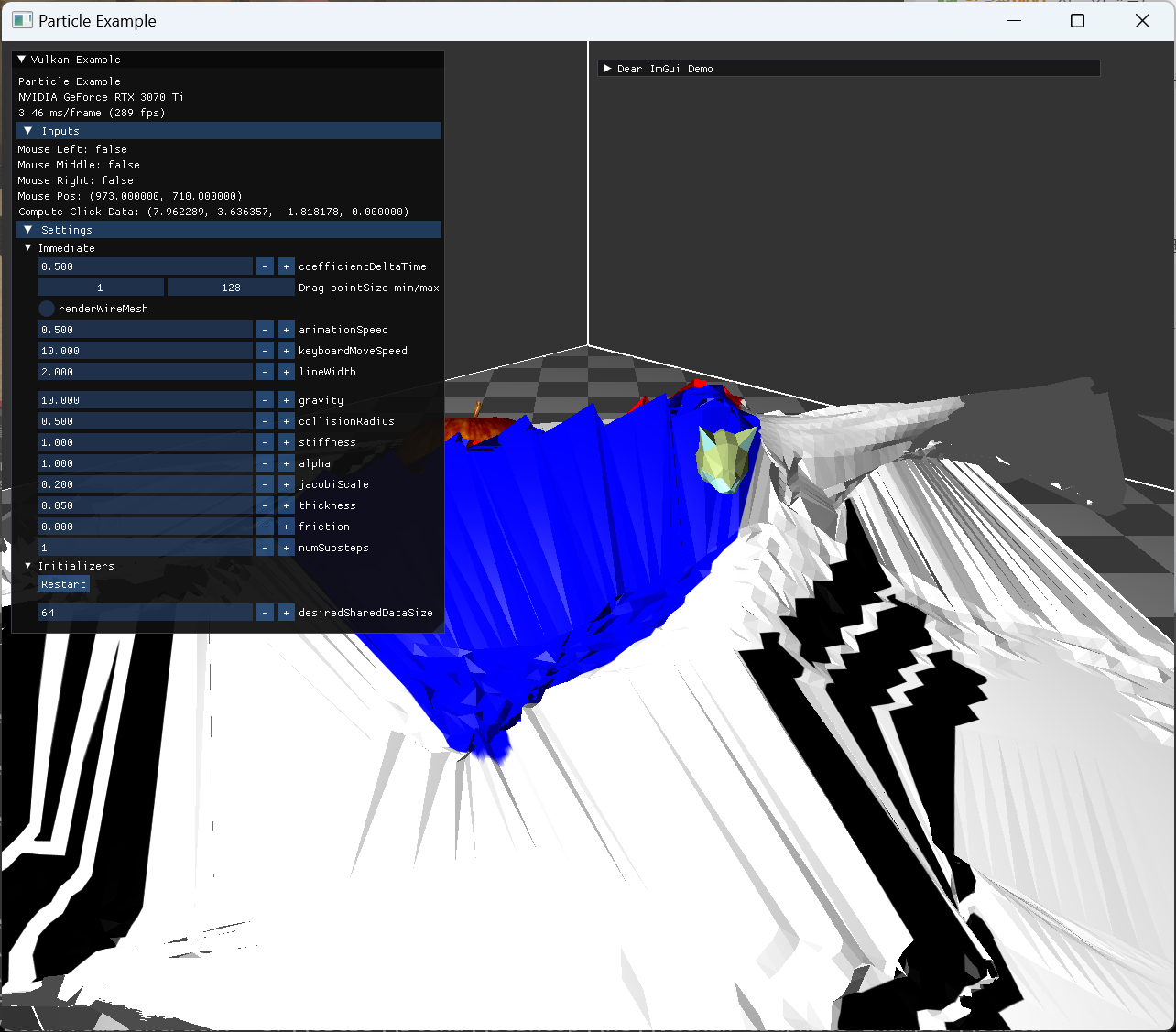
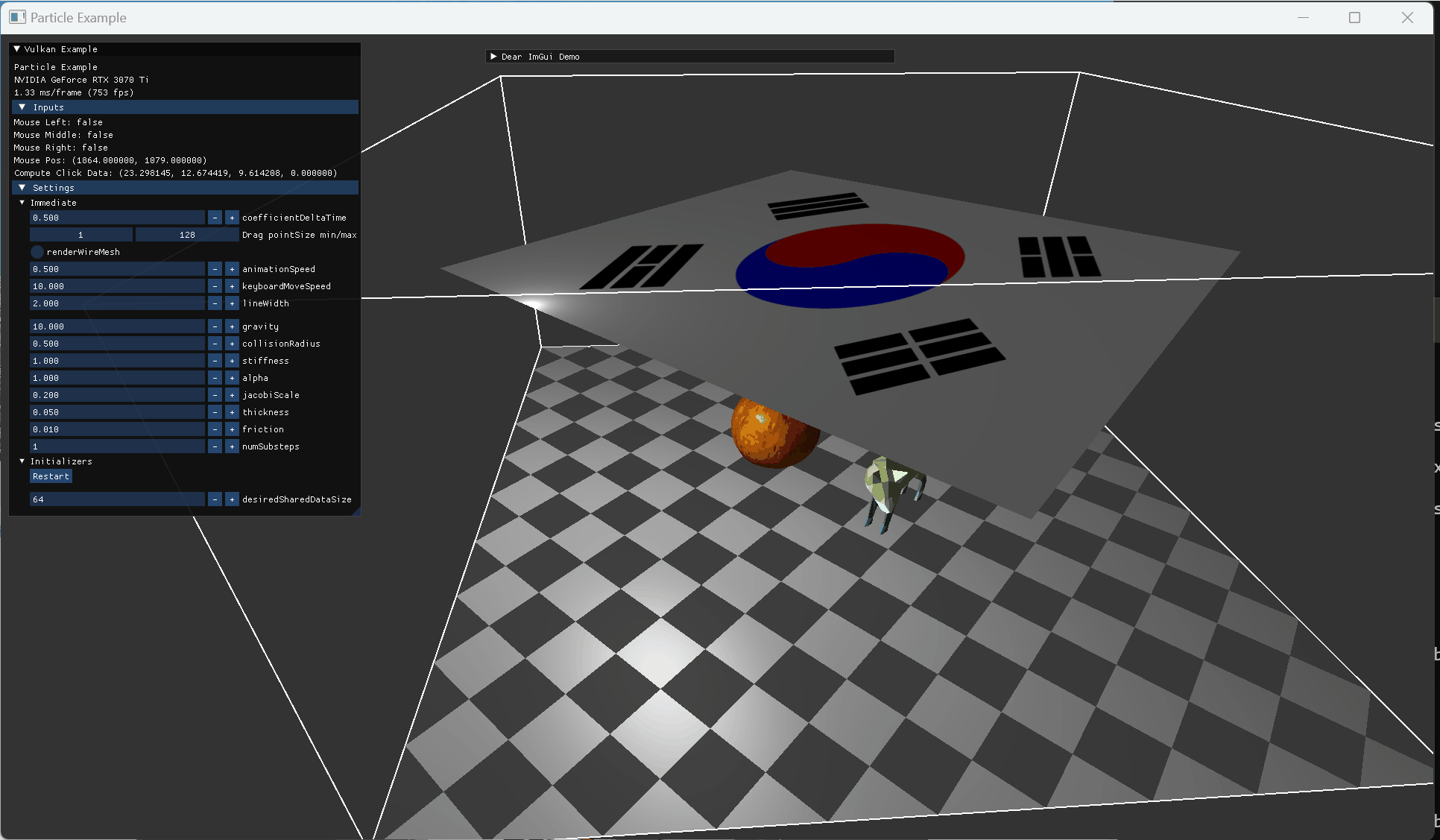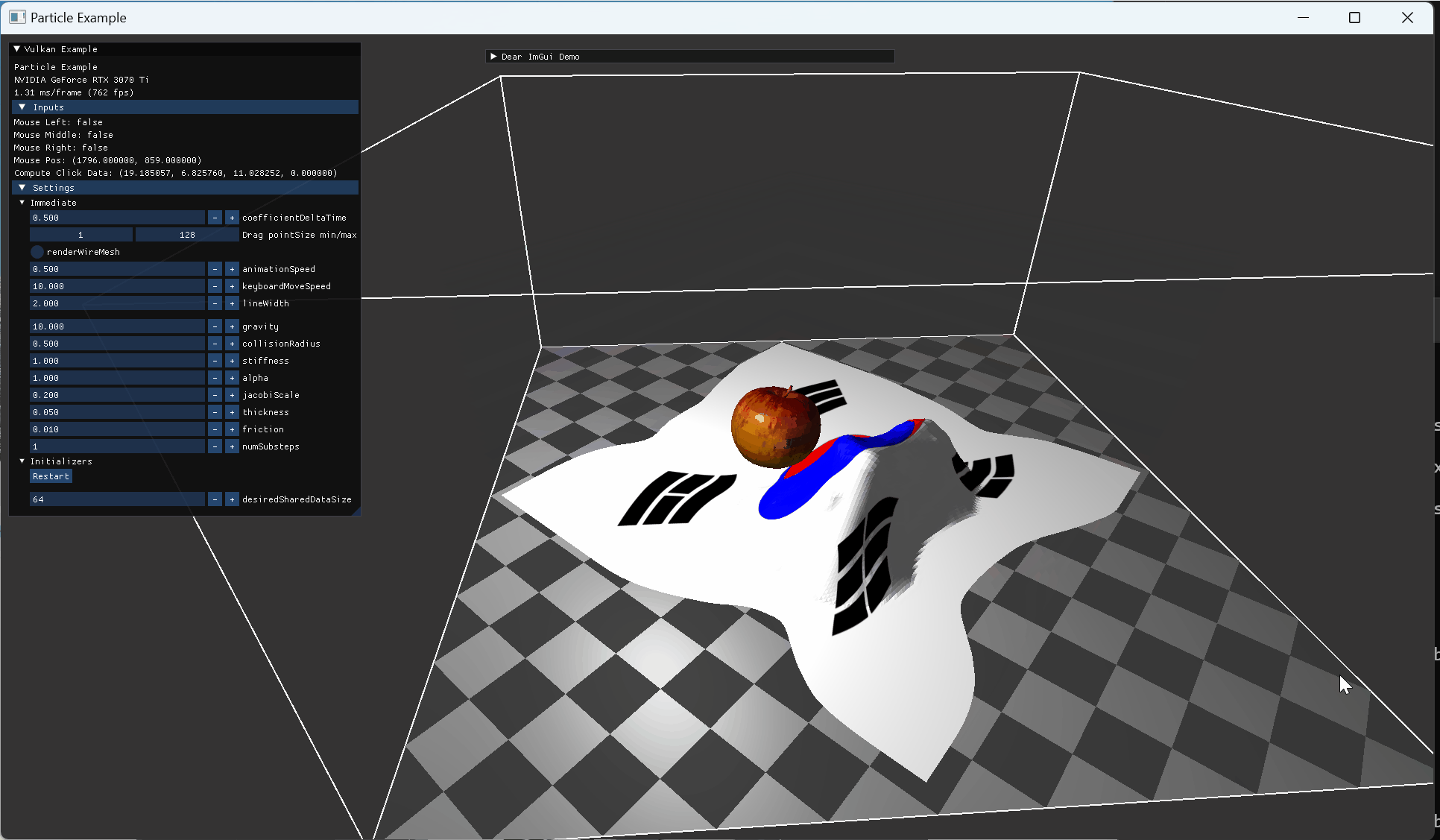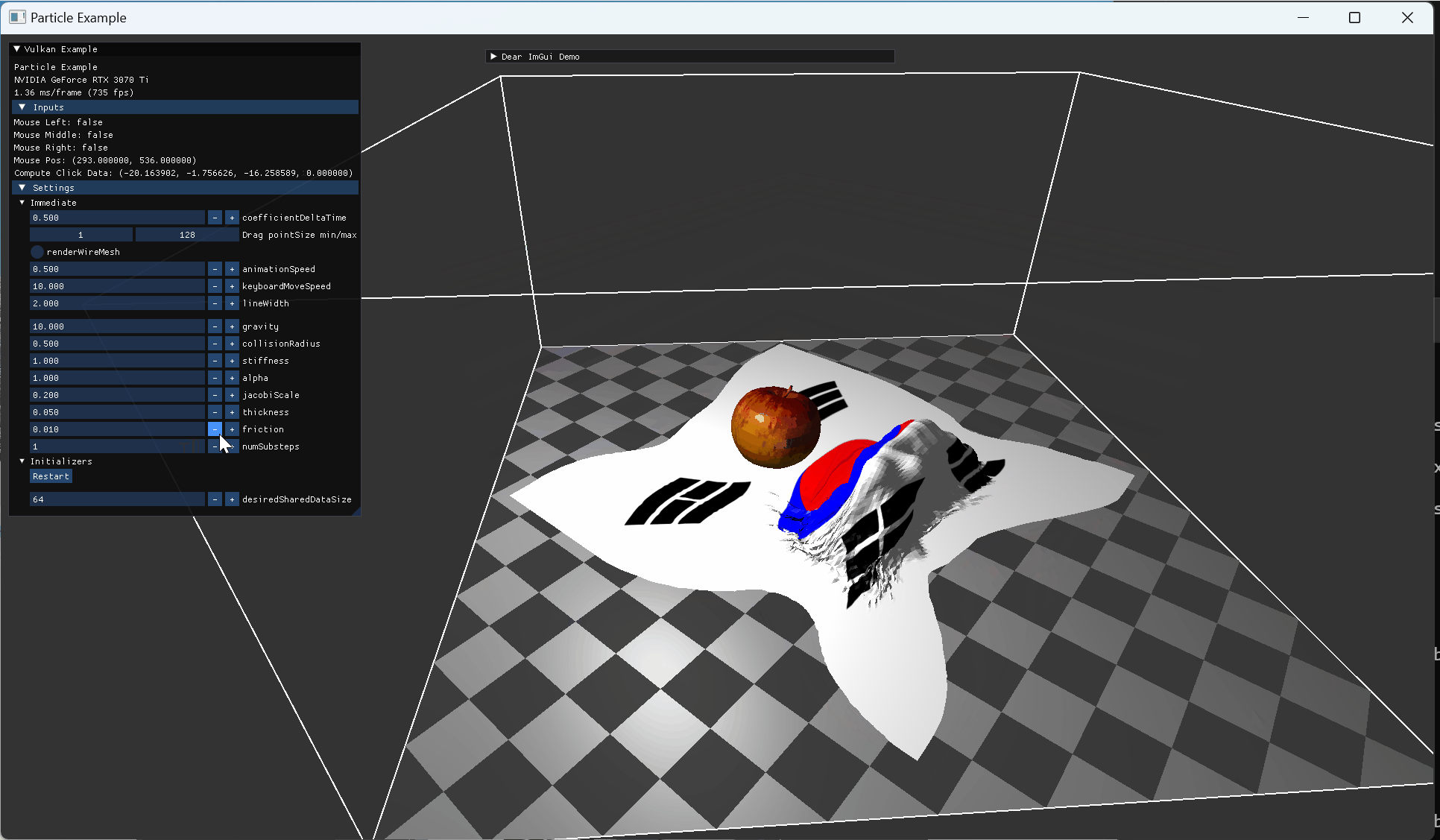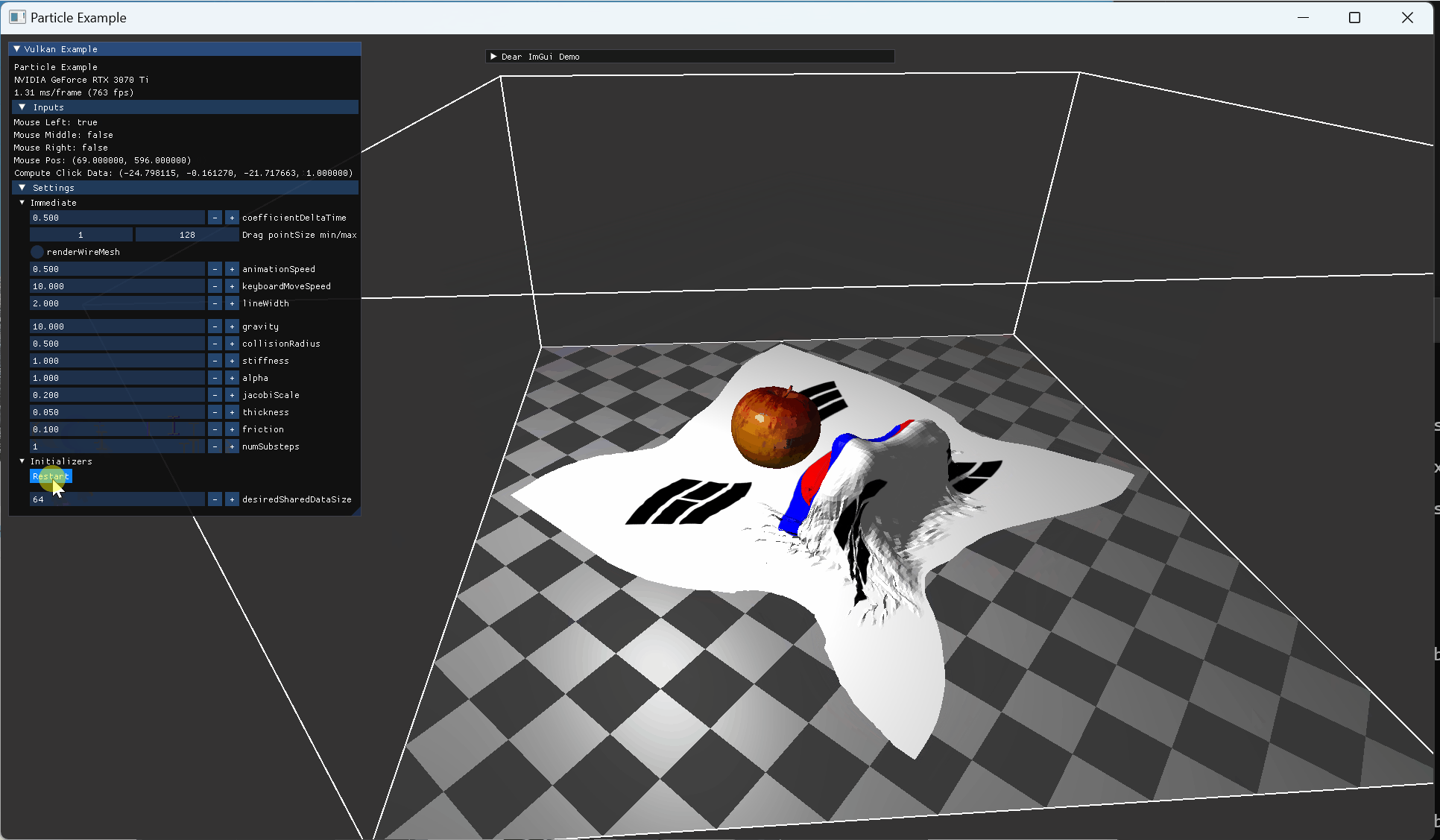
상단 두 점을 fix 해놓고 model과 collision한 모습 |
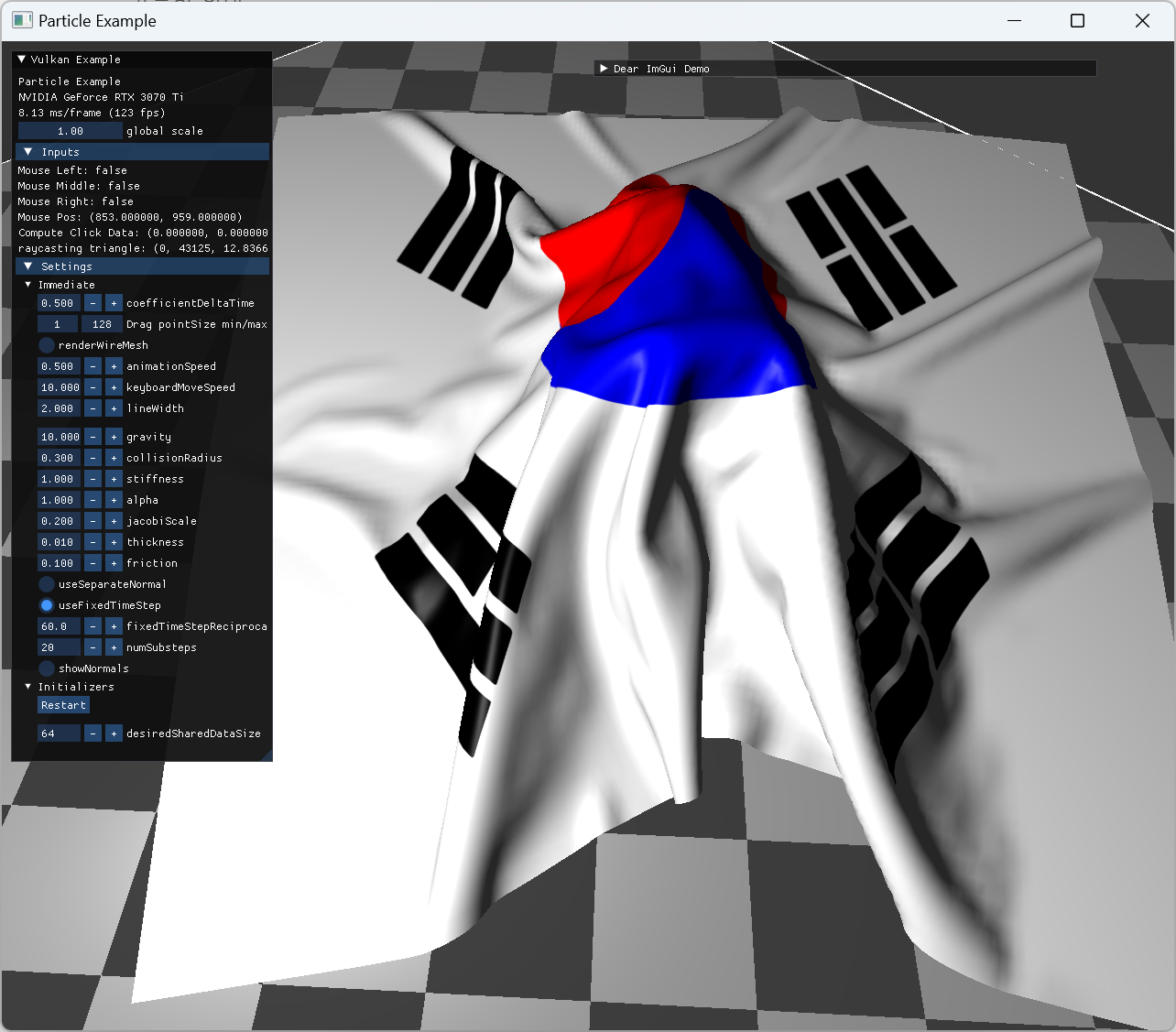 |
fox model animation 위로 떨어진 cloth 모습 |
