Vulkan Game Engine 영상에서 tutorial로 중간에 넘어오게 되면서, synchronization과 renderpass에서 가볍게 다루고 넘어간 내용들이 있어 구현에 헷갈리는 부분들이 있었다.
특히 pipeline barrier와 subpass dependency 관련 검색해본 내용들을 위주로 정리하고, 관련 자료들 link를 남겨놓으려 한다.
그리고 코드 구현에서 정확히 파악하고 있지 않은 부분들을 정리한 후, tutorial의 extra-chapter인 compute shader로 넘어가려 한다.
Synchronization
tutorial rendering and presentation
https://vulkan-tutorial.com/Drawing_a_triangle/Drawing/Rendering_and_presentation
먼저 tutorial의 위 챕터 내용을 정리해봤다.
outline of a frame
tutorial에서는 다음과 같이 frame에 관련된 task들을 요약 가능하다.
- 이전 frame이 끝나기까지 대기
- swapChain으로부터 image 얻기
- 이미지에 scene을 그리는 command buffer 녹화 (recording)
- 녹화된 command buffer 제출 (submit)
- swapChain image를 present
synchronization
vulkan의 핵심 철학 중 하나가 gpu의 실행 동기화가 명시적이라는 것이다. synch primitives를 사용해서 연산의 순서를 정의하는데, vulkan api 호출들은 GPU에서의 작업이 비동기적으로 이뤄지고 그 작업 끝나기 전에 함수가 먼저 반환되기 때문이다.
위의 작업들의 함수 호출은 실제로 끝나기 전에 반환되기 때문에 각 작업이 끝나고나서 실행되는 순서를 강제하기 위해서는 다음의 primitives를 잘 써야한다고 한다.
semaphore
command buffer를 제출하는 등의 queue 연산의 순서를 주고 싶을때 쓴다.
- graphics queue
- presentation queue
두 가지가 현재 쓰였고, semaphore는 binary, timeline 두가지 종류가 있지만 우선 binary 타입만 다룬다.
세마포어는 signaled or not 두 상태를 가지는데, 처음 시작은 unsignaled로 시작한다.
같은 semaphore S를 한 queue operation에 signal sema로 지정하고, 다른 queue op에 wait sema로 지정하는 형식으로 사용된다.
주의할 점으로, vkQueueSubmit() 호출은 바로 반환되고 실제 waiting은 GPU에서 발생한다는 것이다. CPU에서는 blocking 없이 계속 실행이 된다. CPU가 wait 하게 만드려면 다음의 Fence synch primitive를 사용해야 한다.
Fence
host(CPU)에서 GPU의 연산이 언제 끝났는지 알 필요가 있을때 쓴다.
fence도 signaled or not의 state를 가지는데, queue에 실행할 작업을 제출할때, 그 작업에 fence를 붙여 그 작업이 완료되면 fence가 signaled 되고 이후 host에서 특정 fence를 wait하는 방식으로 동작한다.
예시로, GPU에서 작업이 끝난 이미지를 CPU로 transfer한 후, file로 저장하고 싶을때 쓸 수 있다.
host를 block한다는 점이 semaphore와 차이점.
요약하면 semaphore는 GPU에서의 연산 실행 순서를 명시하고, fence는 CPU와 GPU가 서로 동기화 되도록 할 때 사용한다.
What to choose?
현재 tutorial 구현에서 적용되어야할 부분이 두 군데가 있다.
- swapchain operations
- 이전 frame이 끝나기 기다리기.
swapchain 관련 연산들은 GPU에서 일어나기때문에 semaphore를 쓰면 된다.
현재 구조에서는 매 frame 마다 command buffer를 re-recording 하고 있는데, *(미리 recording 해놓은 command buffer를 재사용 하는 방식도 가능하지만) 여기서는 recording을 Host에서 할 때, GPU에서 아직 실행되고 있는 command buffer에 overwrite하고 싶지 않기에 fence를 쓴다.
creating synchronization objects
- 이미지가 swapchain으로부터 얻어지고, 렌더링 준비가 완료되었다는 signal을 위한 semaphore
- 렌더링이 완료되어서 presentation이 가능하다는 semaphore
- 그리고 동시에 하나의 frame만 렌더링 되고 있도록 하는 fence
총 2개의 semaphore와 1개의 fence가 필요한데, 이전 LVE 구조에서는 fence를 한 종류 더 총 2개 종류를 쓰고 있었다. 이 부분에 대한 수정 history는 아래의 fix 에서 좀 더 자세히 다루려 한다.
