이전 예제에서 glTF모델 load와 관련 구조를 작성할 때, animation과 skinning관련된 부분들은 아직 쓰이지 않아 제외하고 구현했다.
이번 예제를 통해 해당 빈 부분들의 기능을 추가했다.
https://github.com/keechang-choi/Vulkan-Graphics-Example/pull/3
개념
기본적인 개념은 이전과 같은 자료를 참고했다.
skin
mesh에 있는 여러 vertices들이 skeleton의 각 bone 위치에 영향을 받도록 해주는 기법이다.
- node는 mesh를 참조할 수 있다. (mesh가 없는 node도 있다.)
- node는 skin도 참조할 수 있다.
- skin은 joint들로 이뤄져 있다.
- 그리고 각 joint에 해당하는 inverse bind matrix 정보도 가지고 있는데, 이는 아래에서 설명하겠다.
- joint는 node의 일종이다.
- 따라서 node의 hierarchy 구조를 활용할 수 있다.
- skeleton은 따로 명시적인 구조로 저장되지 않고, joint들의 계층구조가 이를 표현한다.
- skinned mesh는 그 primitives를 통해, joint와 weight attribute를 가진다.
- joint는 그 vertex에 영향을 줄 joint의 index다. 보통 4개로, vec4타입을 사용한다.
- weight는 각 joint가 그 vertex에 얼마나 영향을 줄지를 나타낸다.
skinning matrix
skeleton의 자세에 따라서 (joint들의 변환으로 결정됨) mesh의 vertices들이 어떻게 변환될지 계산한 결과이다. 이 계산에 joint matrices와 weight들이 쓰인다.
이 skin matrix를 반영한 최종 위치는 결국 shader에서 계산되는데,
다음과 같은 예시를 들 수 있다.
gl_Position = P * V * M * (nodeMat) * skinMat * inPos;
각자의 변환을 뜯어보면,
- M: model space -> world space
- load된 모델자체를 이동/회전/스케일링 하는 역할로 쓰인다.
- nodeMat: node(mesh) local space -> model space
- 모델 내부의 scene graph 계층 구조를 표현하므로 별도로 필요하다.
- 이 nodeMat이 사용되려면, mesh가 있는 node의 matrix가 있어야 하는데, 이런 자료를 많이 보진 못했다. 3D 모델링 과정 상, mesh의 좌표계를 model의 좌표계와 동일하게 보는 경우가 많은 것 같은데, glTF-Sample-Models repo를 보면, 일부 CAD 변환 데이터들에만 해당된다.
- skinMat: mesh space -> mesh space
- \[\sum_{i=1}^{4}{v.weight[i] * jointMatrice[v.joint[i]]}\]
- 한 mesh(혹은 skin)에서 사용하는 joint들의 최대 수는 64개로 정했다. (따로 제한이 있는 것 같진 않고, buffer 크기를 고려해서 정했다.)
- jointMat은 inverse global transform * global joint transform * inverse bind mat 으로 계산된다.
- invese global transform: model space -> mesh space
- 이 global transform은 skin을 가지고 있는 node의 matrix다.
- 이 node를
drawNode()할 때 mesh가 실제로 그려지는데, mesh의 primitives의 joint가 계산에 사용된다. 그리고 이 node의 하위에 skin이 있는게 아니라, 별도의 skin을 참조하는 것이기에 이 global transform은 shader에서 node mat을 곱하는 것을 상쇄시키도록 작용한다. 따라서 shader 구현에 따라 어떻게 계산할지가 결정된다. - 지금은 이게 왜 필요한지 명확히 설명되지 않았을 수 있는데, 아래에서 inverse bind matrix를 다르면서 더 자세히 설명하겠다.
- global joint transform: joint local space -> model space
- 자세에 따라 바뀌는 부분의 실질적 내용이다.
- animation을 구성할때도 시간에따라 이 부분이 변경된다.
- 이름에 global이 있듯이, 모든 hierarchy의 계산이 포함된 결과가 들어간다.
- inverse bind matrix: mesh space -> joint local space
- 기본 바인드 자세에서, 각 joint의 위치가 mesh 기준 어디인지 나타내는 것이 bind matrix이다. 이 matrix의 inverse를 처음에 곱해줌으로써, mesh를 joint의 local space로 보낸다.
- invese global transform: model space -> mesh space
inverse bind matrix
guide의 설명으로는 inverse bind matrix관련 이해가 충분하지 않아 다음 자료들을 추가로 참고했다.
이 tutorial 자료에서, guide의 예시와 같은 자료가 쓰여서 이해에 도움이 된다.
https://lisyarus.github.io/blog/graphics/2023/07/03/gltf-animation.html
더 일반적인 animation에 관련된 설명을 하는데, 가장 이해에 도움이 많이된 자료다.
- skeleton based vs. morph-target
- 장점
- 저장공간이 덜 든다.
- frame마다 필요한 data straming이 적다.
- mesh가 아니라, bone 정보만 전달하면 되니까. *(GPU 쪽에 animation 관련 데이터 전체를 저장해놓는 방법도 있긴 함)
- artist 친화적
- animation과 model을 분리
- procedural animation으로 통합하기 쉽다.
- pre-defined가 아닌 다양한 상황에서의 animation
- 발이 땅을 통과하지 않는 것 등의 제한사항 구현
- pre-defined가 아닌 다양한 상황에서의 animation
- 단점
- 정해진 format을 적절하게 parse, decode 해야함
- 각 animated model의 bone의 변환을 계산해야함. (계산비용 및 구현 복잡도 -> compute shader 사용 가능)
- bone data를 어떻게든 GPU로 보내야함
- per vertex 정보가 아니고, uniform에 맞지 않을 수 있음.
- bone transform을 vertex shader에서 적용해야해서 대략 4배 느려짐 (mat mul을 4번 더하니까, 그래도 fragment shader가 보통 더 느림)
- 이 계산을 compute shader에서 할 수도 있음. 실제로 다음 예제에서 그렇게 할 예정.
- 성능상 차이가 있을지는 모르겠음. 확인 필요.
- 장점
- bone transform(joint global transform)
- 기본적으로 joint node에 저장된 matrix를 적용하고 나서, parent의것을 적용하는 순서이다.
- joint local transform 이 필요한 이유는 상식적으로, 팔을 돌리는 동작을 표현할때, origin이 어깨에 있는 것이 편한 것과 같은 이유.
- 그래서 각 bone의 local transfrom 기준은 local coorinates다. 근데 적용할 대상인 vertices들은 model(혹은 mesh)의 좌표계에 있다. (여기서 설명은 모든 mesh coordinate과 model coordinate을 동일하게 보는 것 같다.)
- 이 차이를 없애는 map: model space -> bone local space 변환이 inverse bind matrix이다.
- bone local을 옮기는 것이 다일까? 아니다. parent bone도 고려해야한다.
- bone local transform을 적용 후, bind pose mat을 곱해서 local animation이 적용된 vertices들을 다시 모델의 기존 위치쪽으로 옮긴다.
- 그 후 parent의 inv bind mat을 곱해서 parent bone의 local로 가져오는 방식을 반복한다.
- 이 연속된 두 변환을 하나로 곱해서 다음처럼 표기하자.
\[\displaylines{converToParentCS(node) = \\ invBindMat(parent) * BindMat(node)}\]
- 사실 glTF에서는 이 변환을 명시적으로 가지고 있지 않다.
- artist들이나 3d model software에서 어떨때는 vertices들이 모델의 기본 state가 아니라, bind pose라고 하는 변환된 state의 bone에 붙어있게 하는것이 편할때가 있다. 그래서 vertices들을 각 bone이 bind pose에서 expects하는 좌표계로 옮기는 또다른 변환이 필요할지도 모르는데, 사실 필요없다고 한다.
- blender에서는 world-space vertex positions가 bind pose 그 자체다. 그래서 blender에서 exported 된 animated model은 animation 없이 사용하기는 불가능하지만 효율적으로 rendering 가능한다.
- 이 말이 잘 이해가 안가긴하는데, bind pose라는 별도의 개념없이 rest pose가 그대로 사용된다는 말 같다. (bind pose와 rest pose가 다른 sw에서는 구분되는 개념인지도 잘 모르겠지만) 캐릭터 모델의 경우 T 자세의 bind pose 자체가 기본 vertex positions여서, animation 없이는 이 T 자세의 캐릭터 밖에 못쓴다는 말로 이해했다.
- 사실 glTF에서는 이 변환을 명시적으로 가지고 있지 않다.
- 이게 기본적인 구조인데, format에 따라 조금씩 다르다고 한다.
- glTF에서 node로 이뤄진 구조에서 rigging/animation 관련 내용들을 정리하면 다음과 같다.
- armature(skeleton과 같은 뜻으로 쓰이는 것 같다.) node가 따로 있는 것이 아니고, node의 일종이다.
- model bind pose가 이미 모델에 적용되어 있거나, inverse bind matrix에 premultiplied 되어 있기 때문에 bind pose라는 개념을 잊어도 된다.
- per-bone inverse bind matrices는 accessor를 통해 접근하며 buffer에 따로 저장이 되어 있다.
- animation은 external하게 지정가능하거나, keyframe spline으로 저장되어 있다
- 중요한 것은, 이 animation들이 localCS to parentCS 변환과 combined 되어있다는 것.
-
converToParent()에 해당하는 변환이 이미 위의 animation 결과에 반영이 되어있다는 뜻이다.
-
- 따라서
invBindMat(parent)도 필요가 없다.
- 정리해보면, grand-parert -> g-p
global(bone) =
… *invBindMat(g-g-p) * bindMat(g-p) * localTransform(g-p) *
invBindMat(g-p) * bindMat(parent) * localTransform(parent) *
invBindMat(parent) * bindMat(current) * localTransform(current) *
invBindMat(current) =
… *converToParent(g-p) * localTransform(g-p) *
converToParent(p) * localTransform(parent) *
converToParent(current) * localTransform(current) *
invBindMat(current) =
… *animation(g-p) *
animation(parent) *
animation(current) *
invBindMat(current)- 각 색칠된 부분들이 같은 값에 대응된다고 보면 된다.
- 이 global(bone)에 적용될 vertices는 bind pose 상태인 mesh의 vertice다.
- 최종적으로 skin이 함께 가지고 있는 정보는, 각 bone에 해당하는 inverse bind matrices이다.
animation
animation channels
- target을 지정한다. target은 node와 path로 구성된다.
- path를 먼저 설명하자면, path는 translation, rotaion, scale 중 하나의 타입을 지정한다.
- node는 아래의 sampler를 통해 계산된 결과가 local transform으로 저장될 노드다.
- channel은 어떤 sampler를 사용할지도 참조한다.
animation samplers
- sampler는 keyframe의 in/out data와 interpolation 타입으로 구성된다.
- input은 keyframes, output은 path에 해당하는 transform이다.
- 원하는 time이 어느 keyframe 구간에 속하는지 찾은 후, 그 구간에 위치한 비율에 따라 output을 interpolation한 결과 transform이 channel에 명시된 node의 local transform에 저장된다.
- 보통 binary search를 통해 그 구간을 찾는다.
- interpolation 방식은 linear, step, cubic spline등이 될 수 있다.
- node가 joint에 해당하는 node이면 skinning과 결합된 animation을 만들어낸다.
data transfer structure
- 각 model instance 의 변환
- model instance가 움직이거나, 다른 색을 가지거나 하는 것등을 표현하기 위해 dynamic UBO를 쓰기로 결정했다.
- 이 값은 model에 포함될 수 없다. (같은 모델이더라고, 여러개 생성해서 다른 위치에 보여주고 싶은 경우)
-
maxUniformBufferRange가 65536 byte일때, 4x4 matrix 하나가 64 bytes 이므로, 대략 2^10개의 model instance를 표현할 수 있으므로 충분하다고 봤다. - 이 dynamic UBO는 매 frame마다 update가 이뤄지므로,
MAX_FRAMES_IN_FLGHT수 만큼 중복해서 생성해줬다. - 주의해야 할 점은 aligment관련이다. 이를 위해 ubo크기보다 크게 padding을 넣어서 buffer를 생성해야 할 수 있는데, 다음 자료를 참고했다.
https://vkguide.dev/docs/chapter-4/descriptors_code_more/
- skin 당 joint(bone) 의 수를 제한을 64로 뒀다.
- 어차피 한 vertex 계산에 필요한 joint matrice는 4개이긴 하지만, 그 4개는 joint index를 통해 접근한 값이다.
- 결국 draw전에 64개의 joint matrices 전부를 bind 해야하긴 하다.
- node matrix와 이 joint matrices는 mesh에서 소유하는 uniform buffer로 전달한다.
- 이때 각 joint node의 global transform을 구하는 과정에서, 매 frame마다 이 UBO의 update가 이뤄진다. 따라서 이 ubo는
MAX_FRAMES_IN_FLGHT수 만큼 중복해서 생성해줬다. - 이 data는 크기가 크기도 하고, model마다 skin이 여러개 있을 수 있기때문에, dynamic UBO로 생성하기에는 offset mapping 도 적절치 않아 이런 구조를 사용하게 됐다.