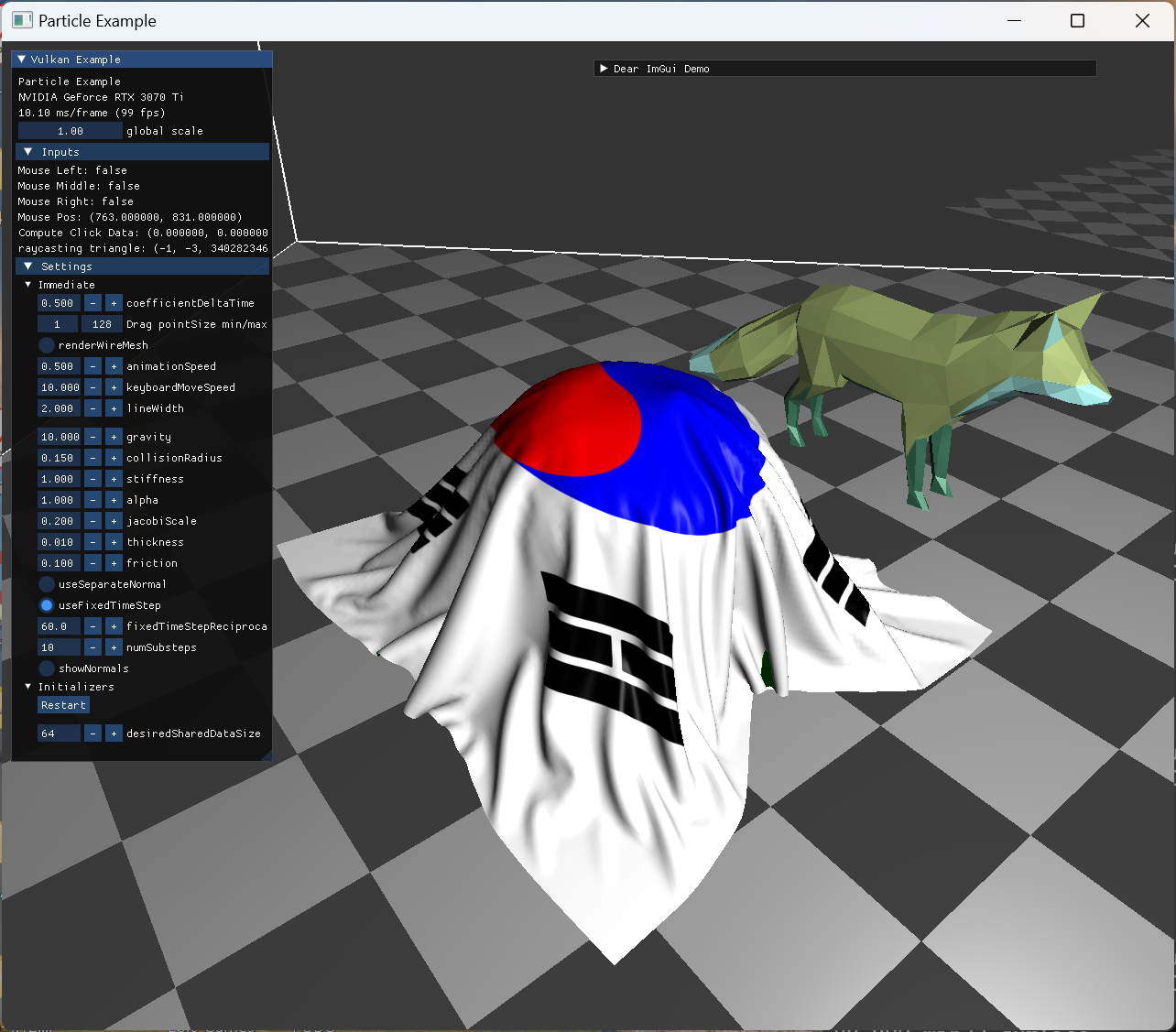 |
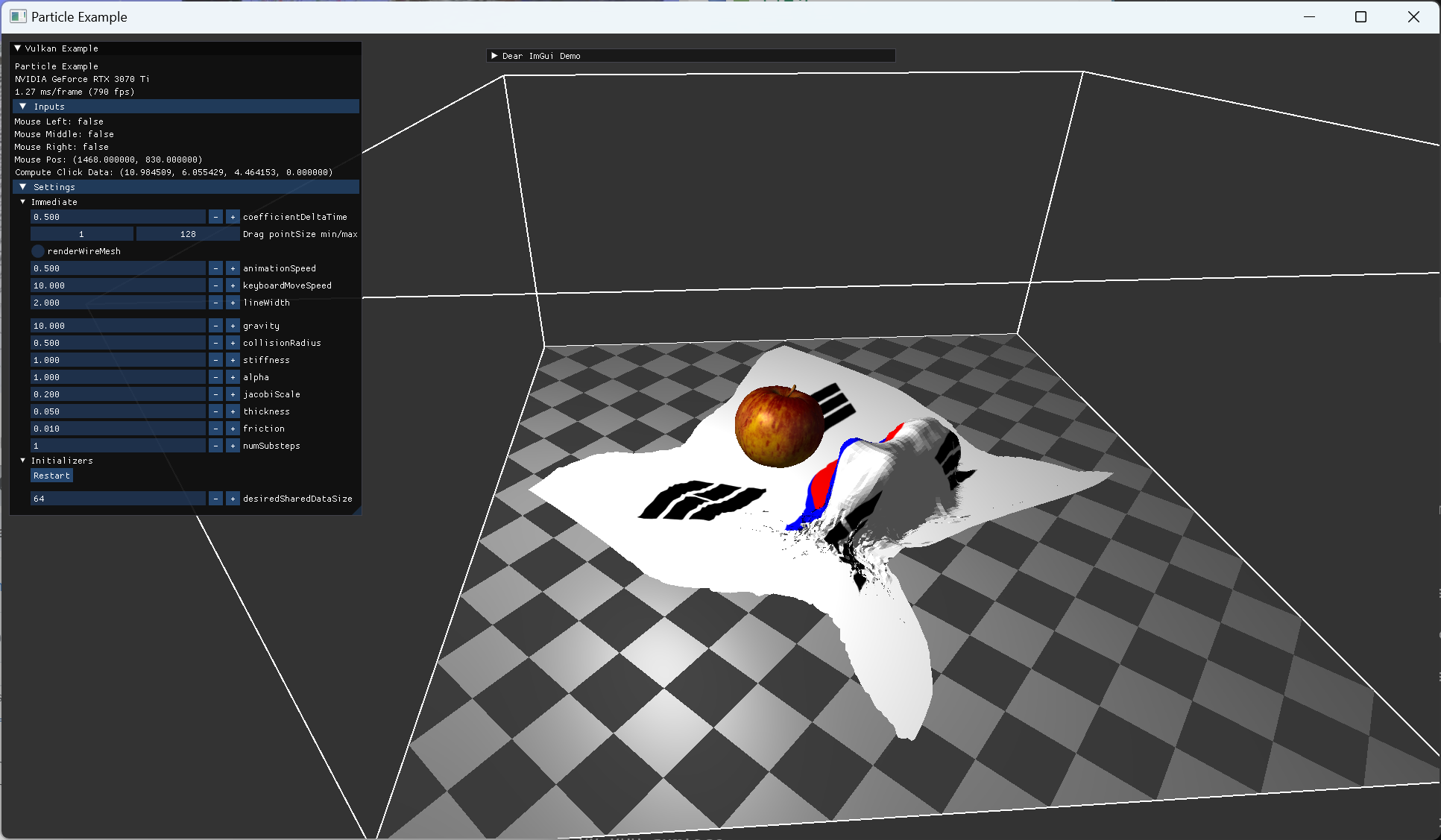
정지된 사과 모델 위로 떨어진 cloth 모습 |
Demo
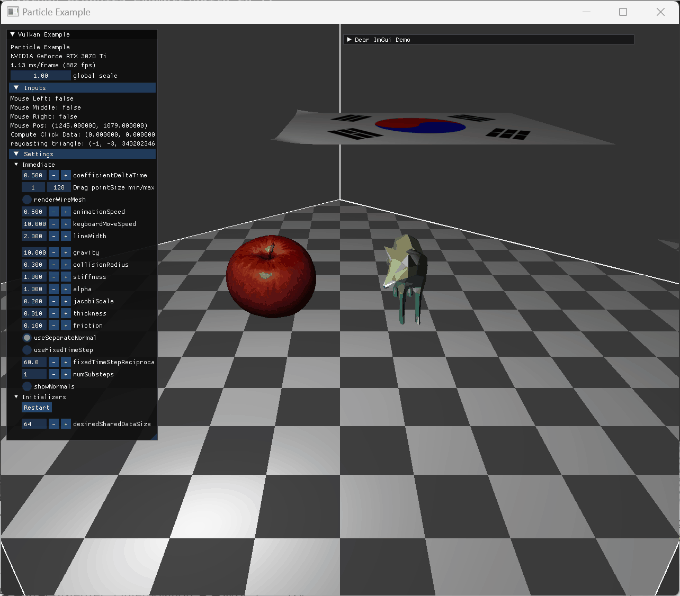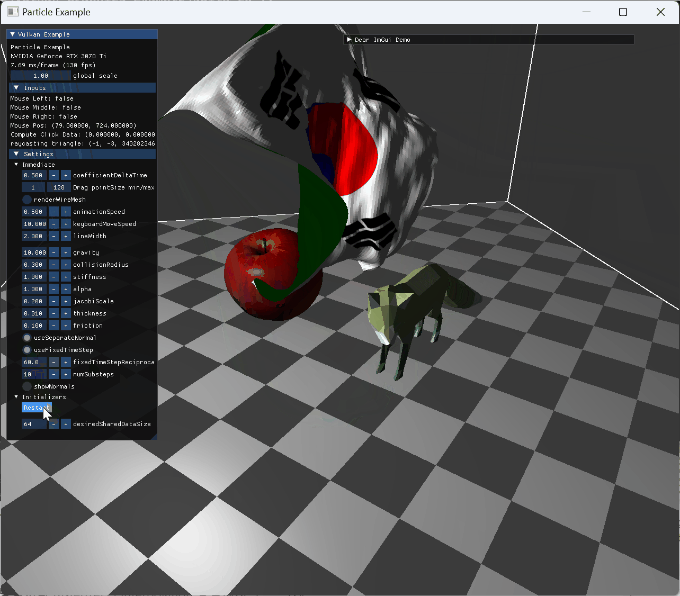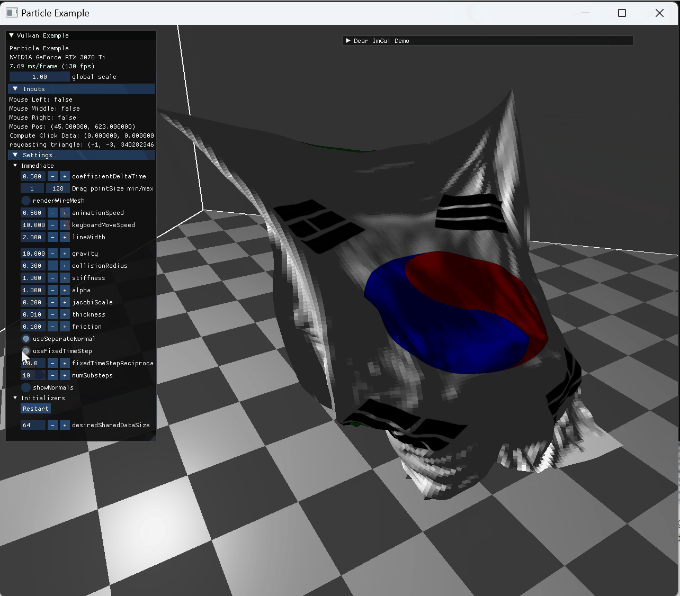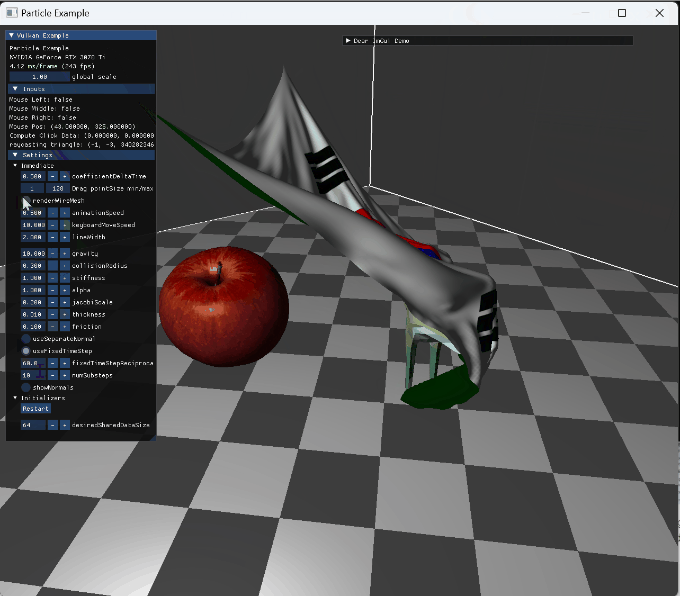 |
option들을 변경하는 장면 |