각 primitive들은 MAX_FRAMES_IN_FLIGHT 별로 하나씩 필요하다.
이전 프레임 기다리기
처음 acquireNextImate() 에서 이 fence를 기다린 후 vkAcquireNextImageKHR() 를 호출한다. 이때 초기 설정은 signaled 되어 있도록 한다.
imageAvailableSemaphore 는 이미지를 얻어오는 작업이 끝나면 signaled 되도록 인자로 지정해준다.
command buffer 녹화
vkResetCommandBuffer() 관련해서 차이점이 있는데, 이는 tutorial 구현과 다르게, command pool 생성시 VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT 사용 여부와 관련이 있다.
https://registry.khronos.org/vulkan/specs/1.3-extensions/man/html/VkCommandPoolCreateFlagBits.html
command buffer 제출
submitInfo 관련
- 어떤 semaphore를 사용해서 wait할지
imageAvailableSemaphore- draw등 제출한 command들은 그 swapchain에서 이미지를 얻어오는 것이 완료된 이후에 그 이미지에 write을 하고 싶다.
- 어떤 pipeline stage에서 기다릴지
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT- 최적화와 관련된 부분인데, graphics pipeline stages에서 이미지가 사용가능한 상태가 아니더라도, color attachment output stage 이전까지는 gpu에서 실행이 되도록 하고 싶다는 뜻이다.
- 이 제출한 command들이 완료되면 signal을 보낼 semaphore가 있는지?
renderFinishedSemaphore- 이 semaphore를 사용해서 렌더링이 끝난 이미지를 present하도록 설정해준다.
subpass dependency
renderPass에 있는 subpass에서는 이미지의 layout transition을 명시하지 않아도 고려한다. 이 transition은 subpass들간의 memory & execution dependency를 명시한다.
기본 built-in dependencies는 render pass의 시작과 끝에서의 transition에 관한 것인데, 시작 부분에서는 이미지를 아직 얻어오지 않을 수 있는 문제가 있다.
vkCmdBeginRenderPass()를 가장 먼저 recording 하는데, 그 시점에서 built-in dependency에 의한 image layout transition이 일어나기에는 문제가 있다는 뜻으로 이해함.
두가지 해결법이 있는데,
- draw command 를 제출할 때,
imageAvailableSemaphore의 waitStages를VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT로 주어서, render pass가 이미지가 가용해진 이후에 시작하도록 하거나 (최적화 관련 단점이 될 듯?)- subpass dependency를 명시해서
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT로 지정하는 방법.
- subpass dependency를 external -> 0 명시해서 직전 subpass 지정
- srcStageMask를
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT로 지정, dstStageNask를VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT로 지정.- srcAccessMask를 0, dstAccessMask를
VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT로 지정- 직전 subpass의 color output stage와 현재 subpass의 color output stage 사이에서 any -> color write 로의 layout transition이 이뤄지도록 지정해줌.
- 사실 이 부분 관련해서 여러 설명을 검색해봤는데, 잘 이해가 안됐다. 아래의 질답에서 추가할텐데, spec 문서의 first, second synchronization scope를 그대로 이해하는게 가장 정확한 설명인 것 같아 정리해놓으려 한다.
presentation
graphics queue submit이 끝난 후, renderFinishedSemaphore 를 wait로 주어서 vkQueuePresentKHR() 를 호출한다.
graphics queue submit에서 signal sema로 지정해놓았기 때문에, rendering이 끝날때까지 기다렸다가 presentation engine으로 요청을 하게 한다.