- 이후에 vertex shader가 아닌 compute shader에서 미리 animation을 계산할 경우에도, 모든 skin에 대해, 각 skin 하나에 해당하는 UBO의 내용을 묶어서 하나의 SSBO로 전달하고, vertex의 attribute에 skin index를 추가해주는 구조로 사용이 가능하다.
이에 해당 descriptor set 부분까지 작성을 완료하면, 다음처럼 animation이 없는 model instance를 그리는 것이 가능해진다.
Progress
모델
glTF-Sample-Models/2.0/Fox at master · KhronosGroup/glTF-Sample-Models (github.com)
해당 모델에는 rigging 작업이 이뤄져있어서, blender로 열어보면 다음처럼 skeleton과 그에따른 animation을 확인 가능하다.
Progress-0
- axis
- blender에서는 model의 up이 +z 방향인데, glTF로 export하면서 +y로 변환하는 옵션이 있어서 사용했다.
- 예제들 project에서 사용하는 world space상, -y가 up이기 때문에 위 아래가 바뀐다.
- pretransform
- axis 관련해서, model을 loading 할때, pretransfrom과 flipY기능을 넣어놨는데, 헷갈릴 수 있어 모두 사용하지 않고 loading했다.
- ubo
- data transfer structure 계획에 맞춰서, joint matrices와 model matrix를 넘겨줄 buffer와 descriptorSet을 구성한다.
- descriptor Pool size 관련 수정도 유의해야 한다.
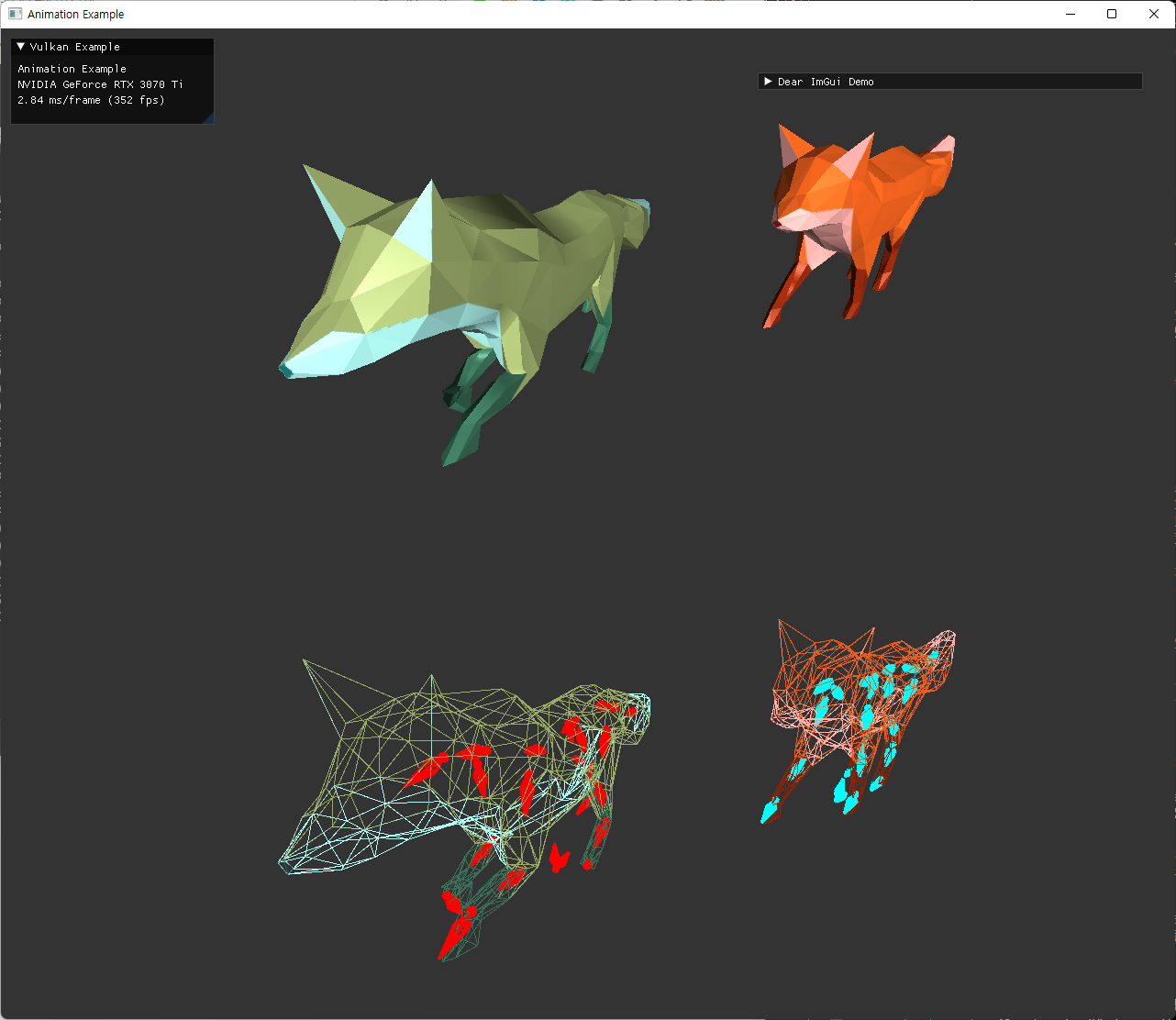
animation과 pretransform 없이 model instance만 생성하면 다음과 같은 화면이 렌더링된다.
fix
- index
- drawIndexed 만 지원했었는데, glTF 모델에 index 정보가 없는 경우 사용하지 않도록 추가했다.
- normal
- glTF 모델에 vertex attribute로 normal vector 정보가 없는 경우, 직접 삼각형으로부터 계산하도록 추가했다.
- skeleton
- skeleton draw 과정을 처음부터 추가하려 했는데, animation 없이 joint에 저장된 초기값을 사용해서 skeleton을 구성할 수 있을 줄 알았다.
- 예상된 skeleton이 나오지 않았는데, glTF에는 bind pose가 명시적으로 필요 없다는 내용을 보고 이 부분 구현은 animation 이후로 조정했다. (bind pose 가 mesh 자체에 적용되어 있으니 )
- 이 bind pose의 bones에 대해서 아직 명확히 해결책을 찾지 못했다.
- blender 에서는 glTF model의 import 할 때, guess original bind pose 라는 옵션이 있는데, 이걸보면 명시적으로 저장되진 않았지만 guess는 가능한 것 같다. 그리고 joint node의 transform 으로 들어있는 초기값도 의미가 있는 값인지 확인하지 못했다.
| animation 추가 과정에서 발생가능한 문제 경우들 | |
|---|---|
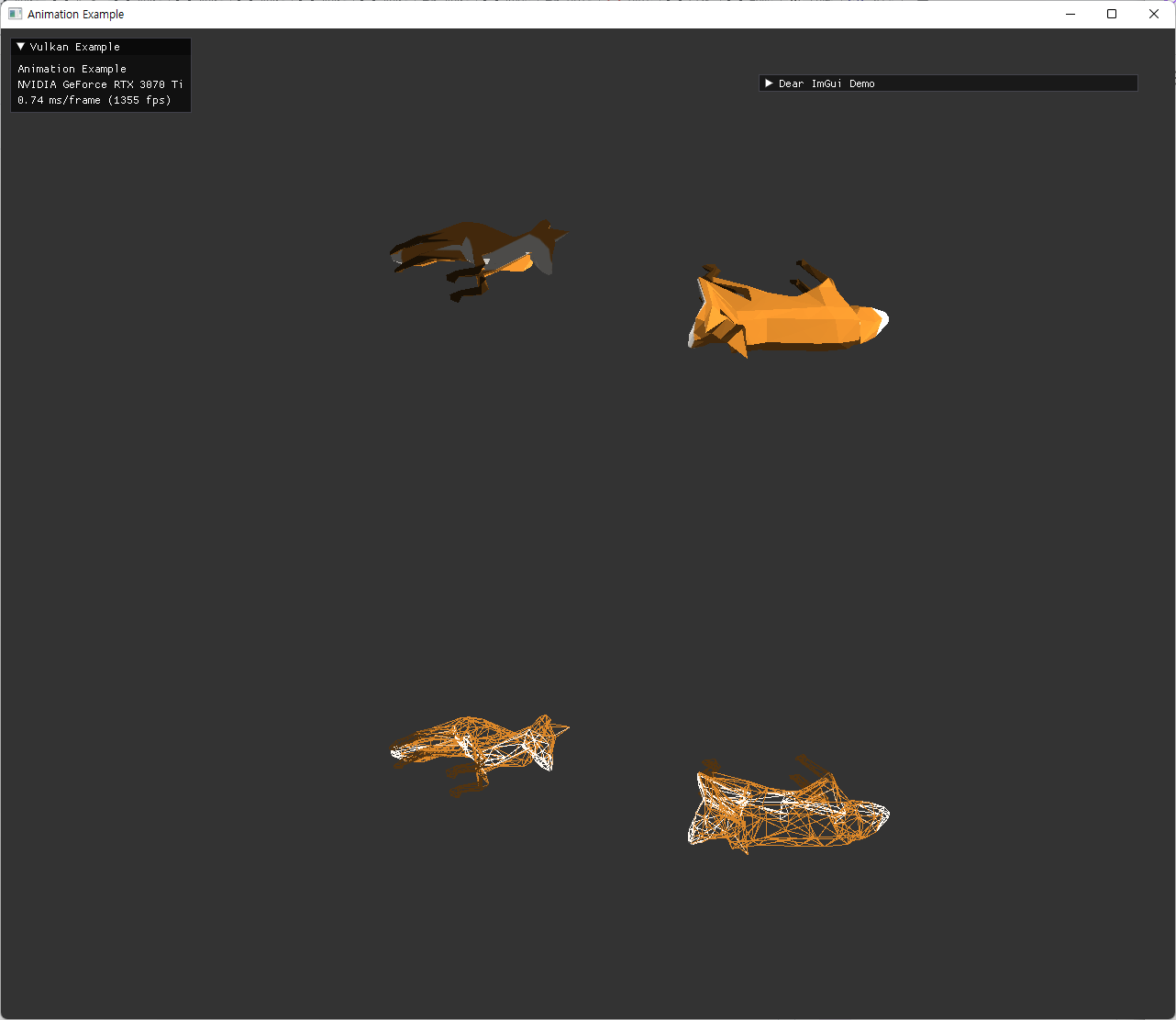 |
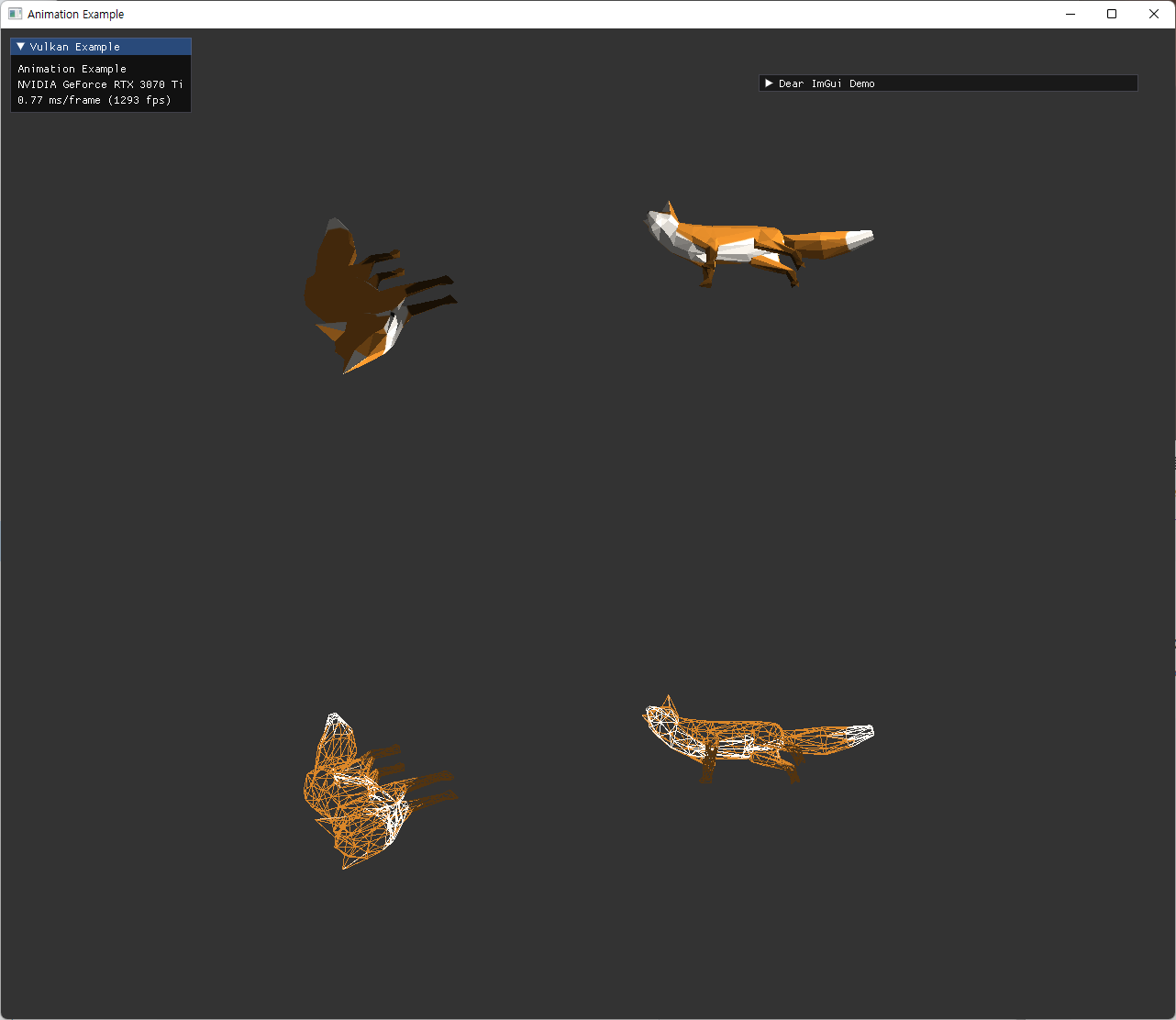 |
| pre-transform 관련 문제가 있을 때 | |
 |
 |
| animation 없이 초기 joint matrices value 활용 시 문제 | inverse bind matrix 사용하지 않았을 시 문제 |
Progress-1
skinning and animation
- skinning과 animation structure와 update animation 관련 함수를 추가한다.
