Resource
공부한 내용들이라 내가 새로 만든 내용은 없다고 볼 수 있다. 먼저 어떤 것들을 보고 학습했는지 열거해놨으니 미리 열어보면 글에 빠진 정보를 모두 얻을 수 있다.
- code implementation
- base (tutorial-27)
- tutorial
- model & texture
- reference
Vulkan
최근 관심가지게 된 그래픽스 API이다. 이전에 학부 수업에서는 OpenGL만 다뤘는데, 확실히 개발된 시기가 오래되다보니 예전 스타일의 구조가 보이긴했다. global state를 변경시키는 방식이 OpenGL의 방식인데, modern c++의 OOP나 RAII 등 방식과 차이가 있다. 하드웨어 기능도 발전이 많이 됐다고 하고 여튼 여러 이유로 Vulkan API 공부를 하기 시작했는데, 사실 내가 실제로 현업에 사용해본 경험은 없기 때문에 나중에 생기면 글을 새로 쓸 수도 있을 것 같다.
가장 확실한 학습 소스는 api docs를 통해서겠지만 내용이 상당히 많고, 변수나 함수명도 길어서 압도당하기 쉬운 것 같다(근데 다들 API docs 보기를 습관화 하라고 강조하는 것 같다). 그래서 Brendan Galea 라는 사람이 작성해준 youtube tutorial을 보면서 학습을 시작했는데 도움이 많이 됐다.
첫 삼각형 그리기만 해봐도 얼마나 많은 설정들을 내가 명시적으로 해줘야하는지 알 수 있었다.
27번째 영상 이후 tutorial이 더 나오지 않아서 공식 튜토리얼을 따라서 나머지 내용들을 진행하려고 한다.
이후 계획은 Sascha William 라는 사람의 github repo에 있는 vulkan example 에서 재밌어보이는 것들을 살짝 변경하거나 구현해보는 식으로 하려고 한다. 특히 compute shader 관련 내용이 재밌어보이기는 하는데 좀 더 진행해봐야겠다.
Vulkan Game Engine Tutorial을 따라가면서 마지막 단계는 alpha-blending 까지 였는데, 공식 tutorial과 내용이 완전 대응되진 않지만 texture 관련 내용부터 이어서 보면 적당해보였다.
Texture mapping
이전의 내용은 모두 Brendan Galea 의 tutorial 기반이니 skip하려 한다.
정리할 내용은 https://vulkan-tutorial.com 에서 읽은 내용 순서에 따라서 추가적으로 찾아본 것이니 강조할만 한 것들을 적어놓으려 한다.
앞으로 할 것들의 대략적 순서는 다음과 같다
- device memory(GPU 측)에의한 이미지 객체 생성
- 이미지 파일을 읽어서 픽셀값 채우기
- 이미지 샘플러 생성
- 이미지 샘플러 디스크립터(Descriptor)를 추가하고, 텍스쳐로부터 색을 샘플링
Images
vulkan에서 이미지를 생성하는건 vertex buffer를 생성하는 것과 유사하다.
Recap
buffervulkan에서 buffer는 graphics card에서 읽을 수 있는 메모리 영역을 말한다. buffer를 통해서 graphics pipeline으로 여러 data를 전달을 해준다. 이때 buffer가 device memory에 직접 메모리를 할당하는 것은 아니고, 우리가 직접해줘야 한다. (Vulkan이 이런 메모리 관리에서 자율성이 크다.) 그리고 당연히 buffer와 memory가 어떻게 연결이 되어있는지 여러 형식이 가능하고 그런 연결을 binding이라고 한다.
참고로 buffer vs binding의 개념도 헷갈릴때가 있는 것 같아 적어두려 한다. each buffer에 each binding이 있어야 하는 것 처럼 얘기를 했는데, 그러면 메모리 할당도 여러번해야하는 성능상 단점이 생긴다. 그렇게 하지 않고, 하나의 큰 버퍼를 쓰되, 그 버퍼에 영역을 구분하고 여러개의 binding을 두어서 graphics pipeline으로 전달하는 방식도 가능하다. 그리고 binding의 방식에 따라서 interleaved / separate 등의 방식이 있고 하드웨어나 알고리즘에 따라서 성능에 영향을 끼치기도 한다.
이미 우리는 buffer를 만들때, 메모리 요구사항을 확인하고, 메모리를 할당하고, bind 하는 것 까지 해봐서 이미지 만드는 것도 동일한 과정을 통해 가능하다. 차이점은 layout을 지정해주는 것인데, pipeline barrier라는 것을 써서 layout transition을 수행해줘야 한다.