Q. subpass dependency vs. semaphore
Q. subpass dependency와 semaphore의 설정이 각각 필요한 이유가 뭔지? 서로 중복되는 내용은 아닌지?
https://stackoverflow.com/questions/59693320/use-of-vksubpassdependency-vs-semaphoreA. semaphore에서 지정해주는
pWaitDstStageMask는 같이 제출한 command 실행하기 전까지 기다릴 어떤 pipeline stage를 명시하는 것이고,vkAcquireNextImageKHR()에서 주는 image index는 queue 연산이 아니기 때문에 presentation engine에서 그 이미지의 사용이 끝났는지 알수가 없기 때문에 필요했던 것임.반대로 subpass dependency는 layout transition이 언제 일어날지에 대한걸 지정해주기 때문에 필요함. 지정하지 않으면 아무때나 알아서 일어날텐데, presentation engine에서 아직 이미지를 읽고 있는데 layout을 바꾸버리는 상황이 발생 가능함. (지정하지 않은
srcStageMask는VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT가 default.)이걸 막기위해,
pWaitDstStageMask를 top of pipe (all commands) 로 주면, vertex processing등도 하지 않고 모든 것을 기다린 다음 시작하니까 layout 변경이 없어도 되긴함. 근데 optimal 하지 않을 수 있음.그래서 우리가 하려는 방식은 layout transition의
srcStageMask를VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT로 지정해서 이 이후에 write로 변경을 하는 방식. 이전 render pass의 commands들이 이 color att output stage에 도달한 이후에 layout transition이 일어나도록 강제하는 것인데, 이 시점은 sema wait가 끝난 시점이므로, presentation engine이 그 이미지 사용을 끝냈고, image layout을 변경해도 괜찮게 됨.
여기서 헷갈렸던 부분은, swap chain 이미지가 여러개 있는 상황에서는 이전 render pass에서 presentation engine이 image를 사용하고 있더라도 이번 render pass에서는 layout transition을 해도 문제가 없지 않냐는 의문이었는데, 이 swap chain 이미지의 수와는 독립적으로 (최악의 경우 1개인 상황에서도) 실행에 문제가 없도록 보장하기 위한 내용이라고 이해하고 넘어갔다.
이 시점에서 헷갈렸던 것이, 어떤 개념이 (commands, pipeline, render pass, subpass)이 실행 (execution)과 관련이 이떻게 있는지에 대한 큰 그림이었다.
해당 내용을 찾아보다가 언급된 아래의 CG at TU wien Series영상을 보고 이런 큰 흐름을 이해하는데 도움이 되었다.
CG at TU wien ep7
https://www.youtube.com/playlist?list=PLmIqTlJ6KsE1Jx5HV4sd2jOe3V1KMHHgn
이 series 내용들을 통해 명확히 이해하지 않고 넘어갔던 개념들을 한 번 크게 볼 수 있었다. animation과 적절한 이미지가 곳곳에 등장해서 글로 정리할수 있는 부분은 많지 않은 것 같다. 마지막 내용인 synch 관련 내용만 정리해놓으려 한다.
recap
commands
- state type
- bind, set, pushConstants 등
- action type
- device에 특정 작업을 실행하는 명령들
- draw, transfer, dispatch, ray-tracing 관련
- synchronization type
- 실행이나 리소스 접근의 synchronization
- pipeline barrier, waitEvent, begin renderPass 등
- 예를 들어 fragment shader stage에서 draw call이 실행되기 전에, copy commands가 먼저 완료되도록 기다리는 것 등
pipeline stages
- graphics
- draw processing
- vertex processing
- tesselation
- primitive processing
- rasterization
- fragment processing
- pixel processing
- api나 용어 차이가 조금 있을 수 있겠지만 큰 개념들은 graphics 전반에 적용됨.
- 처음에 LVE에서 다룰땐 다음처럼 핵심만 간단히 다뤘었음.
- inpute assembles => vertex shader => rasterization =>fragment shader => color blending
- programmable한 vertex/fragment shader stage에 shader language로 compile된 코드를 업로드해서 GPU에서 실행.
- compute
- draw processing
- compute shader
- ray tracing
- 위 두개와 다르게 분기와 cycle이 있는 directed graph형태의 stage
- acceleration structure traversal만 fixed function step이고 나머지는 configurable 하다고 함
recording
command buffer에 여러 vkCmd가 recording 되고 (descriptor set binding 등도 포함)
- 이 command buffer들을 여러개로 한번에 묶어서 submitInfo에 담아 queue에 제출.
- single Time Command 등을 따로 구현해서 하나만 제출하고 바로 그 실행이 끝나기를 wait 하기도 함.
- 하나의 command buffer에 여러 bind, draw, 등의 command를 호출해서 한번에 제출하는 형태의 구현을 써왔음
- 여러개의 command buffer를 한번에 제출도 가능한데 그걸 batch라는 개념으로 쓰는 것 같음.