- skin
- 여러 joint Node를 raw ptr의 vector로 참조한다.
- 그 순서에 맞게, inverse bind martices를 vector로 가진다.
- 이 skin data의 소유는 model에서 하고, 각 node에서 skinned mesh를 가지는 경우는 skinIndex와 skin data의 raw ptr을 참조한다.
- animation
- animation channel들과 sampler들을 소유한다.
- animation channel
- path type과 대상이 될 node의 raw ptr을 참조한다.
- 이 node ptr을 통해 node의 transform을 변경할 것이므로, const가 아닌 raw ptr이다.
- animation sampler
- interpolation type
- key frame inputs를 vector로 가진다.
- output vec4를 vector로 가진다.
-
updateAnimation()- args
- frameIndex: node의 UBO 변경하므로 필요
- animationIndex: 한 model에 여러 animation이 있을 수 있다.
- time: animation에 사용될 time stamp
- repeat: animation을 반복할 것인지에 대한 설정
- repeat 여부 및 key frame 값 범위를 통해 입력 time으로부터 samplerTime을 구한다.
- samplerTime으로 binary search를 통해 포함하는 구간을 찾는다. (
std::upper_bound()) - 그 구간의 값으로 normalized 된 samplerTime의 값
u를 구한다. -
u값을 비율로 지정해서 그 구간의 양쪽에 해당하는 channel의 outputs 두 값을 interpolation한다. - 계산된 결과를 node의 transform으로 지정하는데, 이 type은 path type에 따라 translation, rotation, scale 중 적절하게 변환한다.
- 위 과정을 animation의 모든 channel에 대해 반복한다.
- joint matrices 들이 변경됐을 것이므로,
updateNode()를 호출해 UBO를 update 한다.
- args
- skin
skeleton rendering
이전에 추가 했던 skeleton rendering 부분에 대해 문제가 있었는지 재 점검하고 다듬었다. 결론적으로 기존 로직에 문제는 없었다. 흐름은 다음과 같다.
- model class에
getSkeletonMatrices()를 구현한다.- 모든 skin의 joint matrices를 외부로 반환한다.
- 얻어온 값은 example class의 dynamic UBO에 사용된다.
- bone에 해당하는 수 만큼 미리 bone의 모델을 여러개 생성해놓는다.
- 이 bone instance 하나 자체도 dynamic ubo를 통해 전달할 수 있으므로, 각각 bone에 얻어온 joint matrix를 적용해준다.
- 이때 pre-multiply로 bone의 scale을,
- post-multiply로 bone이 표현할 대상 model instance의 modelMatrix를 곱해준다.
- 이후 draw에서도 이 여러 bones를 모두 draw해준다.
 bone 모델은 blender를 사용해서 간단하게 만들었다.
bone 모델은 blender를 사용해서 간단하게 만들었다.
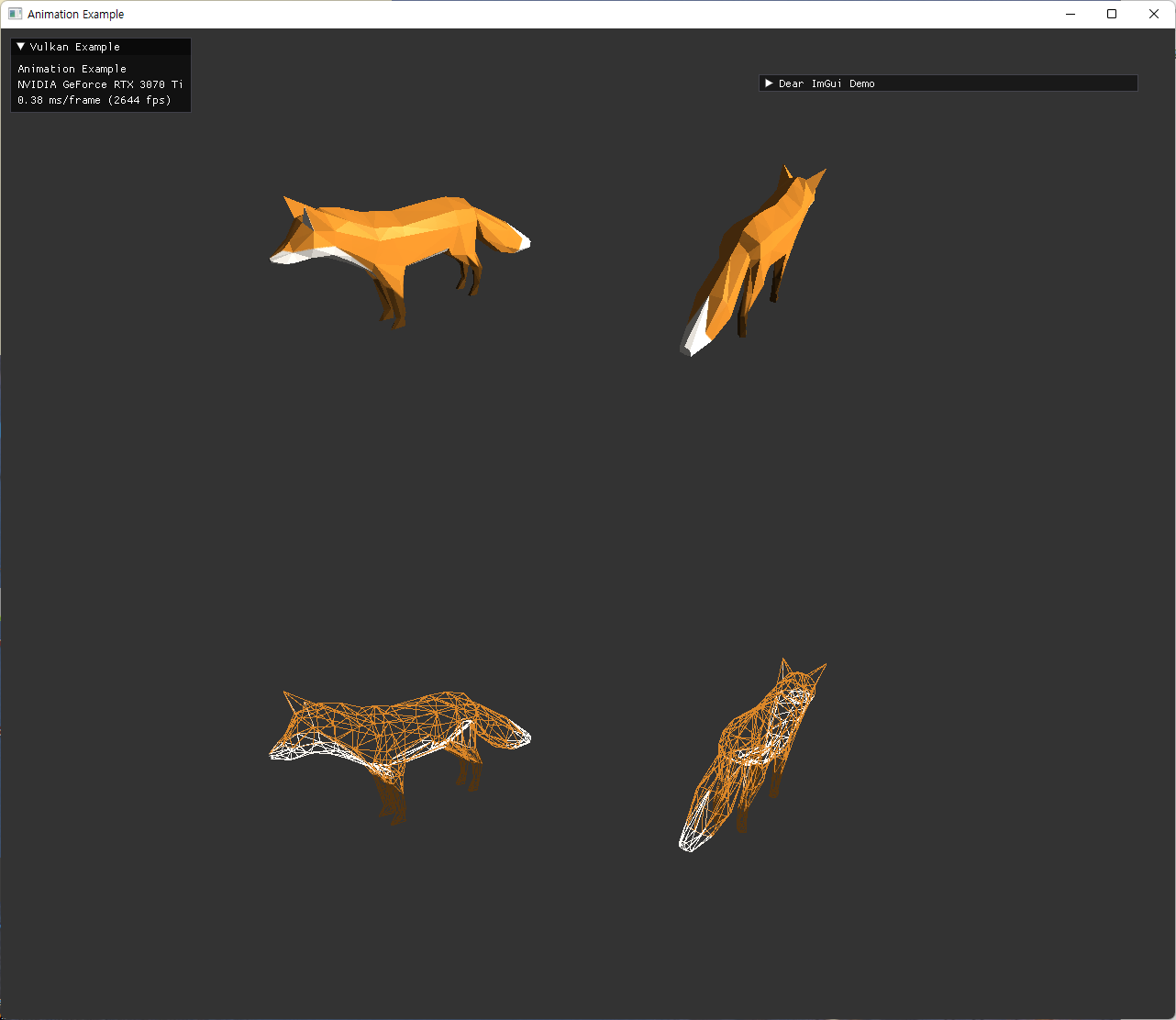
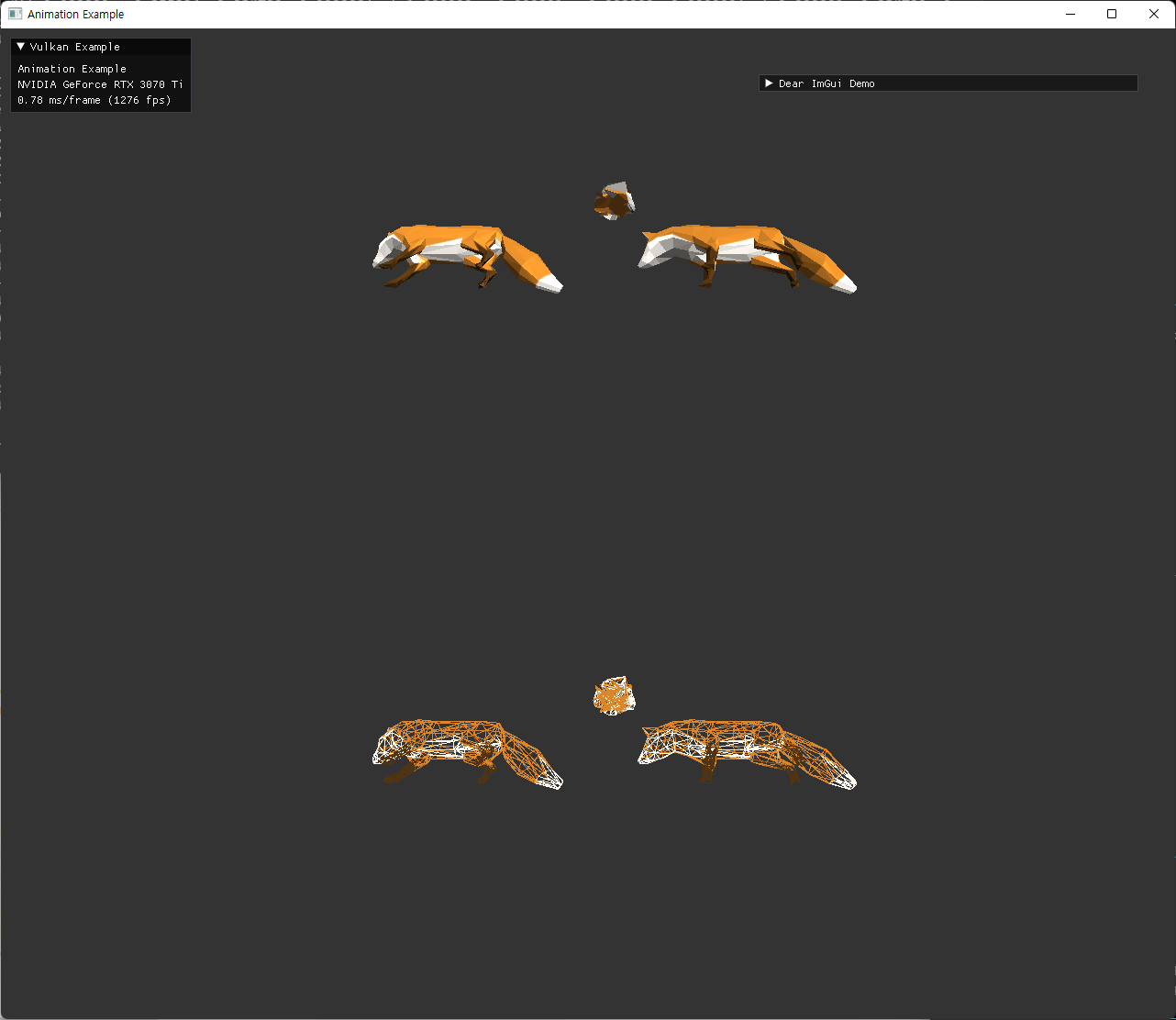
| bind pose의 bones를 의도했지만 실패한 것 | animation 중인 bones |
|---|---|
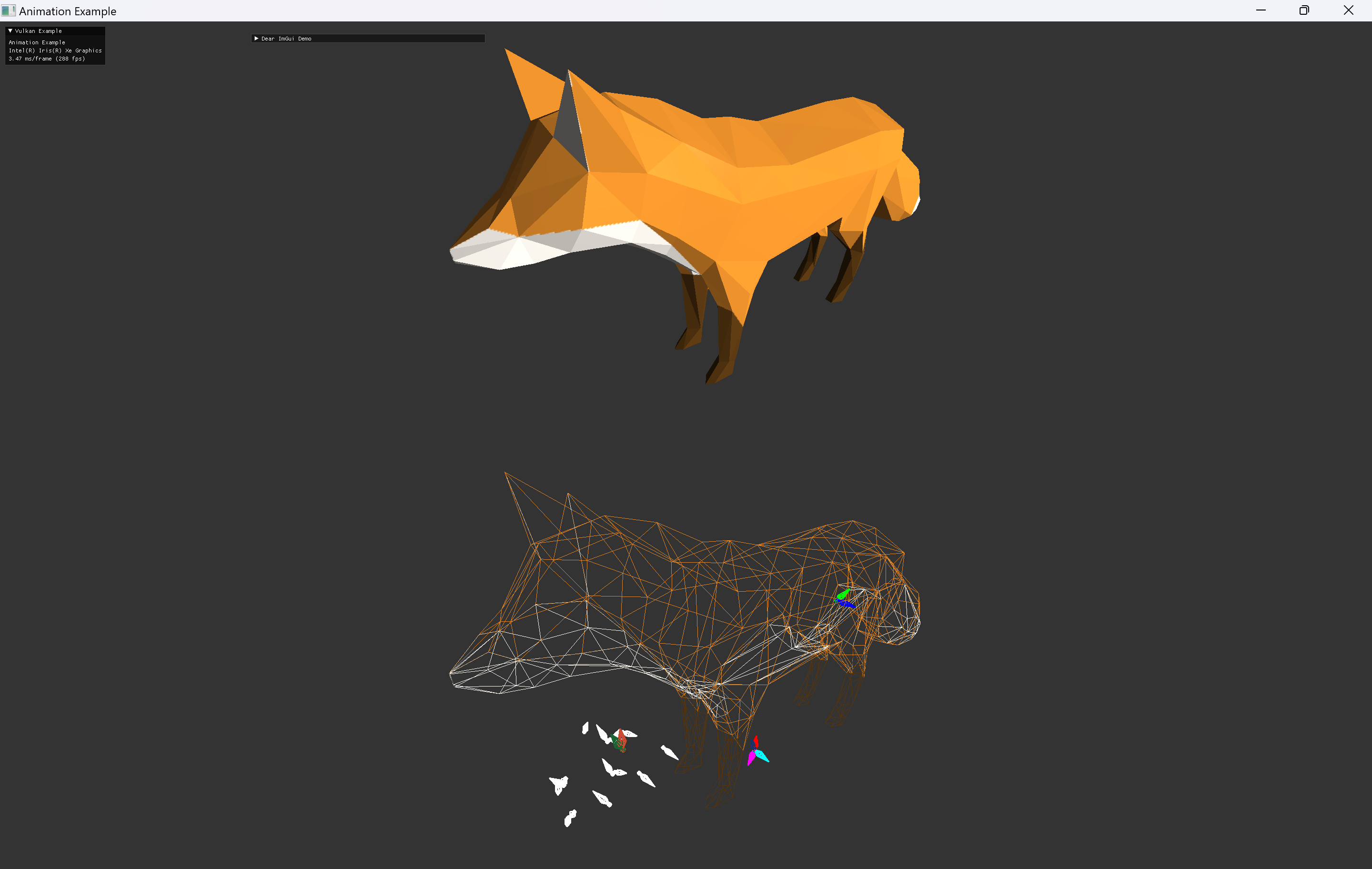 |
 |
좌측의 이미지는 이전 step에서 실패 했던 bind pose의 skeleton을 그리려는 과정이다. 처음에는 좌표축이나 변환의 문제로 보고, 여러 방향과 위치를 다른 색 bone으로 rendering 해보면서 원인을 파악하려 했는데, 변환이나 좌표축 문제는 아닌 것으로 결론지었다.