Image layout transition
vulkan에서 image는 여러 sub-resource로 이루어져 있다 (여러 다른 영역들 mipmap 사용시 each level mipmap이 나눠진 것이 예시라고 한다.), 특정 시점에서 shader에서 읽거나 쓰거나 할텐데, 이 각 연산마다 최적의 layout이 다르다. 그걸 변경하기 위한게 image layout transition임. 그리고 이 transition이 언제(어떤 stage)에 이뤄져야하는지도 명시해줘야 함.Pipeline barrier
vulkan의 동기화에 대해서 먼저 이해해야한다.
Vulkan에서는 control 자율성을 우리에게 줘서 병렬로 CPU와 GPU 자원의 사용을 최대화 하려 한다. 이전세대 API들은 순차적으로 연산들을 실행했지만 vulkan에서는 multi threading을 위해서 명시적인 병렬형태를 취한다. 그래서 여러 병렬 작업들이 꼭 필요할때만 기다리도록 설정을 해줘야 idle time을 줄일 수 있으니 synchronization이 중요해진다.Synchronization w/i a Device Queue
vulkan에서는 command buffer를 queue에 넣어서 연산을 실행하는데, 이게 thread-friendly하다. 여러 cpu thread에서 하나의 GPU queue에 각자 여러 command buffer를 제출할 수 있다. Vulkan이 실행되는 도중에 병렬로 vertice나 texture loading 등의 작업을 진행해서 CPU 사용을 높일 수 있다.
queue에 넣은 command들은 넣은 순서대로 시작하는 것은 보장되지만, 병렬로 실행되기때문에 완료되는 순서는 보장할 수가 없다. 그래서 command를 기다리게하는 여러 방법이 있는데, pipeline barriers, events, subpass dependencies 등이 있다고 한다.Pipeline barriers
어떤 데이터나 어떤 스테이지가 기다리고 어떤 스테이지를 직전 command가 완료된 스테이지까지 막을지를 명시한다.
GPU-only여서 언제 pipeline barrier가 CPU에서 실행됐는지는 확인할 수 없고 signal back해줘야 알 수 있음. 두가지 타입이 있다.Execution barriers
이전 command가 언제까지 끝나야 하는지, 이 barrier가 끝나면 어떤 stage가 대기하고 있어야 하는지를 지정.Memory barriers
vulkan에서 L1/L2 caching할때 관련된 것인데, 한 코어가 memory에 쓰면 다른 코어에서 반영이 안될 수 있음 (L1 cache가 보통 core마다 있는 구조인 경우) 메모리 베리어가 cache가 flushed 되도록 명시해줘서 memory writes가 다음 command에서도 반영될 수 있게 해준다. 그리고 execution barriers에서는 stage가 logical한 것도 가능한데 (earlier, later) 이 access mask는 정확한 stage 지정을 해줘야 함.
https://vulkan-tutorial.com/Drawing_a_triangle/Graphics_pipeline_basics/Introduction 하나의 pipeline barrier에 execution barrier는 지정되어야 하고, memory barrier는 0~여러개 지정 가능하다. 타입도 세가지가 있는데, 나머지는 depth buffer 할때 다루고 우선은 image memory barrier만 설정하면 됨.
- Execution and Memory Dependency?

이미지 라이브러리는 STB를 사용한다.
texture image 생성은 command pool 생성이후에 해야하는 것을 명심하자. command recording을 초기에 한번만 해도 되는데, 지금 game engine tutorial 기반 project구조에서는 매 프레임 새로 recording해주고 있다.
참고로 tutorial 문서에서는 초기 한번의 recording이후 수정이 없고, Sascha William의 예제들은 초기 recording 후, window size 변경 등 필요시 recording을 다시해주고 있다.
파일에서 load후 텍셀 (texture pixel) 을 image에 저장은 buffer와 마찬가지로 staging buffer를 사용한다.
staging image도 있다고 하는데, vulkan에서는 buffer to image copy가 빠르기도 해서 staging buffer 방식을 권장한다고 한다. 이를 사용해서 host visible, host coherent 한 staging buffer의 mapped address (host)로 memcpy를 실행한다.
texture image를 생성한 후에는, copy buffer to image를 하기 전 후로 image layout transition을 실행해준다.
- 먼저 copy buffer to image를 하기전에는,
- execution barrier를 top -> transfer 로 지정,
- image memory barrier를 undefined -> transfer write로 지정해준다.
- layout은 undefined -> transfer dst optimal이다.
- 이 barrier에서는 직전 연산이 뭐든지 간에, 다음 copy command를 실행할 수 있도록 준비시키는 것이다.
- copy 이후에는,
- execution barrier를 transfer -> fragment shader로,
- image memory barrier를 transfer write -> shader read로 지정해준다.
- kayout은 transfer dst optimal -> shader read only optimal이다.