- 영상에서는 recording 된 cmd들 사이의 순서를 강제하기 위한 신호등의 개념으로 synch를 설명한다.
synchromization primitives의 간단한 설명들.
pipeline barrier
- command buffer와 같이 recording 된다.
vkCmdPipelineBarrier() - command 들의 내부 순서 뿐 아니라, 같은 queue에 이전에 제출된 command와 이후에 제출된 command 사이의 순서에도 사용된다. 그래서 command buffer의 경계가 pipeline barrier 입장에서는 중요치 않다.
- 제출 순서 submission order가 중요한 개념이고, 반대로 semaphore 나 fence 에서는 이 command buffer boundary가 중요하다.
fence와 semaphore
- signaled state가 될때까지 wait하는 목적으로 사용됨
- semaphore는 device(GPU)에서 wait과정이 일어나지만
- fence의 wait는 host(CPU)에서 일어남
wait idle operation
queue나 device의 작업이 끝나서 idle 상태가 될때까지 기다리는 연산.
vkQueueWaitIdlevkDeviceWaitIdle
host side에서 device의 작업이 끝나고 idle 되기를 기다림.
fences
먼저 sychronization scope 개념이 필요하다. 아직 이 문서를 세세히 읽어보지 않았는데, 가장 정확하게 개념을 이해할 수 있는 방식인 것 같다. 추후 필요한 내용을 추가해서 정리해야겠다.
https://registry.khronos.org/vulkan/specs/1.3-extensions/html/vkspec.html#synchronization-dependencies-scopes
synchronization scopes 개념.
- 동기화 명령이 실행 의존을 만들수 있는 다른 명령들의 범위
- first scope와 second scope가 있다.
- 실행 의존. execution dependency는 두 set of operations *(first, second scope)에서 first scope must happen-before the second scope의 실행 순서를 강제하는 개념.
fence 에서의 first, second scope.
- fence에서는 first scope에 해당하는 명령들이, 같이 제출한 batch에 포함된 명령들과 그 이전에 제출된 모든 명령을 포함하고, second scope에는 fence signal operation만 포함한다.
- fence와 함께 제출된 command 들의 실행이 완료되면 fence가 signaled 된다고 이해하면 된다.
semaphores
queue 간의 synch를 맞추기 위한 것이라 보면 됨.
- binary semaphore
- 원래 이 타입 밖에 없었어서, 이것만 지원하는 연산들이 있다고 함.
- device-device 간의 signal만 가능
- swap cahin 다룰때 쓰이는 예시가 대표적
- presentation queue - graphics - queue
- swapchain 예시에서 presentation engine은 abstraction을 통해 어떤 device (gpu1 or gpu2)가 실제도 acquire image와 present에서 사용되는지 구분하지 않는다고 함.
- synchronization2 의 기능들을 쓰면 더 효율적이라고 함.
- timeline semaphore
- 상대적으로 새로 추가된 기능
- integer payload가 있어서, 증가시키는 형태로 사용됨. (이 값이 1일 필요는 없어서, actual milliseconds past등의 의미있는 값을 쓸 수 있다고 함.)
- host-device간의 소통이 가능해진게 특징.
- compute 관련 예씨
- physics queue와 graphics queue간의 synch 문제
- physics에서 dispatch command로 physics simulation 계산을 한다고 하자.
- physic frame과 graphics frame 수가 같으면 문제가 없다.
- 근데 physics frame은 60hz고, graphics는 가능한 많이 같이 다른 경우라고 가정해보자.
- draw call이 더 적은 경우, draw call이 더 많은 경우를 나눠서 발생가능한 문제들을 설명해줌(영상 참고)
- 이런 상황에 timeline semaphore로 편하게 원하는 기능을 구현할 수 있다고 함.
pipeline barriers
within a queue에관한 synchronization
queue에 제출한 command 들이 시작하는 순서는 지켜지지만, 끝나는 순서는 out of order이므로 이 순서를 control 하기 위한 기능이다.
- execution
- 각 command가 pipeline stage를 거쳐서 실행되는데, execution barrier를 지정해주면 더 효율적인 최적화가 가능하다. stage를 지정해주지 않으면 all commands에 대해서 동작한다.