우측의 animation 구현 후, skeleton이 제 위치에 맞게 출력된 것으로 보아 skeleton과 animation은 제대로 구현된 것을 확인할 수 있었다. bone의 방향과 길이가 적절치 않은 문제는 남아있는데, 이 부분은 다음 step에서 다시 확인한다.
instance map
다음으로 넘어가기전에, 여러 model instance를 관리하기 위한 구조를 작성했다. bone이 많아지니 model instance가 갑자기 늘어나서, 단순히 index로 관리하기에는 복잡해서 instance 이름을 활용한 map을 추가했다.
- Model instance는 model을 shared_ptr로 소유한다.
- 같은 모델의 instance를 여러개 생성하기 위한 의도로 작성했는데,
- 현재 구현에서는 같은 모델이지만 animation이 다른 경우는 분리된 model을 만들어야 하는 한계가 있다.
- instance name과 bone model 인지 여부, animation index, animation time을 가진다.
- model instance 들은 vector로 example에서 소유한다.
- name과의 mapping을 위한, instance map은 name을 key, index vector를 value로 가진다.
- 같은 이름을 가지는 instance 여러개를 저장하기 위함인데, instance가 vector에 순서대로 저장돼서 굳이 사용할 일은 없었다.
- model을 추가할 때는,
addModelInstance()함수를 사용한다.- instance index는 현재
modelInstances의 size로 지정한다. -
modelInstances에 새로운 model instance를 추가한다. -
instanceMap[name]에 해당 index를 추가한다.
- instance index는 현재
- 모델을 찾을때는
findInstances()함수를 사용한다.-
instanceMap에서 name으로 access 한 index vector를 반환한다. - 보통 이 반환 결과의 첫번째 값만 사용하면 되고, bones의 경우 모든 값을 사용하면 된다. 혹은 첫번째 bone의 index를 찾는다면, bone count 만큼 증가시켜가며 사용해도 무방하다.
-
Progress-2
이제 여러 model instance를 다루기 편해져서, model을 늘리면서 남은 문제점들을 파악하고 있었다.
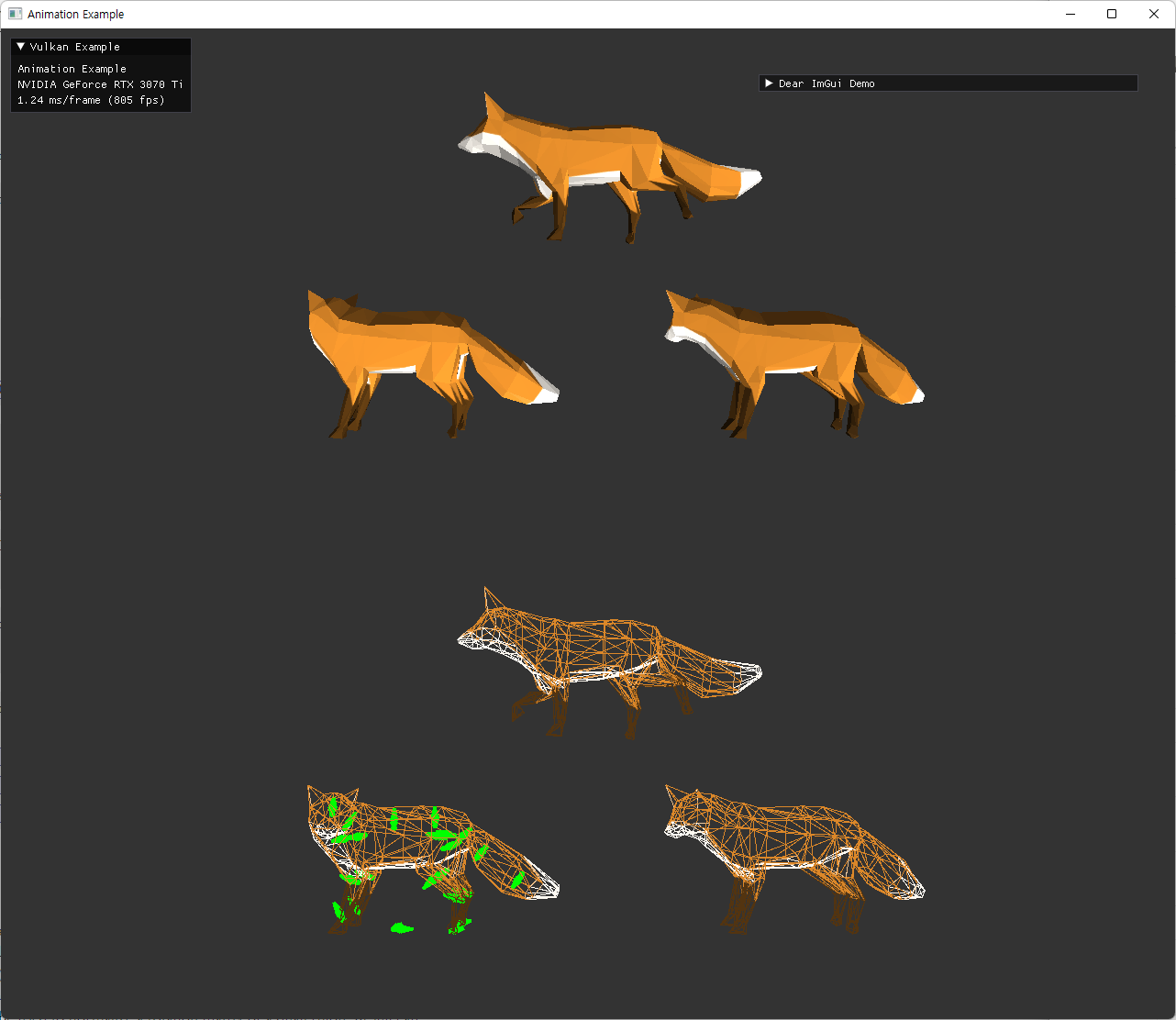
해당 과정에서, 기존에 사용하던 바로 받은 glTF 모델과, blender를 거쳐서 export 된 glTF 모델을 비교하던 중 다음과 같은 문제가 발견돼서 먼저 수정하고 진행했다.