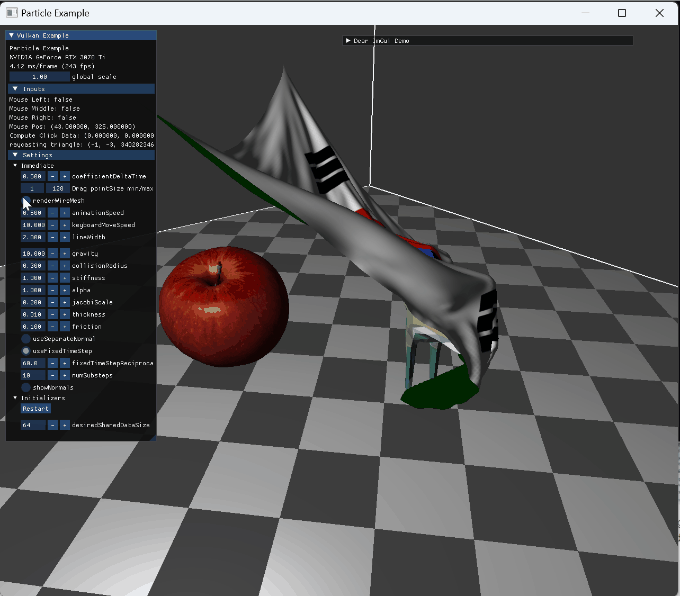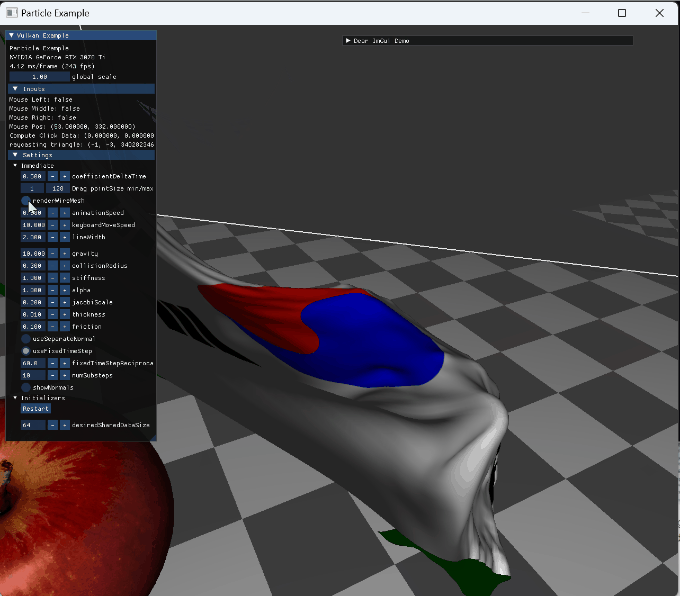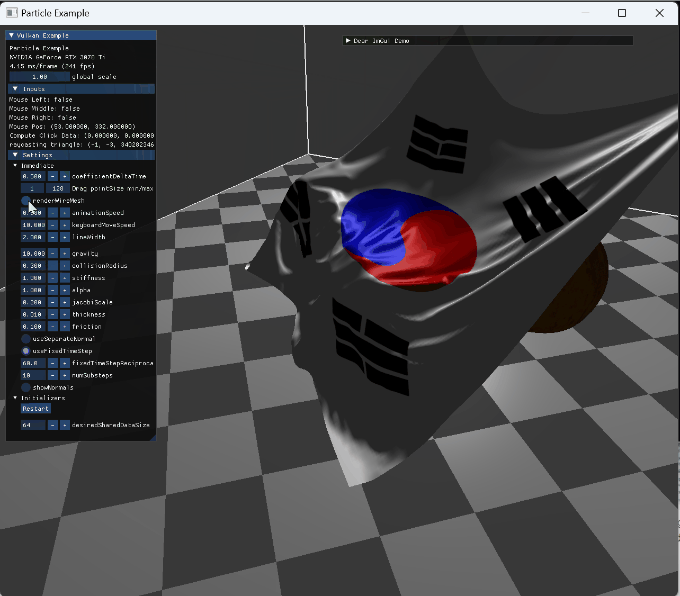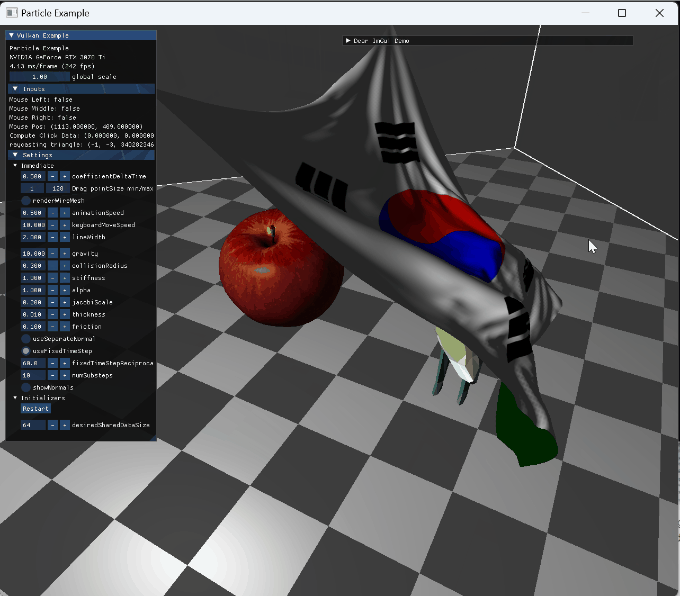 |
wireframe 전환과 backface |
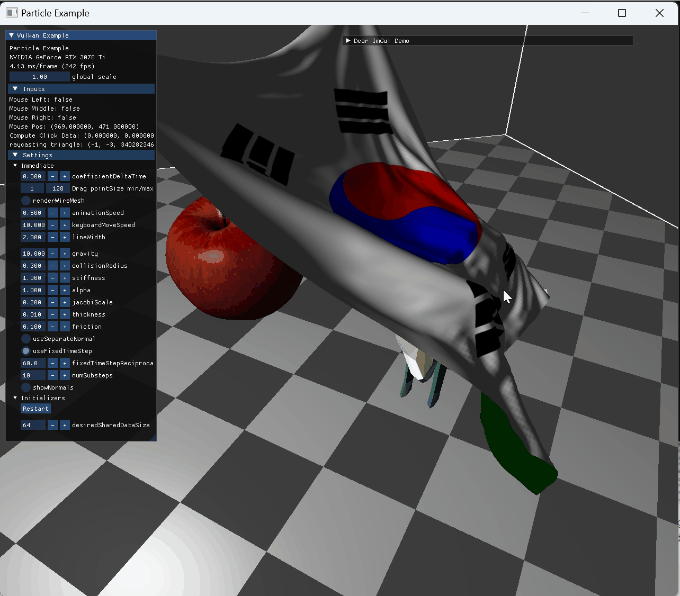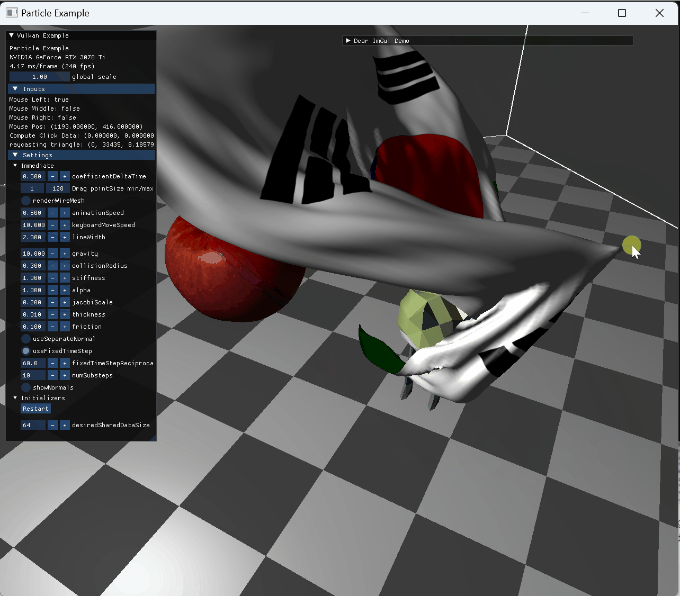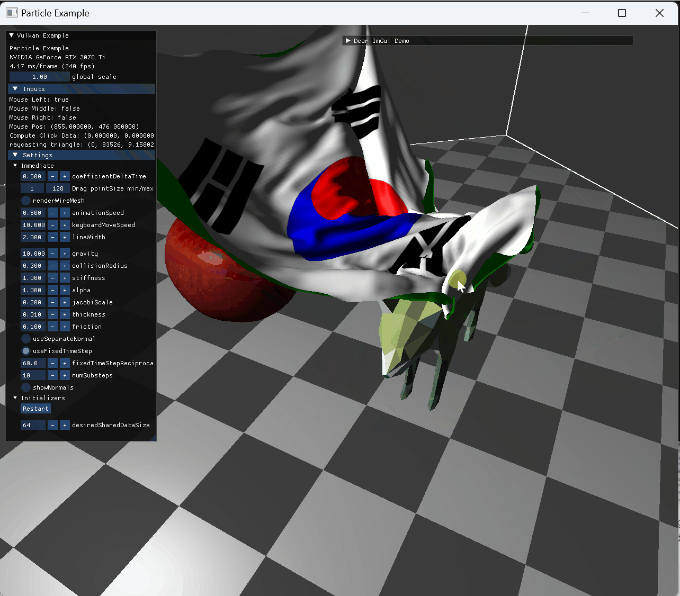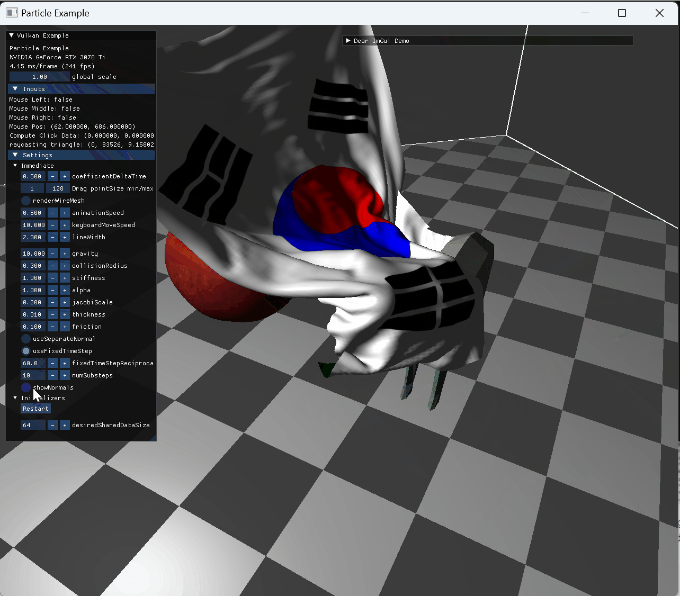 |