- first synch scope에 해당하는 것은 submission order가 이른 commands중 src stage mask에 의해 지정된 pipeline stage에서의 연산들이다.
- second synch scope에 해당하는 것은 submission order가 늦은 commands 중 dst stage mask에 의해 지정된 pipeline stage에서의 연산들이다.
- 영상에서 예시 상황을 묘사해줌
- memory
- 한 자원에 write해놓고, 이후에 read하고 싶은 상황에서 실행 의존만으로 충분하지 않다. 메모리 구조 (캐시)와 관련된 내용인데, 이를 컨트롤 하기 위한 memory dependency 개념이 필요함
- access scope 개념이 추가된다.
- 자원을 read할때 process 시작전에 cache에 들어있는지 확인을 하고, 비슷하게 written back to the resource도 다른 연산 시작전에 확인한다.
memory availability and visibility
이 부분은 specification 문서와 함께, 다음 글이 도움이 됐다. https://themaister.net/blog/2019/08/14/yet-another-blog-explaining-vulkan-synchronization/
write operation의 state라고 볼 수 있다.
- available
- gpu의 L2 cache로 load된 상태
- visible
- L1 cache 로 load된 상태
- availablility에 pipeline stage와 access mask가 합쳐진 개념이라고 함.
- 한 shader stage에서 메모리에 write를 하고 나면, L2 cache는 더이상 up-to-date 하지 않게 되므로, available하지 않은 상태가된다.
- 그래서 write 이후에는, 그 데이터가 미래에 visible 해지기 위해 먼저 available 해져야 한다.
- making memory available : about flushing caches
- making memory visible : invalidating caches
메모리 의존을 availability operation과 visibility operation을 포함한 실행 의존으로 볼 수도 있는데, 다음과 같다.
- 1번 연산 set이 availability operation 이전에 일어난다.
- availability operation이 visibility opertion 이전에 일어난다.
- visibility operation이 2번 연산 set 이전에 일어난다.
pipeline barrier에서 일어나는 4가지 순서를 좀 더 설명하면
- src stage mask가 끝나기를 기다린다
- src stage mask와 src access mask조합 에서 일어난 writes 들을 available하게 만든다.
- available 해진 memory를 다음 dst stage mask와 dst access masmk 조합에 visible 하도록 만든다.
- dst stage mask의 작업을 unblock 한다.
TOP_OF_PIPE / BOTTOM_OF_PIPE
- 이 가상의 stage를 쓸일들이 있는데, 이는 execution barrier를 위한 것이지 memory barrier와는 무관하다.
- 이 단계들은 없는 실제로 없는 단계라 아무런 메모리 접근이 일어나지 않는다. 따라서 access mask는 0으로 지정해줘야한다.
- TOP_OF_PIPE 예시
- 이미지를 할당한 직후, layout transition을 하고 싶고, 아무것도 기다릴 게 없을때.
- flush out 될 writes가 없다. vulkan에서 새로 할당된 메모리는 항상 모든 stage와 access type에서 available and visible.
- src stage mask로 쓰였을 때, 아무것도 기다리지 않는다는 뜻이 된다.
- BOTTOM_OF_PIPE 예시
- swapchain이미지를 presentation engine에 넘기기 직전.
-
VK_IMAGE_LAYOUT_PRESENT_SRC_KHR로 transition이 필요하다. (우리는 render pass 생성할 때 지정해놨다.) - 이 transition 이후에는 메모리를 visible하게 만들 stage가 없다.
- dst stage mask로 쓰였을 때, last stage를 block 시키겠다는 뜻으로, 이 barrier 이후의 기다려줘야 될 작업이 없다는 뜻이 된다.
renderPass subpass dependencies
image memory barrier와 크게 다를게 없다고 함. 대상이 특정 image memory가 아니고 attachment임.
render pass는 frame buffer의 attachments들이 어떻게 쓰일지를 describe.
그리고 여러 subpass들 사이의 synchronization을 describe.
subpass dependecies는 해당 render pass 내부의 subpass 들 간의 internal과, 전/후 render pass와의 external synchronization이 가능.
events
- split barrier
- set event 이전의 commands들이 wait event 이후의 commands들과 synchronized 되는 것.
- 그 사이의 commands 들은 영향을 받지 않는다고 함.