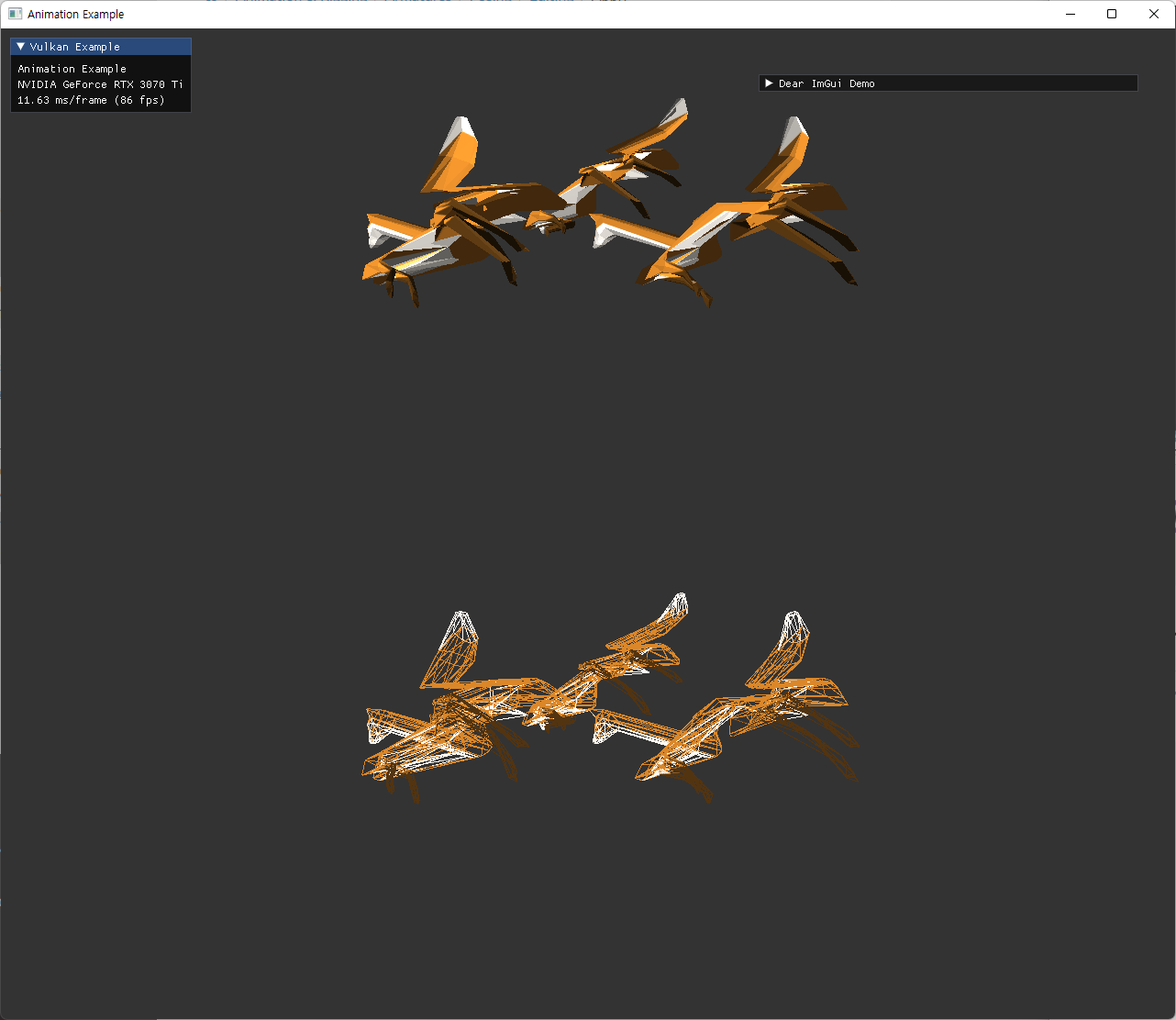
| laptop | desktop |
|---|---|
 |
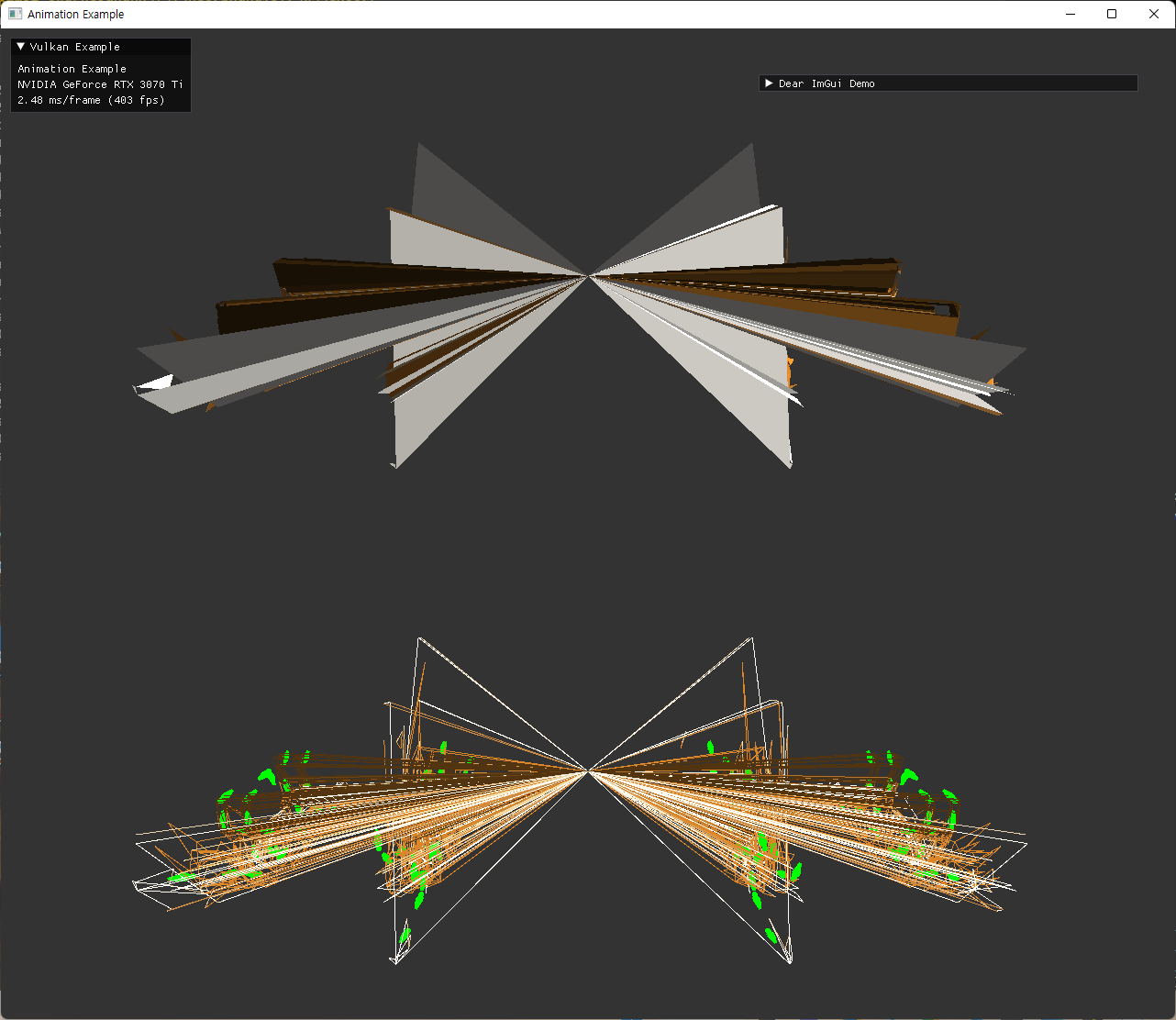 |
fix
다른 두 환경에서 undefined 된 상황의 문제가 벌어진 것으로 보여 디버깅 하면서 이상한 값이 변수에 들어있는지 확인하는 과정을 거쳤다.
이 부분에서 원인을 찾는게 시간이 오래 걸렸던 것으로 기억하는데, 결국 문제는 다음과 같았다.
- blender model을 사용하면서 문제가 생기기 시작해서 해당 model을 load한 직후 member 변수들을 살펴봤음.
- joint attribute 중 하나의 값에 4096이라는 수치가 들어있었는데, 이 값은 0x1000으로 joint의 index 값으로는 너무 큰 값이어서 이상했음.
- glTF specification을 확인하던 중, joint component의 type이 두가지가 가능하다는 사실을 알게됨.
- buffer와 accessor 를 사용하는 방식으로 gltf format에서 load후 접근할텐데, 이 단위가 맞지 않아 joint에 적절치 않은 큰 값이 들어가는 상황이 가능하다고 분석함.
- 기존 코드에서는 joint component가 unsigned-short인 경우만 구현이 되어 있었음.
- tinyGlTF 에서 load된 joint component type을
jointAccessor.componentType통해 알 수 있는데,TINYGLTF_COMPONENT_TYPE_UNSIGNED_BYTE와TINYGLTF_COMPONENT_TYPE_UNSIGNED_SHORT일때를 구분해서 처리해줌으로써 해결.
여담으로 model 관련 살펴보다가 추가로 알게된 사실인데, blender에서 modeling을 한 후, glTF로 export하면 vertex 수가 바뀔 수 있다(주로 늘어난다). 이는 glTF에서는 모든 mesh가 triangulation 되어야해서 export 하는 과정에서 알아서 변환해주기 때문이라고 한다. reimport 하면 달라진 mesh를 확인할 수 있다.
bone length and orientation
bone의 방향에 관해서는 위의 문제를 해결하니 바로 해결됐다.
- 기존 bone만 blender에서 export된 모델을 쓰고, fox model은 다운로드 받은 모델을 쓰고 있어서, 서로 axis가 달랐다.
- blender에서 export된 fox와 bone 모델을 사용하니 문제가 해결됐다.
| fixed fox, skeleton | ||
|---|---|---|
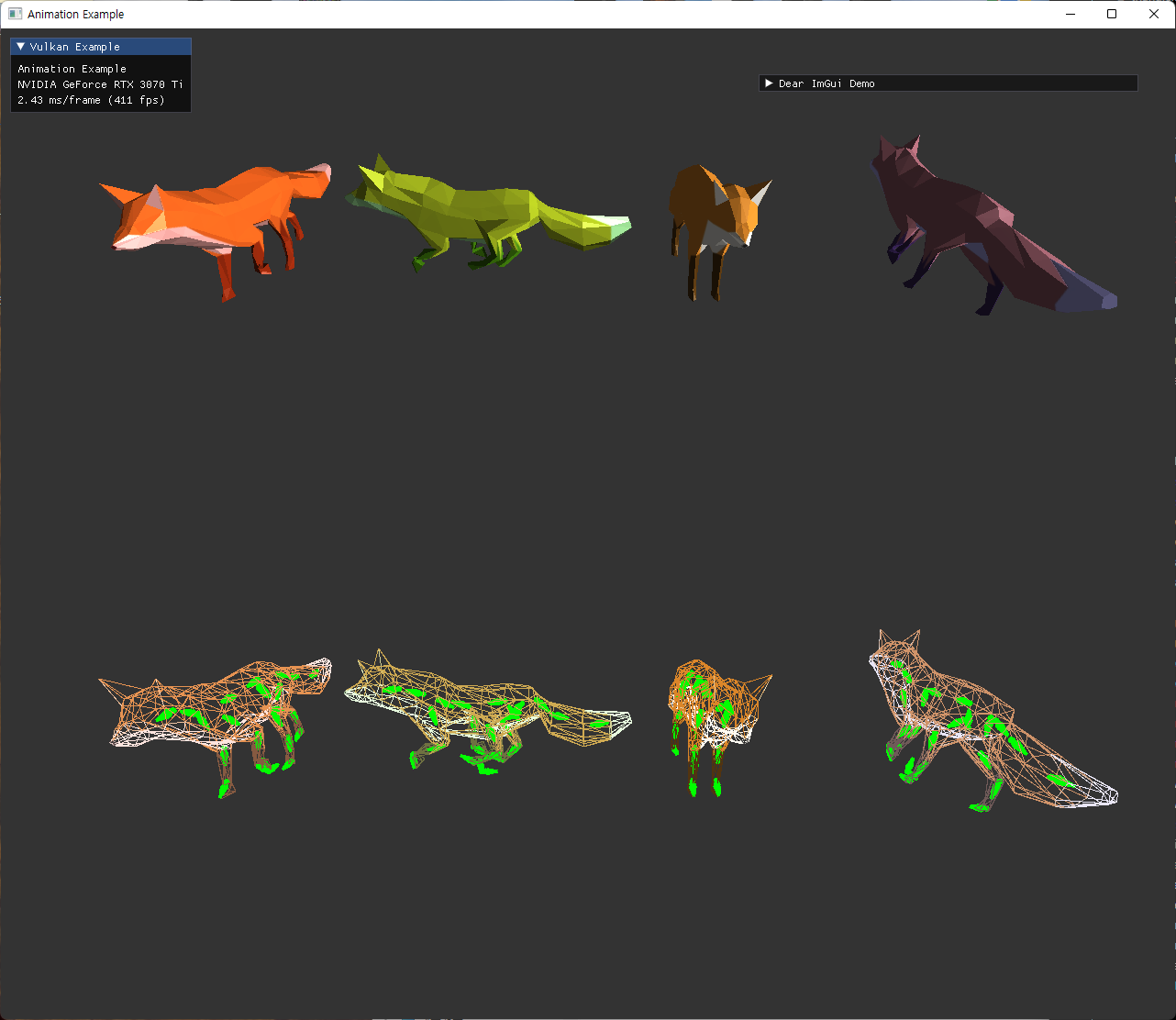 |
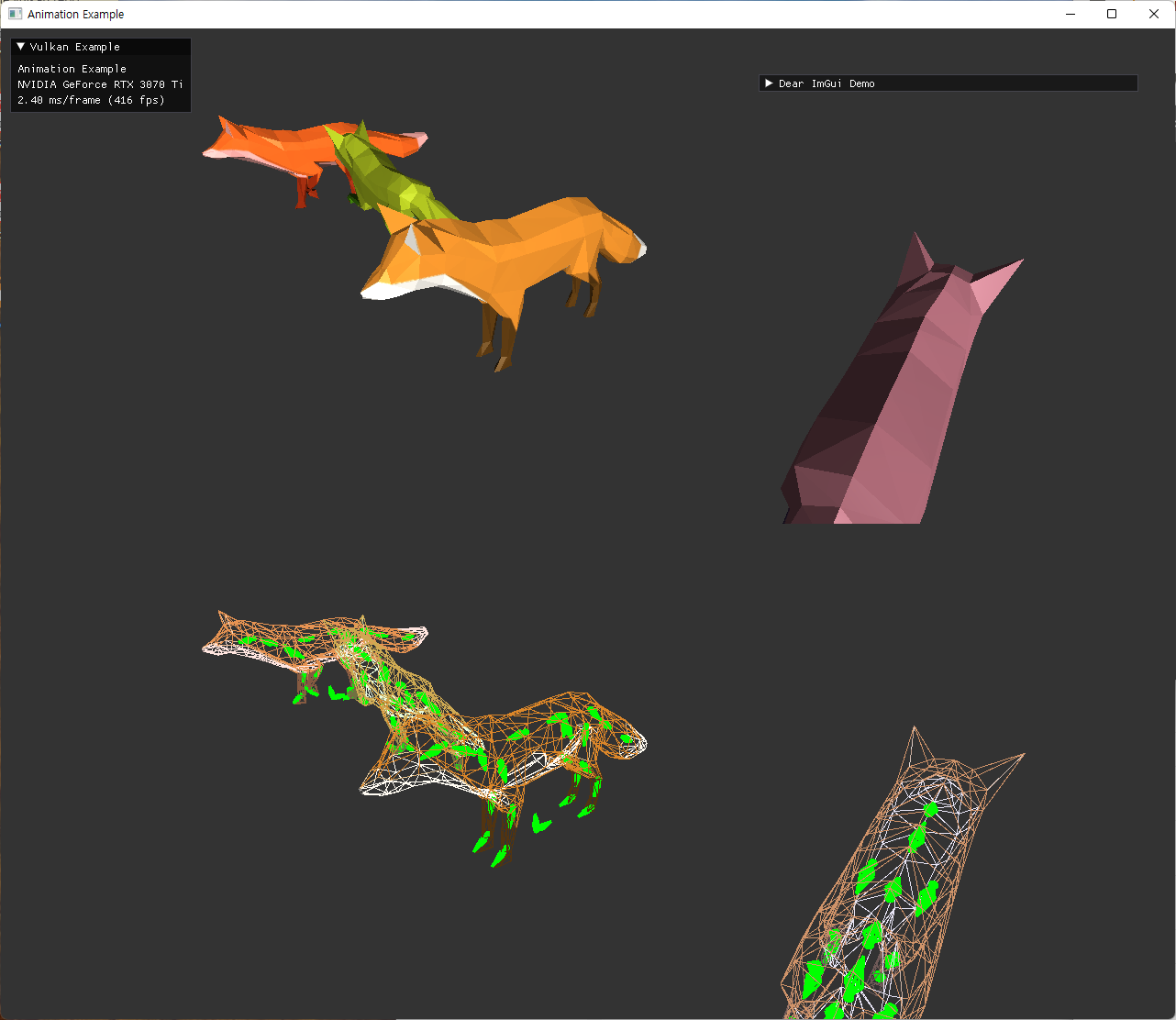 |
 |
bone의 length는 실제로 glTF에 명시적으로 저장되는 값이 아니라고 한다. 이미 length 개념없이도 animation과 skinning을 표현하는데에는 문제가 없었으므로, 보조적인 개념이라 최적화를 위해 포함하지 않는 것으로 이해했다.
bind pose or empty animation
animation을 쓰지 않은 type은 animation index를 -1로 주어 아예 skinning을 적용하지 않도록 처리해서 구현했다.