mouse drag interaction |
 |
geometry shader for normal debugging |
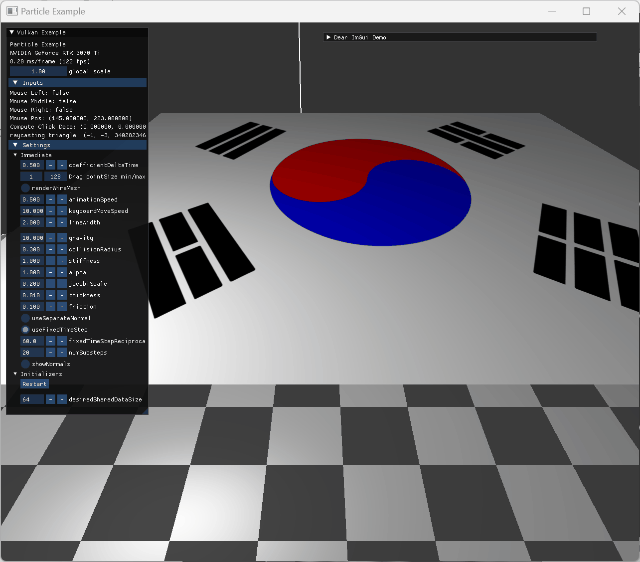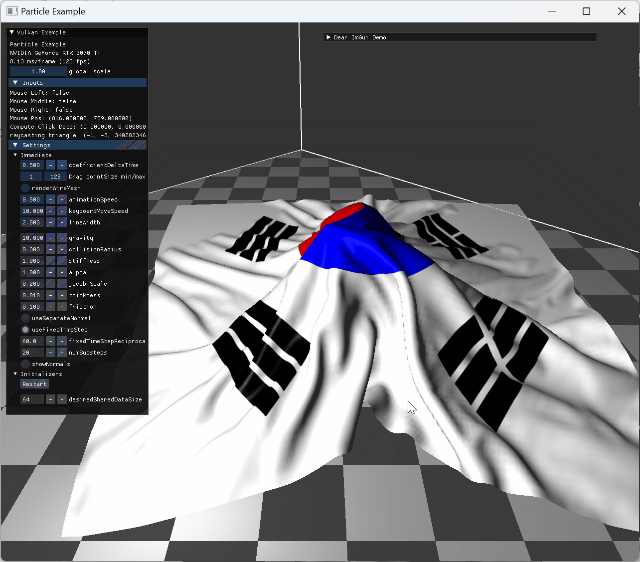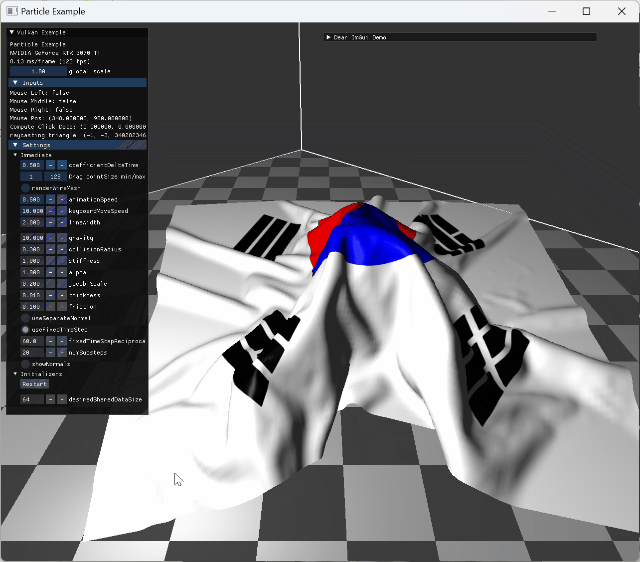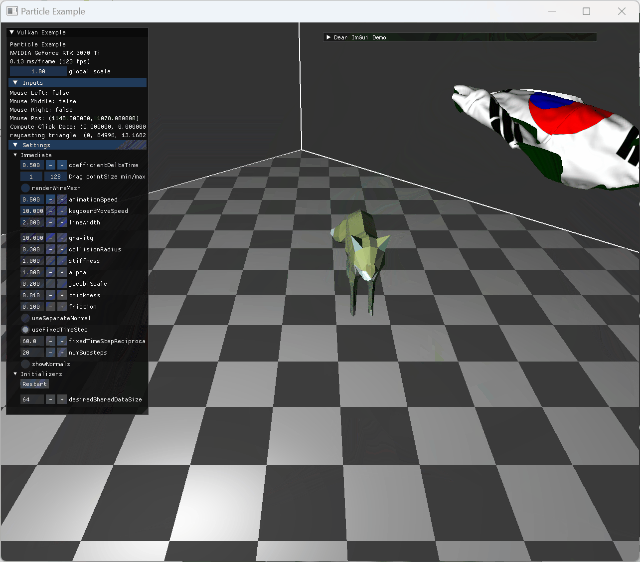 |
single animating model collision |
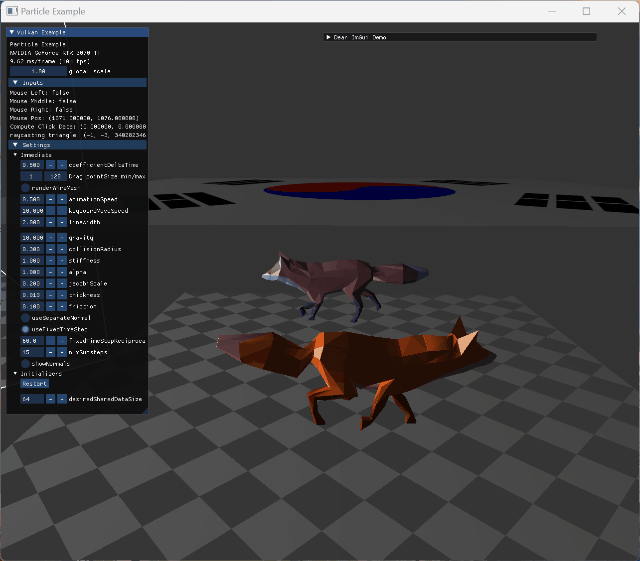