- host communition이 가능하다는 특징
- 아직 사용할 일이 없어서 자세히 보지 않았음.
fix
기존 LVE 코드 구조와 vulkan-tutorial.com 에서의 코드 구조 차이가 있는 부분들이 있어서 여기서 수정하고 넘어갔다. 아마 기본 구조는 같은데, vulkan-tutorial.com의 repo history를 보니, 여러 PR들이 합쳐지면서 수정된 내용이 LVE 코드에 대응되는 비슷한 부분과 차이가 벌어졌던 것으로 보인다.
frames in flight
double-buffering 등의 개념은 LVE에서도 swapchain등을 다룰때 presentation mode등을 다루면서 한번 다뤘다. 기본적인 원리는, 다음의 세 단계에서 사용하는 자원들을 duplicate해서 동시에 실행하려는 목적이다.
- command buffer recording and data upload
- GPU 실행
- presentation to monitor
그래서 command buffer등을 2개로 나누면, 하나는 CPU에서 recording에 사용하고, 다른 하나는 GPU에서 실행하려는 개념인데, CPU에서 동시에 작업을 할 필요가 없는 자원은 이렇게 in-fight 수 만큼 나눌 필요가 없다.
single depth buffer
tutorial에 따른 depth buffer도 공통의 자원이므로 하나만 사용을 하는데, 이 stackoverflow 글에 의하면 하나의 depth buffer를 사용하면 첫 frame에서의 depth buffer가 fragment shader stage에서 사용되는 중에 그 다음 frame의 fragment shader stage에서도 동시에 사용을 하는 문제가 있어 추가적인 barrier가 필요하다고 한다. (swapchain image가 하나라면 발생하지 않을 문제)
그래서 코드 구현에서는 depth buffer도 frames-in-flight 수만큼 따로 생성해서 사용하는 구조로 유지하기로 결정했다.
frame buffer and swapchain image
https://www.reddit.com/r/vulkan/comments/jtuhmu/synchronizing_frames_in_flight/
먼저 swapchain 이미지에 대해서 정리해보면, vulkan에서 window와 화면에 대한 것을 직접 다룰수 없어서 추상화된 개념인 surface를 이용하는 것처럼, device가 지원하는 swapchain 이미지 수 등도 surface capability query를 통해 미리 받아온다.
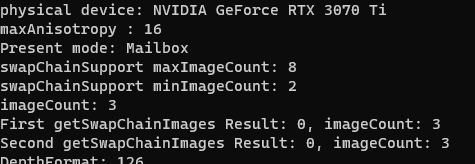
정리하면, swapchain 이미지의 수는 device나 driver의 api 구현에 따라서 suuport 하는 수가 달라 질 수 있고, frames-in-flight 수는 내가 구현할 present 정책에 따라 정할 수 있는 값이다.
위 글에서는 이 두 값이 다를때 발생할 수 있는 문제 시나리오 상황에 대한 묘사가 나와있다. 그리고 이 문제는 tutorial code의 command recording 방식과 관련있었는데, 다음 부분에서 정리하겠다.
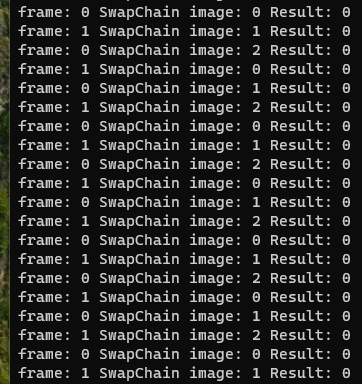
swapchain image index와 frame index를 출력해봤는데, 꼭 swapchain image index가 위처럼 순차적으로 얻어진다는 보장은 할 수 없다고 이해했다.
additional fence
https://github.com/Overv/VulkanTutorial/issues/226
여기 제시된 문제점이 위 글과 같은 내용으로 이해했는데, 결국 imagesInFlight라는 fence를 추가적으로 사용했던 코드가 여러 문제의 원인이 된다.
이 fence를 사용한 이유는 tutorial code의 과거 구현 구조가, command buffer를 매 frame 마다 새로 recording 하는 것이 아니라 처음에 한번 recording 한 후 재사용하는 구조여서 그렇다.
문제 상황은 frames-in-flight 수가 swapchain image 수보다 많거나, 혹은 swapchain image를 acquire 했을때 out of order로 나오는 상황 등으로 인해 index가 꼬이면서 생기는 경우이다.