- copy 이후에는 아직 fragment shader에서 읽을 준비가 되지 않은 memory에 대해서 그 전까지 copy가 완료되도록 한다.
VK_PIPELINE_STAGE_TRANSFER_BIT 는 실제 stage가 아니고, transfer연산이 일어날때 pseudo-stage 라고 한다.
개념적으로 아직 잘 모르겠는 부분이 있는데, 다음 예제를 읽어보라고 권장하고 있어서 읽어보고 보충하겠다.
https://github.com/KhronosGroup/Vulkan-Docs/wiki/Synchronization-Examples
그리고 지금 예제 프로젝트에서는 single command recording을 여러번 하고 있는데, 효율성을 위해서 command buffer setup 실행후 필요한 모든 command를 녹화하고 flush를 통해 한번에 submit하는 것이 좋다고 한다. 추후 개선할 수 있는 포인트고, 이미 renerer에서는 begine frame후 bind draw등 command 를 recording하고 나서 end frame에서 한번에 submit 하고 있다.
Image View and Sampler
vulkan에서는 image를 직접 접근하는게 아니라, image view를 통해서 어떤 파트에 접근할건지 등을 설정한다. swap chain의 image 설정할때 이미 다룬 내용이다.
이미지를 사용하기 전에, fragment shader에서 interpolate된 texture coordinate(uv 좌표값)으로 먼저 uv좌표 값을 검증을 할 수 있다.
|
|
|
다음은 sampler 인데, 이전 세대 api들과 다르게, vulkan의 smapler를 texture image과 독립적인 개체이다. 그래서 image view에 대한 참조가 없고, over sampling과 under sampling 등의 문제 해결과 texel이 이미지 밖에 있는 경우 등에 대한 설정을 해줄 수 있다.
over sampling의 경우 texture image보다 더 촘촘한 uv coord 값이 주어졌을때 발생하는 문제다. 즉 화면에 보여지는 여러 pixel들이 texture 이미지의 하나의 texel로부터 얻어진 경우인데, 주로 확대해보면 그 현상이 크게 보인다. 이때 처리방식에 따라 가장 가까운 texel을 선택할 것인지, linear interpolation 된 값을 사용할 것인지를 sampler의 magnification filter에서 지정할 수 있다.
| magnification filter - nearest | magnification filter - linear |
|---|---|
|
|
|
텍스쳐 이미지를 추가한 후, Sampler 의 addressing mode를 mirrored repeat로 설정한 후, texture coordinate이 texture image의 범위를 초과하도록 임의 값을 곱해주면 다음과 같은 텍스쳐가 나온다.
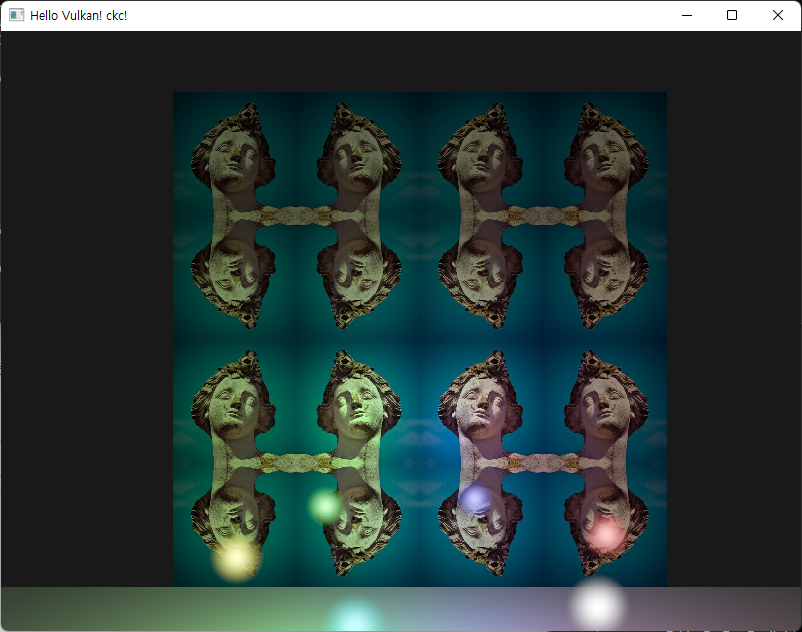
Combined Image Sampler
uniform buffer를 다루기 위해서 descriptor set 관련 개념을 한번 다뤘었다. 이번에는 Combined Image Sampler 타입의 descriptor를 만들어서 shader로 전달을 해줘야 한다. 한가지 variation으로 tutorial 문서에 추가해준 내용이 있는데, 여러 객체 마다 다른 model(texture 포함)을 가지고 있어서 global descriptor set으로는 이를 처리할 수 없다는 점이다.