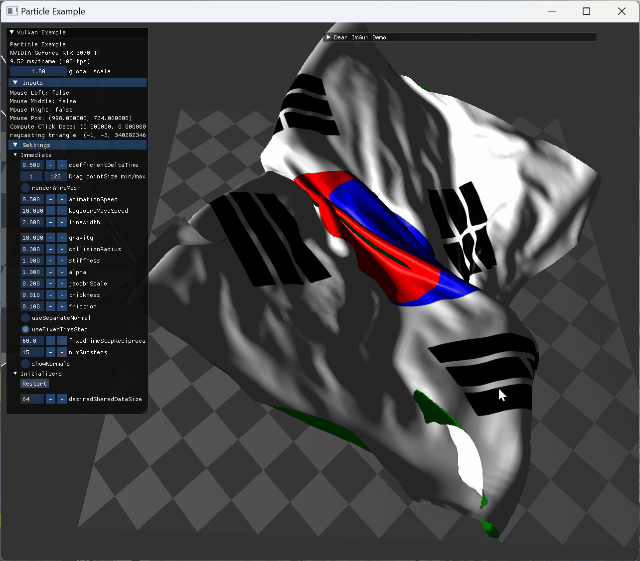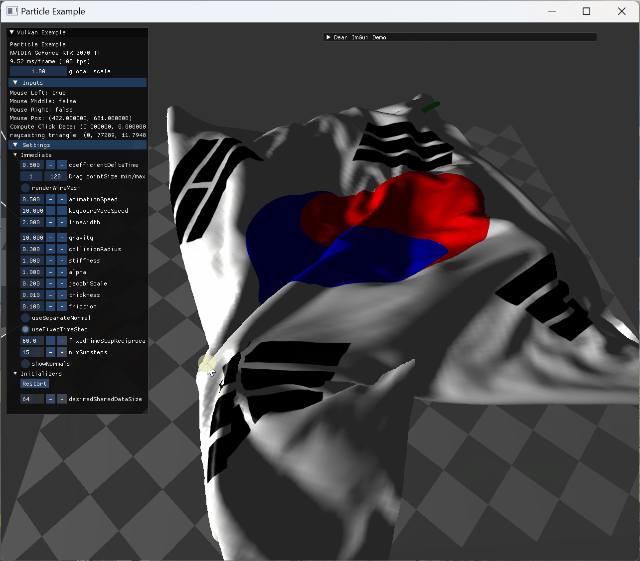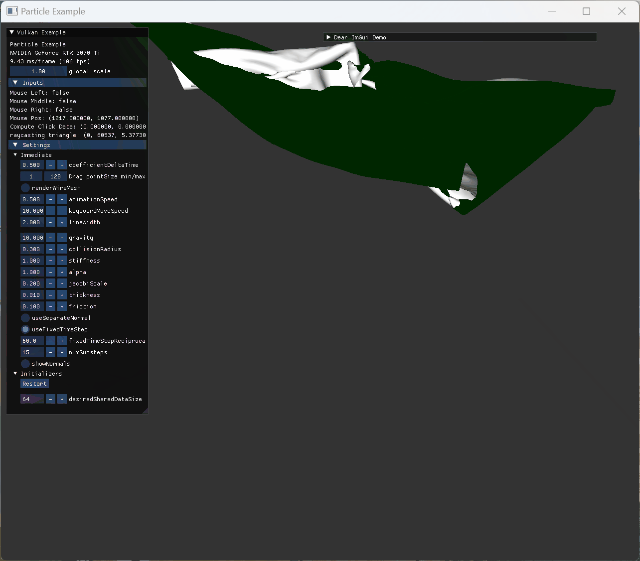 |
two animating model collision cloth의 self intersection이 구현되어 있지 않아 cloth가 꼬이도록 mouse interaction도 넣었다. |
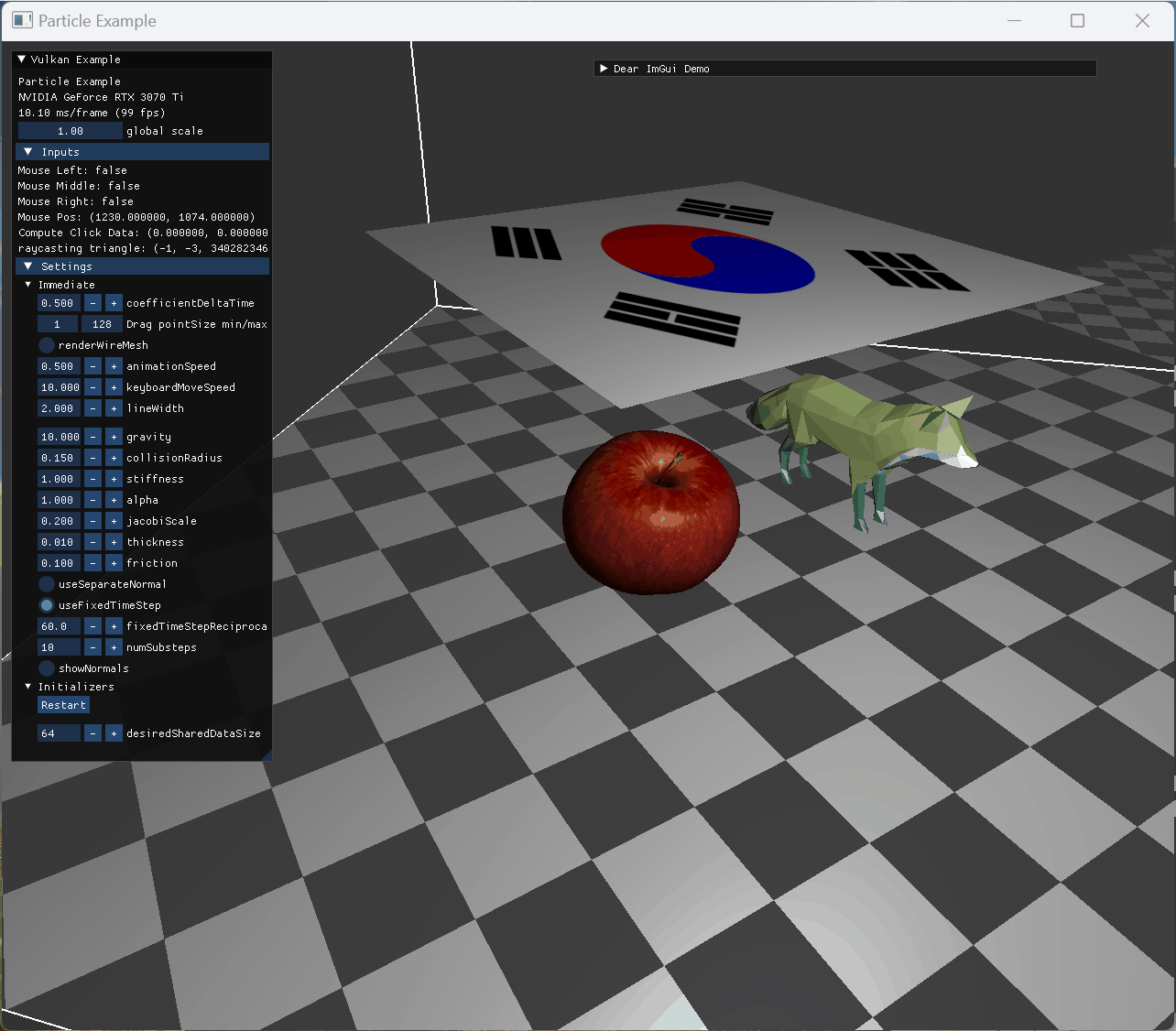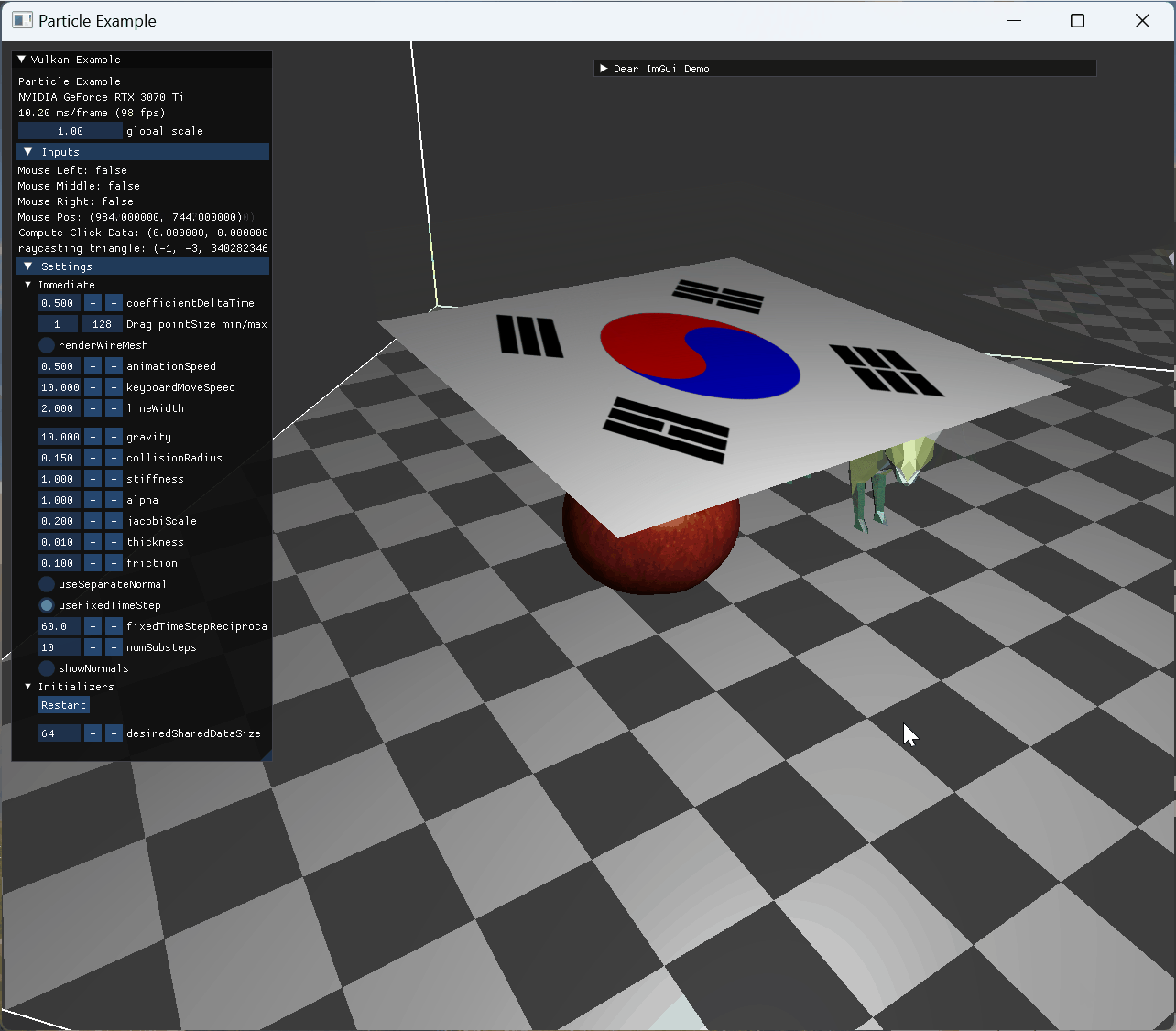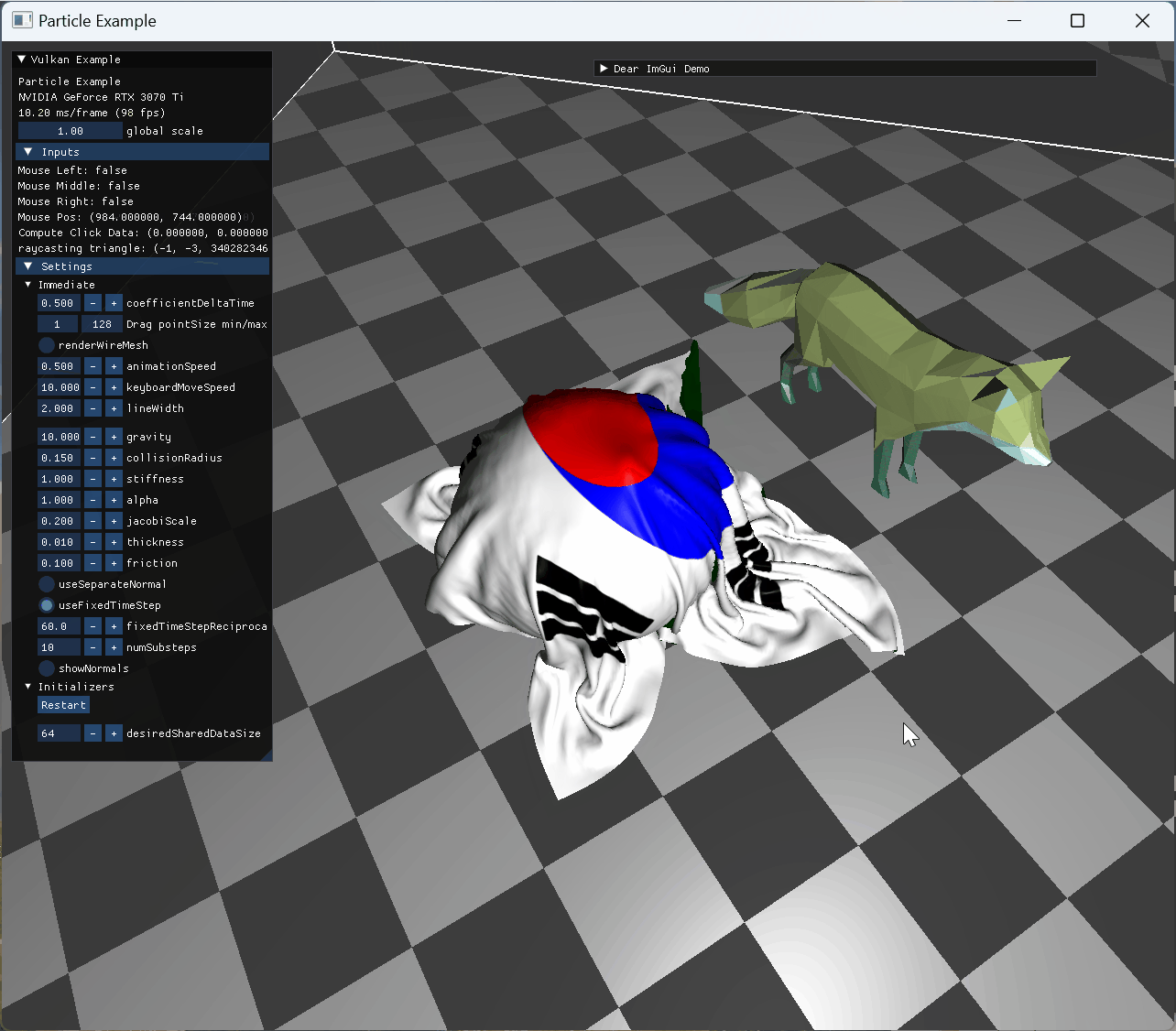