초기 joint matrix들에 들어 있는 값을 쓸 경우는 이상하게 뭉쳐진 skinning이 됐는데, 결국 이 초기 값은 bind pose와 관련있을 필요가 없다는 결론을 지었다. glTF specification에 이를 명시하지 않았기 때문이라고 이해했는데, 관련 검색 자료를 남겨놓겠다.
- https://github.com/KhronosGroup/glTF-Blender-IO/issues/360
- https://github.com/mrdoob/three.js/issues/24772
performance
debugging mode로 build했을 때, 생각보다 너무 느린 400 fps 정도가 측정됐다.
release mode로 build하니 4000 fps 가까이 측정이 돼서, validation layer나 optimization 관련 여부로 인해 차이가 큰 것을 확인했다.
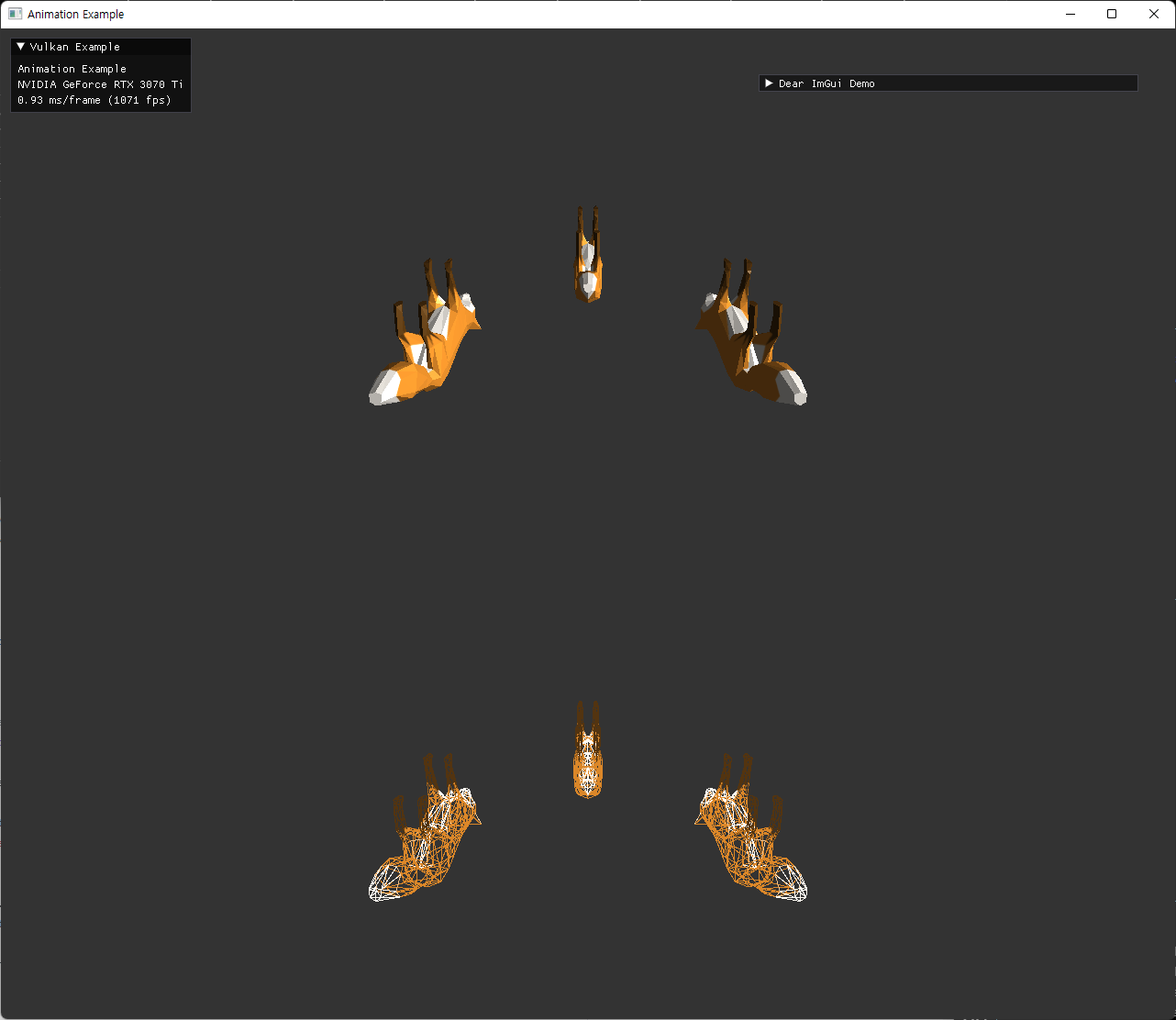
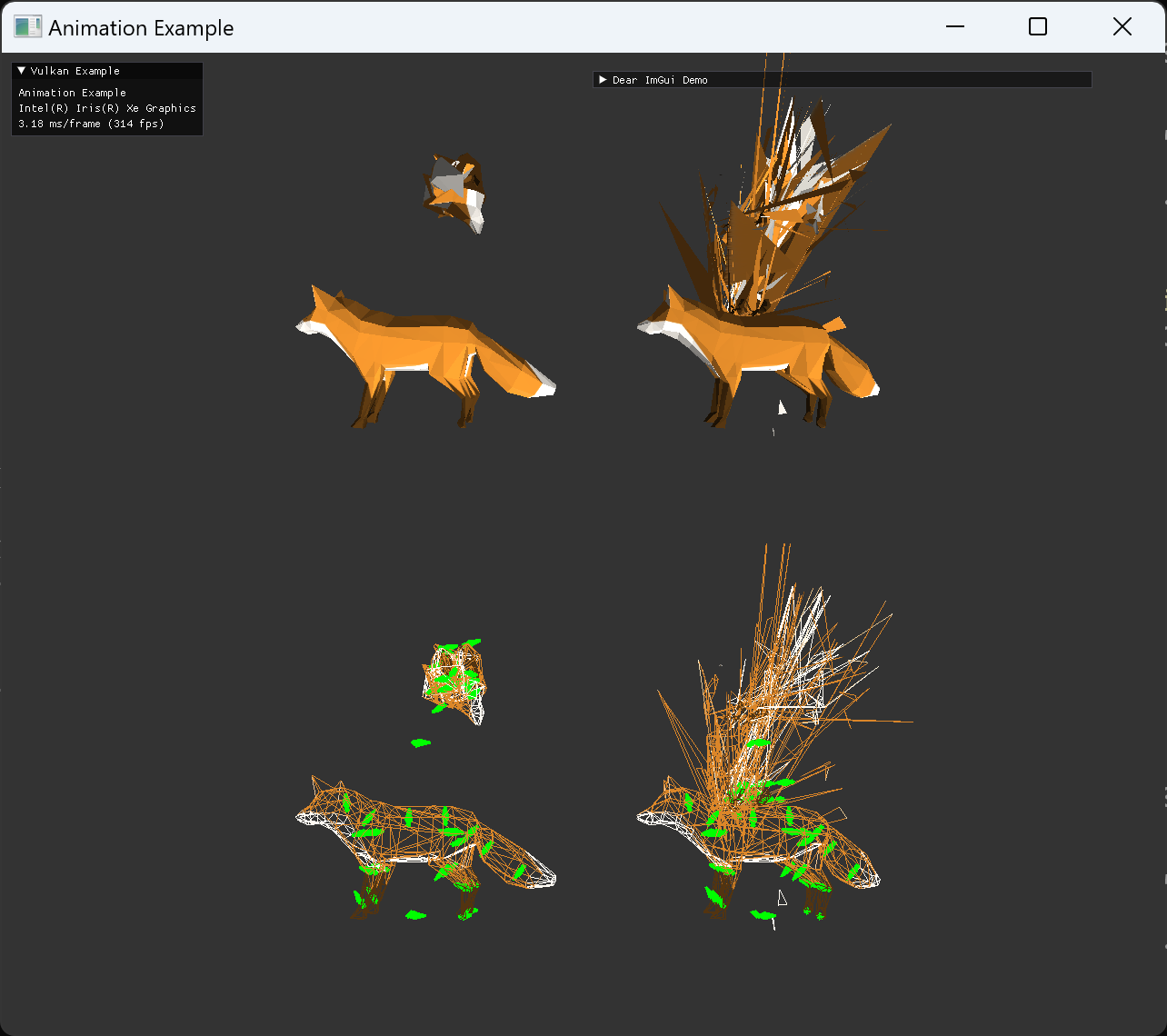
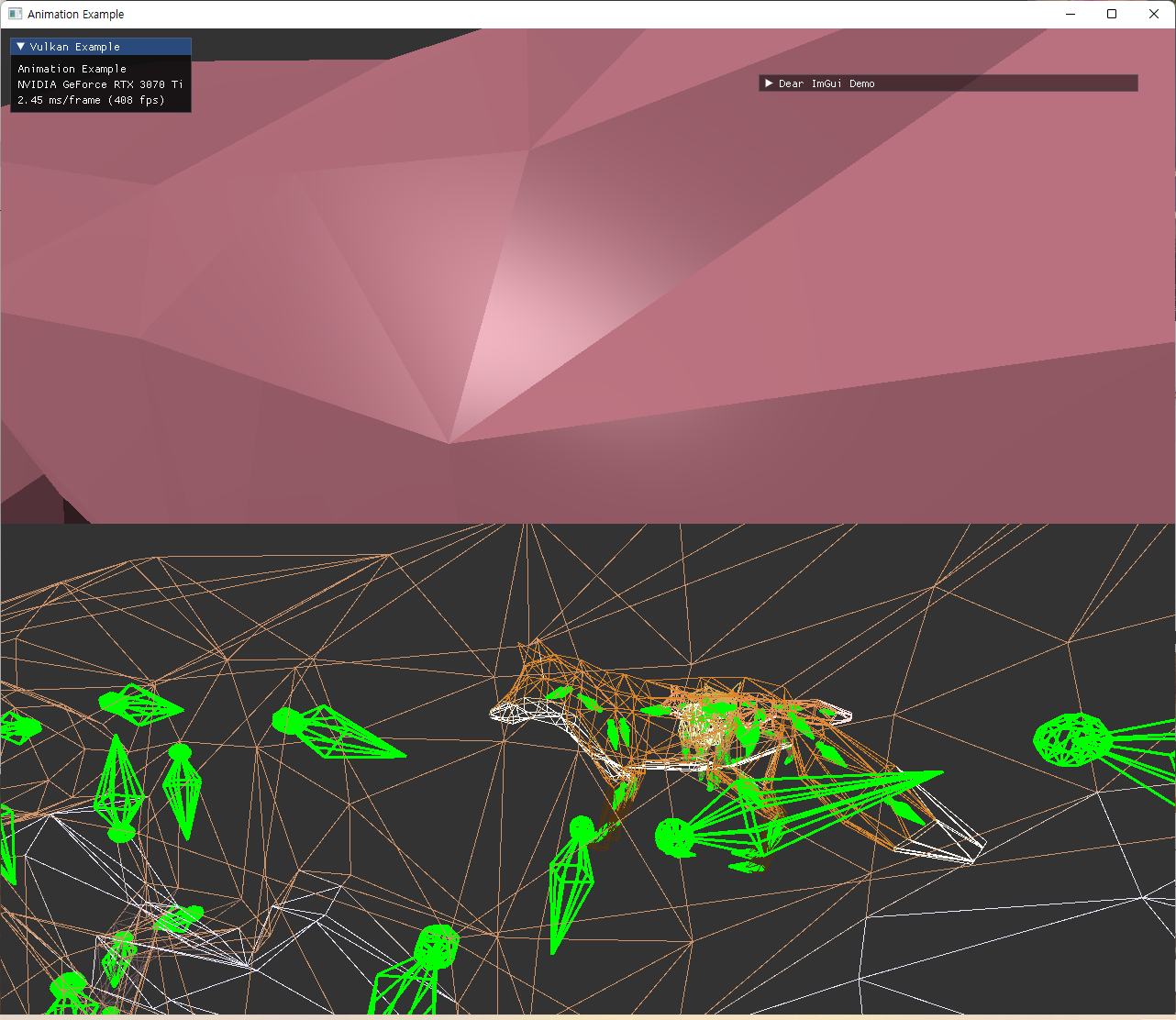
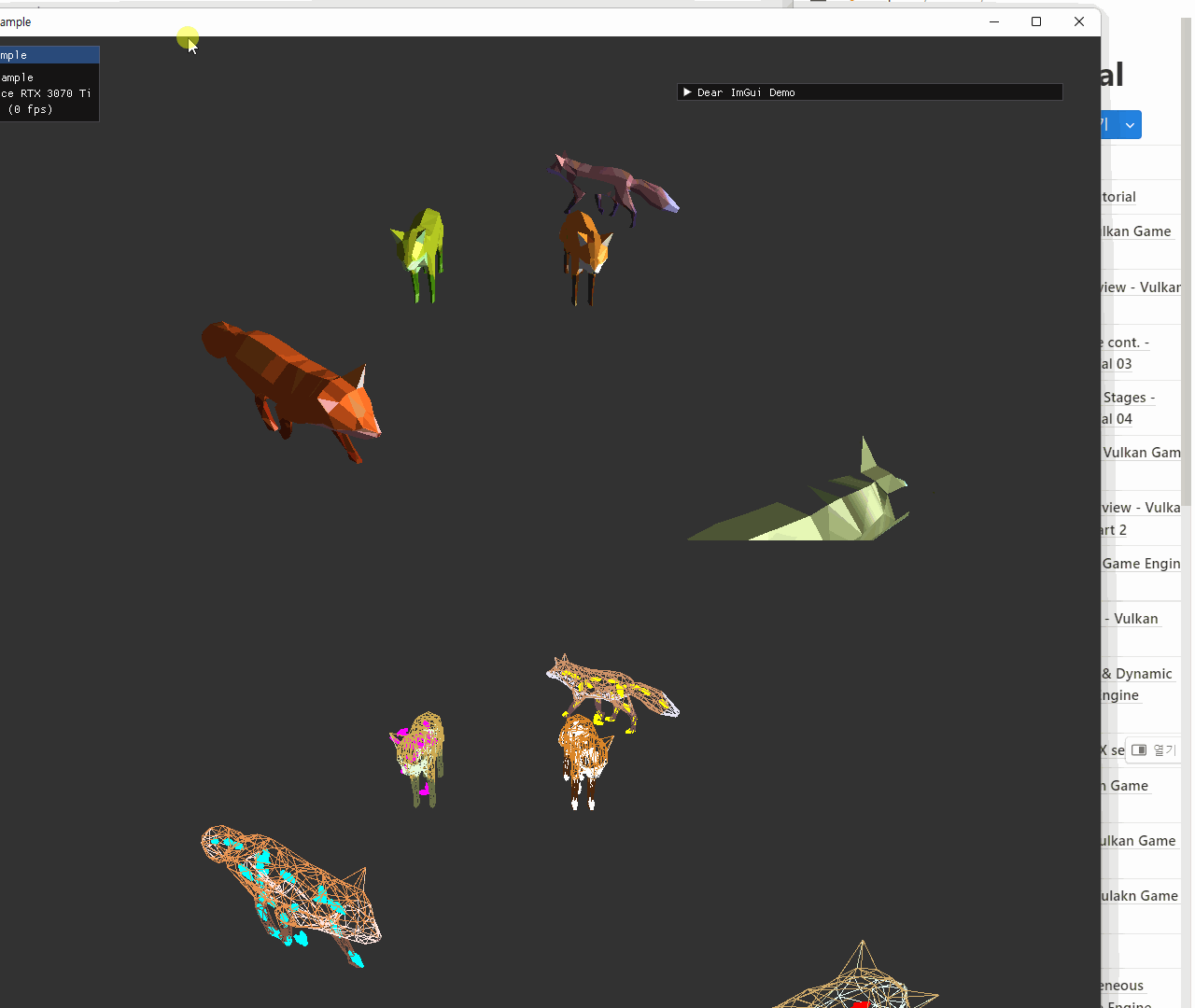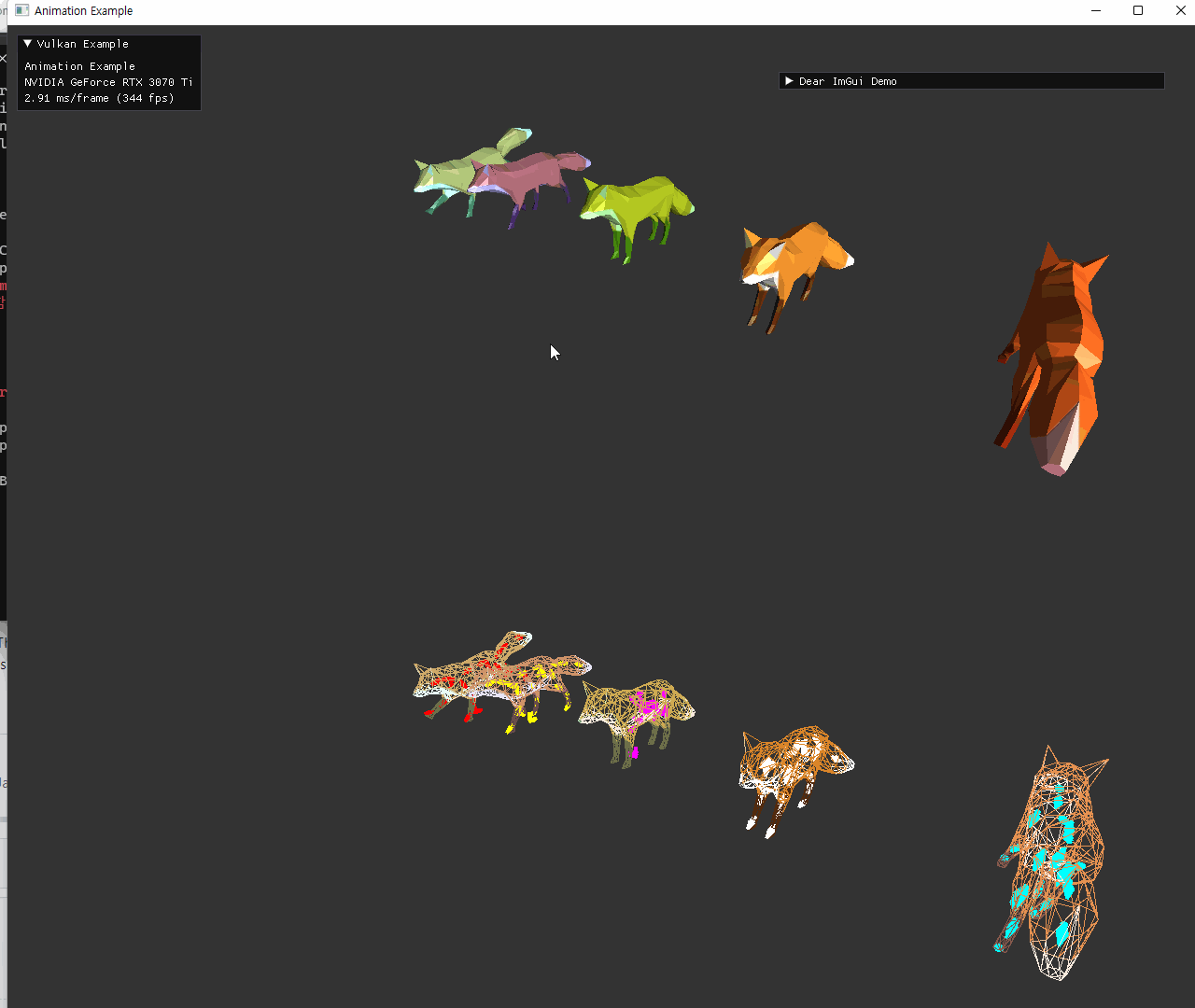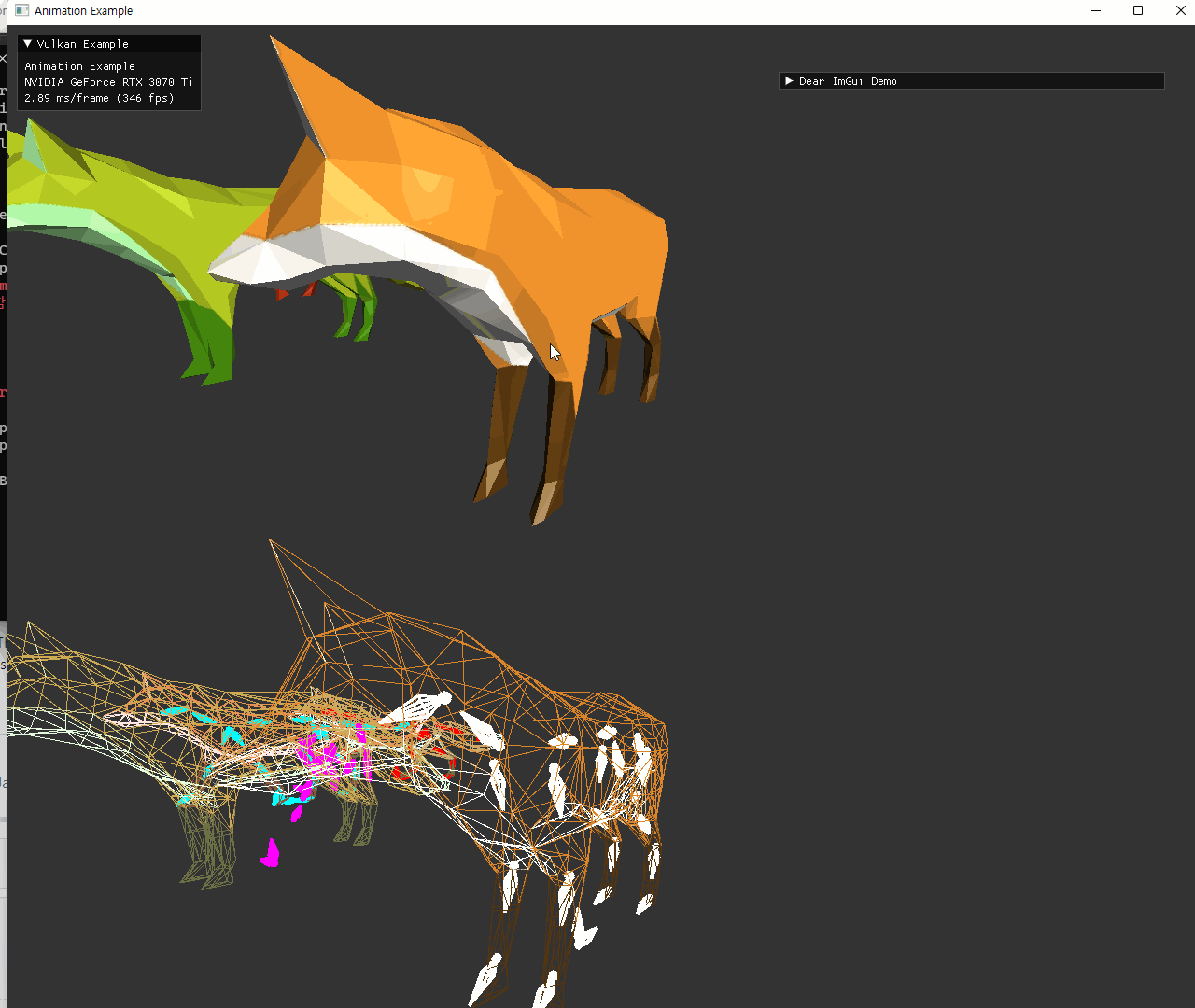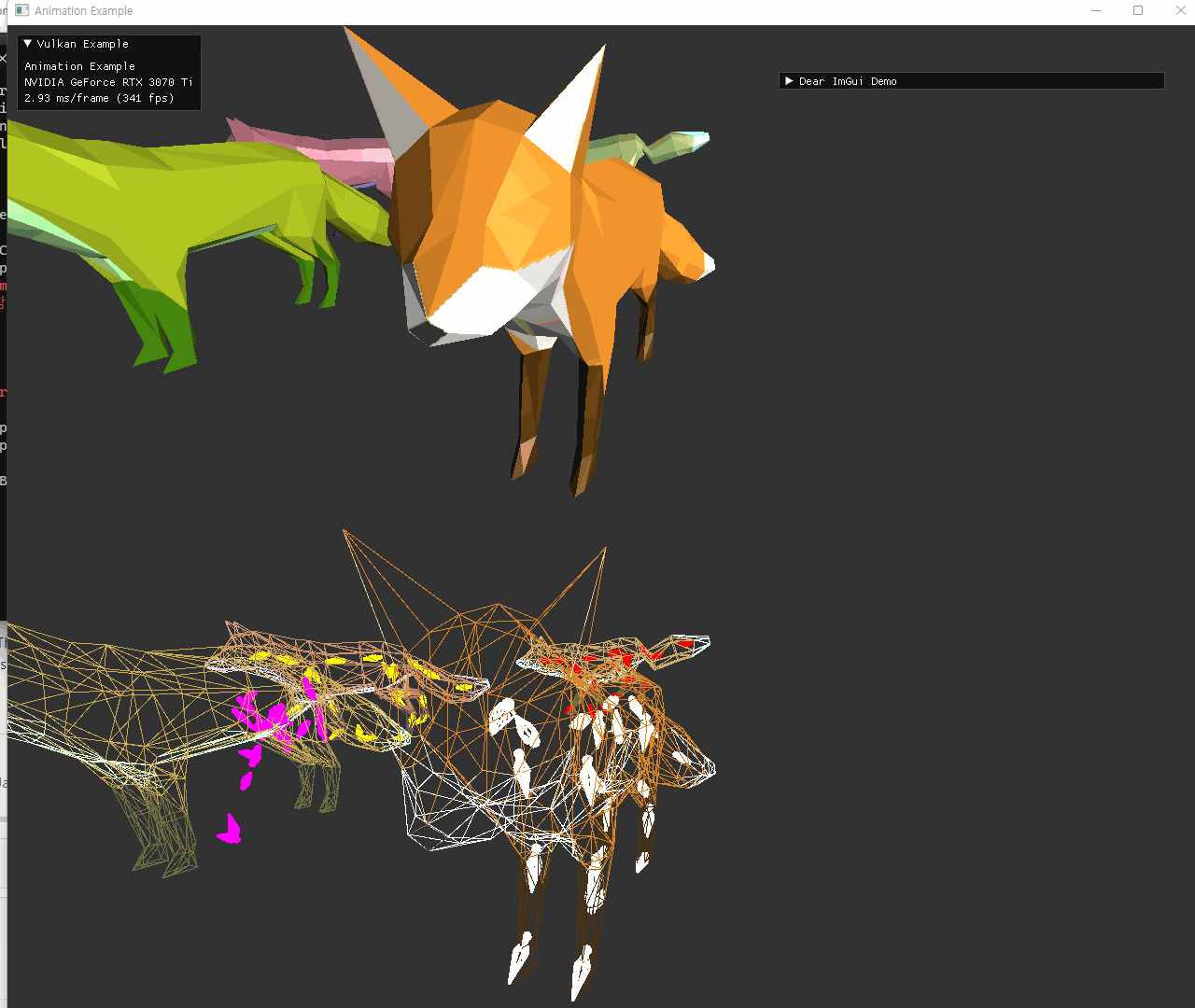
| dynamic UBO (color 적용 및 external animation) 추가한 최종 결과 | |