이를 위해서 model의 member로 texture descriptor set을 두는 방법을 택했는데, 다른 선택지도 여러가지 있는 것 같다.
먼저 descriptor set에 대한 recap
- descriptor pool을 만든다 (descriptor의 타입과 pool size 를 명시)
- descriptor set layout을 만든다
- 어떤 자원과 연결되는지 binding에 대한 정보
- 이 layout은 pipeline을 생성할때 넘겨줘야 한다.
- layout과 descriptor pool을 사용해서, descriptor를 할당받아 set에 쓴다.
- 이때 몇번 set이 어떤 자원과 연결되는지 정보가 들어간다
- 이 과정은 writer를 통해서 진행
- 그 후 draw call 에 앞서서 bind descriptor set call을 통해서 자원을 변경해준다.
- 이 binding의 주기가 global / each object 등 다르게 해줄 수 있다는 장점이 있음
주의해야할 점으로 부적절한 size의 descriptor pool은 이후에 validation layer가 잡지 못하는 문제를 낳을 수 있다고 한다. vulkan에서 이 descriptor set 할당에 대한 책임을 driver로 넘긴것이라고 하는데, 안전하게 사용하길 권장하는 부분이라고 한다.
object 별 texture descriptor set을 두는 방법 이외에 다른 선택지로는 하나의 큰 uniform buffer에 모든 texture 를 bind해놓고, dynamic offset을 주는 방식이 있다.
최종 구현된 코드에서는 카메라 정보만 uniform buffer와 global descriptor set을 통해 사용되고, object 별 matrix는 push constants를 통해, texture image는 object 별 descriptor set을 통해 사용된다.
UBO는 shader에서 읽을때와 동시에 global descriptor set에 bind된 자원(camera matrix)을 변경하게 되면 race-condition의 문제가 생길 수 있어서 frame max-in-flight수와 동일하게 준 것이라고 한다. texture는 read only 이기에 object 수 만큼만 생성했다.
텍스쳐 이미지와 모델별 텍스쳐 descriptor를 추가해서 사과 모델을 추가했다. 주의할 점으로, obj foramt의 texture coordinate와 vulkan에서의 texture coord 차이가 있다. obj format애서는 0이 bottom이지만 vulkan에서는 top이므로 load시 이에 대한 변환을 해줘야 한다.
vertex.uv = {
attrib.texcoords[2 * index.texcoord_index + 0],
1.0f - attrib.texcoords[2 * index.texcoord_index + 1],
};

마무리
혼자 공부하다보면 끝났다는 개념이 없는 것 같다. 학교나 회사에서 프로젝트를 진행할 때는, 기한과 목적이 뚜렷하다보니 마무리가 딱 지어지는데 혼자 공부해놓고 가만히 두면 잊혀지기도 빨리 잊혀지고 한 파트를 끝냈다는 느낌이 잘 안든다.
사실 이런 위화감이 드는 이유는 개인으로서 특정 소속 없이 공부해본 적이 없기 때문이지 않을까? 학교에서는 시험을 보니까, 졸업을 하기위해서, 혹은 미래에 취업을 위해서 공부를 했던 것 같다. 그때는 공부하는 것들 하나하나가 너무 자연스러운 시기여서 그런지, 특별히 자기발전에 대해서 의식한 적이 없었다. 아니면 너무 빨리 돌아가는 학기 사이클에서 그럴 여유가 없었는지도 모르겠다. 일부는 흥미가 생겨서 들은 수업들도 있지만 아무래도 그런 것들은 자기 발전이나 유용성을 기대하고 공부하지는 않아서 그런지 자연스럽게 체득하는 느낌이었던 것 같다.
회사 다니면서 필요한 공부를 하는게 대학원에서 연구하면서보다 더 효율적이라는 얘기를 들은 적이 있었다. 공부와 연구가 다르다는 건 어느정도 인지하지만, 일 하면서도 마찬가지로 모르는 내용이나 새로 써야하는 기술들이 생겨 찾아보는 것들은 경험으로 쌓이는 느낌이라 뭔가 공부한다는 개념과는 달랐던 것 같다. 나야 연구를 해보지 않아서 나한텐 어떤 차이가 더 클지 비교하지는 못했다. 내가 재직중에는 구체적인 목적이 있는 만큼 목적이 달성되면 그 내용 자체를 내 개인을 위해서 기록해야겠다는 생각이 들지 않았던 것 같은데, 퇴사한 입장에서 생각해보니 내 살길? 은 내가 준비해놔야겠다라는 생각도 든다.
어쨌든 이렇게라도 간략히 정리해서 올려놓으면, 누가 이 글을 읽는지 여부와는 관계없이 확실히 기억에도 도움이 되고, 마무리를 짓는 느낌도 들어서 좋은 것 같다.