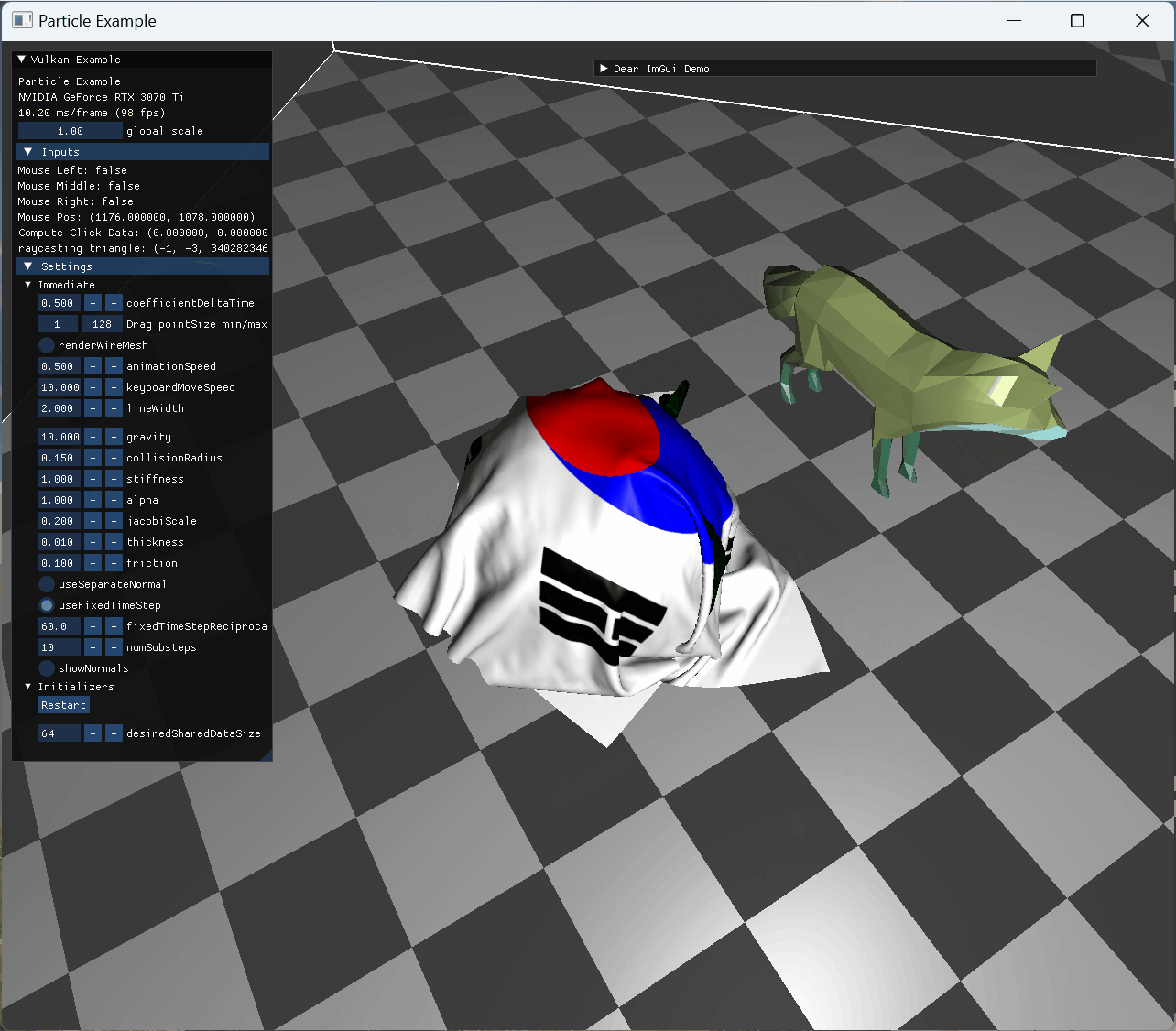 |
stationary model and animating model collision |
TODOs & Not TODOs
- self-collision
- 이건 좀 더 자연스러운 cloth simulation 결과를 위해서는 꼭 해보고 싶은 주제다.
- 기법에 대해 간단히 lec 15에서 봤을때는, 하나의 일관적인 method가 있다기 보다는 성능을 고려하면서 시각적으로 만족할 만한 결과를 얻기 위한 trick들을 쓰는 것으로 이해했기 때문에 좀 더 실질적인 필요가 있을 때 구현을 해볼 것 같다.
- optimize
- 간단한 cloth model인데도 성능이 잘 안나오게 구현한 부분이 많다. 특히 collision 관련한 부분은 너무 기초적이라 결과도 안좋고 성능도 안좋다.
- 바로 이 코드를 개선할 생각은 없고 이후에 새로운 내용들을 공부하고 얻은 지식을 활용해볼 수 있으면 적용할 것 같다.
- multiple cloth simulation
- 구조를 계획할 때 좀 더 다양한 경우를 계획해놨는데, 구현하다보니 여러 한계로 우선 미구현인채로 마치게됐다. 성능 optimize를 하게되면 그때 좀 더 다양한 interaction을 추가할 것 같다.