|---|---|
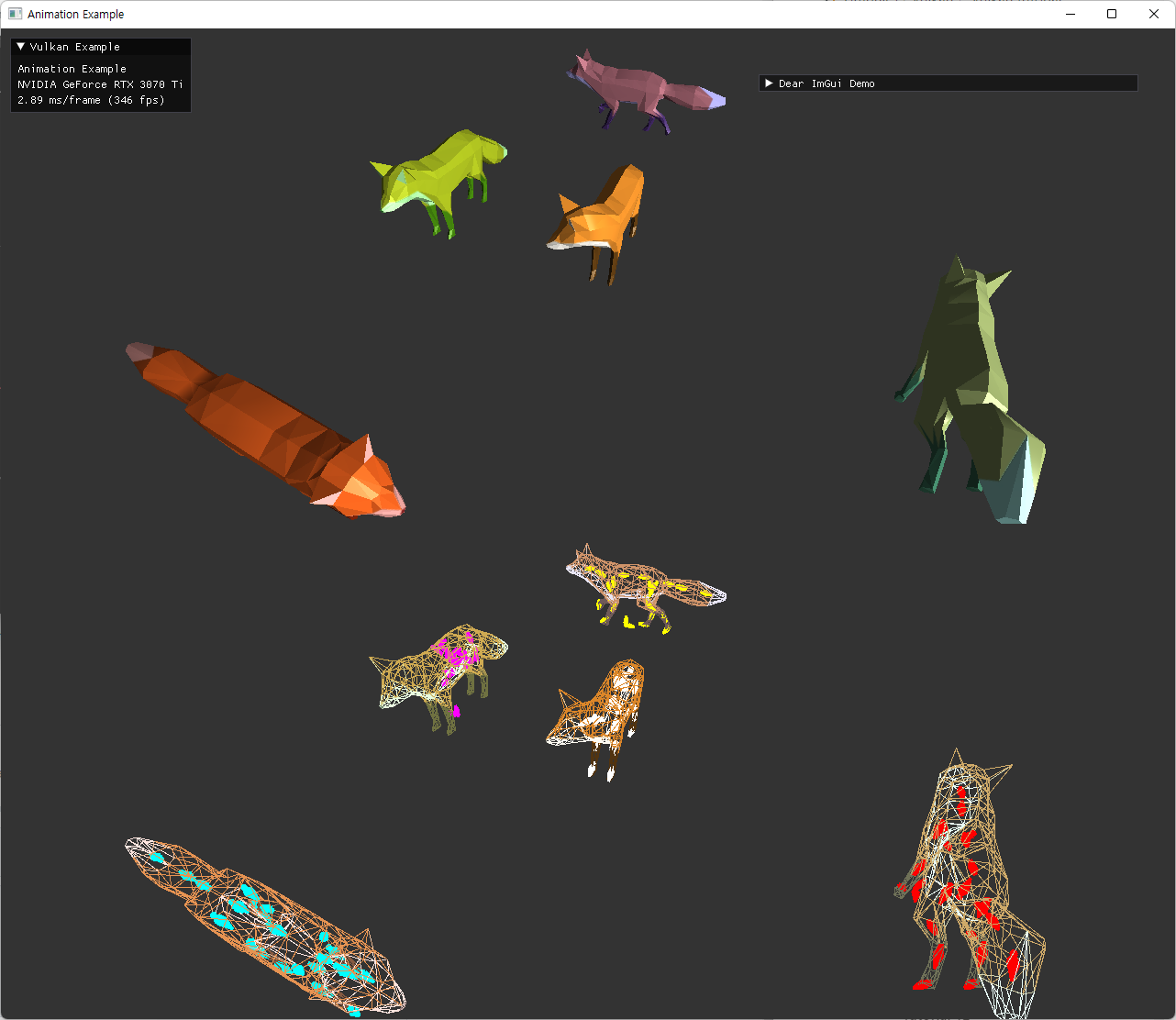 |
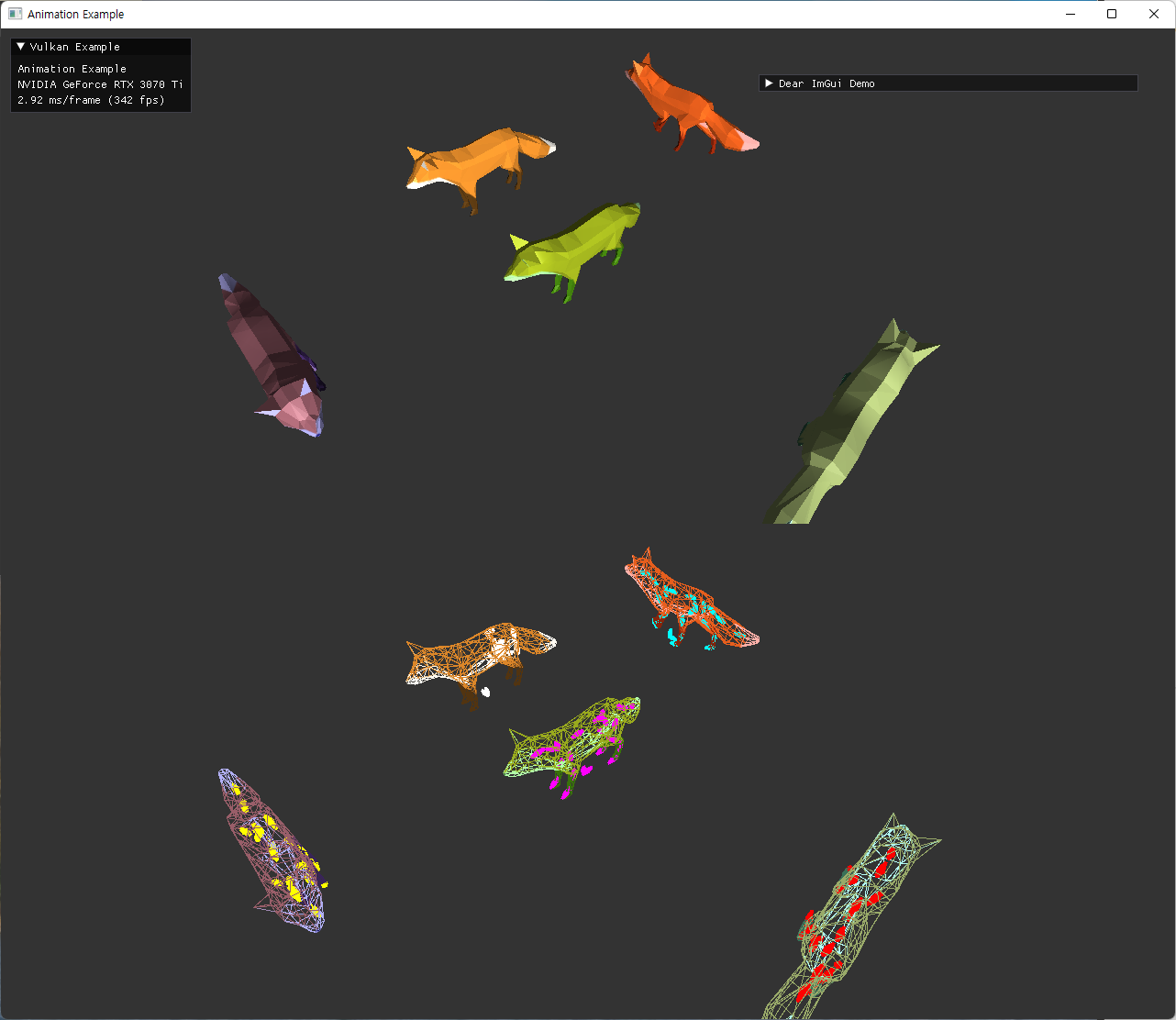 |
두 이미지 모두 중앙 좌측에 있는 정지한 fox model은 skeleton이 이상한 위치에 나오고 있다. 이 경우에는 joint matrices를 사용하지 않기때문에 skeleton도 의미가 없게 된다.
animation을 사용하지 않는 경우는, node::update() 가 초기에만 호출되고 이후에는 animationUpdate에서 호출하지 않게되면서 node UBO가 변하지 않게 되는데, 이 초기 설정에서 그 skinned mesh를 가진 node의 transform의 inverse만 가지도록 해줬다. identity를 주는 것이 node hierarchy를 표현하기 위해서 맞을지도 모르겠는데, 아직 이런 예시의 gltf파일은 사용하지 않아서 이 방식으로 유지해놨다. 추후 필요시 수정하면 될 부분이다.
마무리
animation 관련 개념을 다루고 rendering 하는 기본적인 예제를 작성했다. skeletal-animation 기본 개념을 알고 나서야, 다른 여러 sw나 format에서 사용하는 animation 구조가 다른 것이 아니고 이 기본의 생략되거나 변형된 방식이라는 사실이 보이기 시작했다. 이런 기본 개념을 먼저 이해하는 것이 선행되어야 하는 이유를 다시 한번 느꼈다.