이런 문제를 막기 위해서 image index 각각을 frame index로 다시 mapping해서 (recently used) 그 mapped 된 frame의 fence를 additional fence로 추가해주는 구조로 이해했다. 결국 이런 fence의 사용이 비효율을 발생시키는 문제가 제기됐고, 수정 된 것으로 보인다.
https://github.com/Overv/VulkanTutorial/pull/255
수정 된 내용을 보면 buffer와 descriptor, command buffer등이 swapchain image count가아니라, MAX_IMAGES_IN_FLIGHT 수 만큼 duplicate 되도록 수정되었는데, 그러면서 imagesInFlight의 fence가 자연스럽게 필요 없어졌다. LVE의 code에는 이런 변경이 일부만 반영되어 있었다고 보면 될 것 같고, 수정된 내용에 맞게 fence를 제거해주었다.
RenderPass
렌더패스에서 위의 framebuffer를 생성하기 전에 frame buffer의 foramt과 구조 사용할 attachment format과 종류등을 미리 지정해주는 청사진 역할을 한다고 보면 된다.
FrameBuffer
그래픽스 파이프라인의 결과가 저장될 리소스다.
대부분 attachment의 형태로 렌더링 결과가 저장된다.
Vulkan에서 frame buffer와 swapchain image의 관계에 대한 질문글을 봤다.
-
VkFramebuffer와VkRenderPass가 render target을 정의한다. - renderPass가 어떤 attachment가 어떻게 사용될지를 정의한다.
-
VkFramebuffer의 attachment와 어떤VkImageView가 연결될지 정의한다. -
VkImageView는VkImage의 어떤 파트를 사용할지를 정의한다. -
VkImage는 어떤VkDeviceMemory가 사용되고, 어떤 format을 사용할지 등을 정의한다.
정리하면, swapChain image는 그냥 image의 한 종류인데, driver가 그 image를 소유할 뿐이다. 그래서 이걸 할당하거나 파괴할 수거 앖고, acquire를 통해서 presentation 전에 변경을 해놓을 뿐이라고 한다.
swapChain image는 buffering이나 다른 advanced rendering을 통해 여러개가 있을수도 있고, 보통 image 개수마다 분리된 frame buffer를 두는게 일반적인 경우라고 한다.
RenderPass
크게 세가지로 구성되는데,
- attachments
- 렌더링 과정에서 사용할 이미지에 대한 정보이고, shader input이나 render target(color) 등을 명시한다.
- subpass
- 렌더링 명령들의 step이라고 보면 된다.
- 최적화가 중요한 모바일 GPU에서 유용한 개념이라고 한다.
- subpass dependency
- 1개 이상의 subpass에서 그 subpass 들 간의 memory barrier 역할을 수행한다.
- renderpass 외부와의 dependency도 external을 통해 가능한데, implicit external subpass dependency도 있다. 이는 driver에 의해 기본으로 넣어지는
vkCmdPipelineBarrier라고 이해하면 된다.
마무리
해당 주제들을 공부하면서 찾아본 내용들을 덕지덕지 링크로 걸어놨는데, 아직 다 이해하지 못한 내용들이 많다.
그리고 검색해서 나온 내용들에는 잘못된 내용이나 질문글 같은 경우의 답변에는 신뢰도 문제도 있어서 주먹구구식으로 모를때 하나씩 검색하는 방식의 학습에 한계를 느꼈다.
Specification 문서를 보는게 정확한 내용을 습득하는 방법이겠지만 읽기 딱딱하기도 하고 효율성의 문제도 있다. 그럴때 잘 정리된 강좌를 순차적으로 보는게 도움이 많이 됐다.
직접 사용해서 만들어보면 전체 구조를 이해하는데 도움이 되기는하는데, 제대로 만든 것인지 검증하기가 애매하다는 문제가 있었다. (debugging tool로 RenderDoc 이라는 도구를 많이들 쓰는 것 같은데, 이후 검증이 필요할때 한번 사용법을 익히면 좋을 것 같다.)
아래 예시는 검증된 내용의 synchronization example 들이라서 비슷한 내용을 구현할 일이 생기면 참고할 용으로 남겨놨다.
https://github.com/KhronosGroup/Vulkan-Docs/wiki/Synchronization-Examples#transfer-dependencies