- cloth patch 간의 연결과 여러 animation model과의 interaction을 구현전에 구조상 계획을 해뒀기 때문에 코드 구조적인 변경이 크게 필요하지는 않을 것 같다.
- 좀 더 복잡한 cloth에 대한 simulation을 해볼 동기가 생기면 해볼 것 같다.
- improve model collision
- 이부분은 collision handle에 대한 내용을 먼저 별도의 주제로 익히고나면 추가하려 한다.
- 당장 cloth simulation에 포함시키기에는 주제가 너무 넓어진다고 생각한다.
초기에 구현하려 계획했던 부분들보다 상당히 축소된 기본 기능만 구현한 채로 마무리하게 되어서 TODO 보다 Not TODO가 더 많게 되어 찝찝한 느낌이 많이 남는다.
조급하게 당장 해봐야 할 것들로 생각하지 말고, 좀 더 주제를 세분화해서 다뤄야 이 TODO 목록들을 채워나갈 수 있을 것 같다.
마무리
이전에 vulkan api 관련 공부를 시작하면서 초기부터 compute shader나 이런 simulation 예제를 보고 나도 만들어보고 싶다고 생각했었다.
몇가지 예시를 구현해보니 확실히 재미도 있고, 눈에 보이는 것 외에 훨씬 많은 어려움이 뒤에 숨어 있다고 느꼈다.
원래는 이직 준비를 하는 겸, 관심있던 computer graphics 의 기본적인 개념을 학습하고자했던 의도로 생각하면 이런 예제들을 다듬게 되면서 소요되는 시간이 예상보다 더 오래 걸려서 학습해야할 주제들을 많이 커버하지 못한다고 느꼈다. 정작 관심있던 채용 포지션 중에 지원하지 못했던 것 들도 이나 하지 않았던 것들도 있고, 면접 과정에서 생각보다 내가 공부하고 있는 속도나 커버리지가 graphics engineer가 요구하는 커버리지에 부족한 점들도 있는 것 같았다. (물론 몇몇 포지션과는 준비한 방향성에서 차이가 있음을 느끼기도 했다.)
면접 준비와 면접 과정에서 몇가지 주제는 좀 우선적으로 다뤄봐야겠다고 느낀 것이 있는데, 다음 항목들이고 앞으로 우선적으로 다뤄보려고 한다.
- deferred rendering
- depth-stencil
- multi-thread command buffer
근황
최근 이직을 하고나서 원래 진행하던 이 cloth simulation 주제를 끝마치고 블로그에 올리기 위한 자료나 글 정리만을 하고 있었는데, 이것만으로도 몇주가 지나간 것 같다. 이렇게 주말 등의 시간을 쪼개서 조금씩 글을 추가하고 있었는데, 오늘이 돼서야 어느정도 초안을 마무리하고 올리게 돼서 다행이라고 생각한다. 그리고 혼자만 보는 블로그더라도, 글로 과정을 기록하고 생각했던 것들을 정리해두는 것은 확실히 업무에서도 도움이 되고 있다. 소통이나 진행상황 공유를 말로 하는 것보다 문서화해서 진행하는 것은 이전 직장에서도 강조되었던 내용들인데, 그나마 쉬는 기간에도 어느정도 기록하는 습관들 둬서 그런지 그런 부분에서는 수월하게 적응했다.
요즘 하는 일은 3D mesh를 생성하는 일을 하고 있는데, 요구 조건에 맞게 생성하고 잘 배치하는 작업들을 효율적으로 할 수 있게 자동화 하는 작업들을 하고 있고 3D 아티스트 분들과도 소통하며 협업하고 있다. 지금 하는일은 computer graphics 분야로 보면 geometry나 modeling에 가까운 부분이라고 생각이된다. 입사과정에서도 graphics engineer 포지션으로 지원하면서 내가 rendering이나 animation(simulation)쪽에 관심이 있음을 밝히기도 했고 맡게될 업무는 geometry나 정적인 model을 다루는 쪽일 수 있다고 상호 인지했던터라 불만이 있다거나 그런 상태는 아니다. 사실 나도 graphics engineer로의 커리어를 희망하면서도 막상은 graphics engineer라면 정확히 뭘 해야한다 거나 보통 어떤 업무를 맡는다는 등의 경험이나 판단 기준이 있지는 않으니, 일단은 이전보다 한단계 더 관심분야에 가까워진다는 측면에서는 이점이 있다고 판단하고 최종 결정을 한 것이기도 하다. 한가지 희망했던 건 graphics engineer의 senior 개발자가 있기를 희망했는데, 그 부분에서는 기대와 맞지 않는 부분도 있는 것 같다. 팀 domain에 해당하는 senior 분들이 팀에 계시고, 옆 팀이나 주변 팀에 graphics engineer분들이 계시는 걸로 파악하고 있어서 보고 배우자 한다면, 나 스스로 하기 나름일 것 같기도 하다.
업무 방식 측면에서는, 다른 팀이나 다른 분야의 전문가와 협업하는 과정에서 가장 중요하다고 느낀 것은 역시 요구사항을, (specification을) 사전에 명확히 하는 것이다. 어떤 결과를 원하는지, 그 결과에 어떤 특성들이 있을 수록 좋은지, 그 특성을 정량화할 수 있는지, 그렇다면 어느 정도 수치를 만족해야하는지, 더 나아가서는 왜 그런 특성들이 필요하고 그 결과가 어디에 쓰이는지에 대한 context 파악까지 할수 있어야 서로 만족할만한 결과물을 얻는다는 점을 느끼고 있다. 지금까지는 업무를 시작할때 이런 specification을 가지지 못한 채로 시작하고 있어서 작업을 진행하면서 중간결과를 전달하고 오는 피드백을 통해서 정리중이다. 이후에는 내가 아니더라도 이런 업무를 맡는 다음 사람을 생각하며 초기 계획을 위해서는 이런 specification을 잘 남기고 서로 잘 소통할 수 있도록 염두해두고 일하고 있다. 분야 특성상 눈으로 결과를 봐야한다거나, QA가 필요하다거나 하는 특성이 있을 수 있는데, 적어도 내가 작업하기 편한 언어에서는 최대한 많은 특성들이 정량화되고 그 수치를 달성하는 것을 목적으로 작업하는게 편하다. 아마 대부분의 개발자는 그렇지 않을까.
세부적인 개발 측면에서 아직은 주로 python 코드를 쓰고 있는데, 다른 python의 open source 기반 패키지들은 대부분 openGL renderer에 기반을 두고 있는게 상당히 많다고 느꼈다. 그리고 대부분 C++로 개발된 라이브러리를 python으로 포팅된 바인딩들을 쓰는 경우가 많은데 그럴때 C++ 측에서 integration 작업이나 자료가 많아서 참고용으로 보고 있는 정도다. 이후에 C++ 이나 다른 언어를 사용할때에는 상용 게임엔진을 다루거나 할 때 정도로 예상중이다.
아직 몇달이 채 되지 않아서 이런 작업을 계속하게 될지 혹은 다른 업무를 맡을지는 모르겠는데, 지금까지 일의 형태는 이전 직장에서 하던 양상과 크게 다르지 않아 큰 어려움은 없다고 생각하고 있다.(타 도메인 전문가와 소통하며 어떤 결과물을 만들어내거나 요구사항에 맞춰서 어떤 프로세스를 자동화 한다거나 하는 큰 개념에서 유사하다.) 조금 다른점은 이전 직장에서는 하나의 프로젝트를 여러명에서 contributor로 같이 진행하면서 review하고 배포하는 느낌이었다면, 현 직장에서는 우리팀 모두가 각자 다른 일을 하고 있고 그래서인지 code를 서로 review하는 문화가 활발한 건 아닌 것 같다. (팀마다 확실히 분위기는 다르긴 한 것 같다). 물론 내가 아직 혼자서 이것저것 해볼 기회가 주어져서 reviewer나 reviewee로 할당될 일이 거의 없어서 그런 점도 있다.
이전 직장에서는 2d 위주의 기하 데이터를 중점으로 다뤘다면 요즘엔 2.5D 정도의 데이터를 다루고 있는 것 같다. 완전히 3D 라고 보기 어려운 부분은 다루는 데이터 도메인에 기반한 것도 있고, 내가 프로토타이핑 식으로 요즘 작업하면서 시도해보고 있는 방향에서 오는 것도 있다. 확실히 익숙한 기술이나 접근 방식이 구현비용이 적게 든다고 생각하게 돼서 인지, 먼저 떠올리고 테스트해보게 되는데, 이런 측면에서 익숙한 툴을 늘리는 것의 중요성도 느끼고 있다. graphics에서 rendering과 관련된 부분은 아직 거의 다루고 있지 않기도 한데, 뭔가 건드려볼 대상들은 확실히 많아 보이지만 내가 적은 비용으로 쉽게 접근해볼만한 익숙함이 부족해서 선뜻 파보지 않아서 그렇기도 하다고 생각한다. (예를 들자면 texture opmization 등의 주제). 관심만 있고 경험은 없는 채로 남기 싫다면 업무에서 시작을 하든, 퇴근 후 공부를 하든 뭐라도 계획을 세울 시점이다. 어느정도 기반 지식이 있어서 관련 업무를 맡는다면 일하면서 더 효율적으로 체득할 수 있을 거라 기대하고 있다.
그리고 상용 게임엔진 관련 사용도 어느정도 익혀두면 확실히 도움이 될것이라고 예전보다 더 강하게 느끼고 있는데, 아직 계획적인 학습 방향을 설정하지는 않고 가끔씩 궁금한 내용 한두개씩 찾아보는 정도이다. (어떤 작업을 시작하고 싶다거나, 내가 작업 의사를 표출하려면 할 줄 아는 것만 깊게 파는 것 보다는 여러가지를 건드려보는게 기회가 많이 생길 것 같다.) 관련해서 스타트업 개발자로서 더 강력하게 느끼는 점은, 내가 하고싶다거나 필요하다고 제시하는 업무를 직접 계획해서 시작해볼 수 있는 자율성과 기회가 주어진다는 점이다. top-down으로 정해진 업무나 필요한 기능을 만드는 건 당연히 해야하는 거고, 더 능동적으로 내가 제안하고 필요성을 제기해야한다고 생각하고 있다. (이전 직장에서 내가 부족했다고 생각하는 부분이기도 하다.) 그게 현재 일하는 직장에서의 장점이라고 생각하고, 어떻게 보면 이런 기회를 잘 스스로 챙기지 못하고 수동적인 태도로 일을하게 되면 큰 단점이 될 것으로 보고 있다.