skinning 과 animation model을 loading해서 rendering하는 것에 추가로, skelton rendering 과 dynamic uniform buffer 사용의 내용을 추가했는데, 이런 단순한 변경으로도 구조를 계획하고 구현 중 문제를 해결하는데에는 꽤 긴 시간이 소요됐다. 특히 중간에 debugging 하는 과정에서 원본 glTF 예제에서 가져온 부분에서 내가 사용한 model을 커버하지 못하는 케이스가 여럿 발견됐는데, 단순히 code를 옮겨서 사용하기만 했다면 찾기 더 오래걸렸을 것이라는 생각을 했다.
그러면서 How to Learn Vulkan 내용이 생각나서 다시 읽어 봤는데, 단순히 typing 할빠엔 copy-paste를 하는게 낫다고 하면서 중요한 건 개념을 익히는 것이기 때문에 세세한 구현에는 너무 신경을 쓰지 말라고 한다. 또 own renderer를 만들면서 더 적극적으로 안써본 기능들을 실험해보라고 하는데, 이런 방향성은 잘 가고 있다고 생각했다. 지금 보다 좀 더 적극적으로 안써본 것 들을 쓰면서 목표를 공격적으로 잡아도 좋겠다고 느꼈다.
앞으로도 비슷한 방식으로 예제들을 추가해 갈 텐데, 다음과 같은 점들을 유념해야겠다.
- 기반이 되는 기본 개념 숙지 - spec과 api 문서 자주 보기
- 추가할 구조 및 변경점 계획 - 공격적으로 목표 설정
- 궁극적으로는 아예 참고할 원본 예제 없이 0에서부터 계획하기
- 참고한 코드가 추가/변경에 호환되는지 확인
- 모든 경우를 사전에 파악할 순 없으니, debugging에 익숙해지기