Theory
ECS 란 한마디로 data-oriented framework라고 할 수 있다. Vulkan API 공부를 하다가 알게됐는데, 예전에 Unity에서도 다뤄봤던 개념이었다.
그때는 뭔지 모르고 단순히 구조를 따라가서 사용하기만 했었는데 왜 이런 구조를 사용하는지 알게되니 꽤 재미있는 내용이란 생각이 들었다.
관련해서 간단하지만 원리를 잘 설명해주는 블로그 글을 보게 됐는데, 그 practice를 직접 따라 해보는 과정을 남기려고 한다.
- https://austinmorlan.com/posts/entity_component_system/
- 원본에 상세한 설명이 있으니 인상적인 내용만 요약/정리 해놓으려 한다.
ECS란?
전통적으로 게임개발에서 OOP(Object Oriented Programming)의 패러다임으로 접근을 많이 했다고 한다. 예를 들어
actor ─┬─ human ─── shop-keeper
└─ monster ─── goblin
과 같이 class와 상속 관계를 정의하고 각 object의 instance에서 .render()를 호출하는 방식의 OOP구현이 있다고 해보자.
여기에는 두가지 문제가 있다고 한다.
- 문제점
- 유연성
- 만약에 고블린이 인간과 친해져서 경비원을 하고 싶다고 해보자. 상속 관계가 복잡해지는 문제가 있다.
- cache 사용성
- 예를들어 물리 시스템에서 각 객체가 좌표, 속도, 가속도의 데이터를 가진다고 가정해보자.
- 각 객체가 모든 데이터를 다 포함하고 있는 OOP 구조에서는 객체1의 좌표에 접근할때 cache line을 따라서 객체1의 속도나 가속도 데이터의 접근에 캐시 사용의 이득을 볼 수 있을 것이다. 그러나 다른 객체들 (객체2~1000)의 정보들에는 이런 이득을 보지 못하게 된다면 캐시 사용을 충분히 하지 못하게 된다.
- 이 문제가 과거에 메인 메모리에서 cpu 로 데이터를 불러들이는 과정이 오래걸리던 시대에는 bottle-neck이었다고 한다. 현대에도 이처럼 게임 구현의 디자인 차원에서 cpu optimization을 고려해야할 만큼 중요도가 높은지에 대해서는 논란의 여지가 있는 것 같으나, 이미 많은 게임엔진 등에서 사용되는 기법이고 장단점을 알고 가는 것에서 의미를 두기로 했다.
- 유연성
- 해결
- component 기반 접근
- Unity에서 사용하는 방법이기도 하다.
- object에 여러 component를 추가/제거하기가 용이하다.
- pack tightly
- component들을 POD(Plain Old Data)로 정의한다.
- 그리고 여러 객체를 iterate할때, 필요한 component를 가지고 있는 객체들만 돌면, 필요한 데이터만 cache로 불러들여서 locality를 충분히 활용할 수 있게 된다.
- component 기반 접근
- 요약
- Entity란 그냥 단순한 ID다.
- Component는 특정 객체가 가질 특성들만 모아놓은 것이다. (Transform, RigidBody, Gravity, Renderable 등등). Entity가 각 특성의 struct에 index로 사용된다.
- System은 이 component들에 작동하는 로직이다.
이외의 구현 디테일은 원본 글에 자세히 설명되어 있다.
cache 개념 Recap
학생때 Computer Architecture 수업을 들었는데, 별로 흥미를 못느꼈던 기억이 있다. 교수님이 굉장히 로봇같이 수업 진도를 나가주셨던 기억과 과제로 verilog를 사용해서 CPU 기능들을 구현했던 것이 기억이나는데, 이왕 건드린 김에 복습 겸 정리를 해놓으려 한다.
캐시 계층
캐시는 단순하게 말해서 메인메모리(DRAM)의 데이터 접근이 느리기 때문에, 자주 쓰이는 값을 미리 빠른 장치에 저장해 놓는 메모리다. 이런 메모리 구조는 따지고 보면 컴퓨터의 모든 메모리 계층 구조에 쓰이는 원리인데, 빠른 접근을 할 수 있는 메모리는 그 용량이 작다 (그리고 비싸다.) 대략 레지스터-캐시-메인메모리-하드디스크(혹은 SSD) 같은 구조이고, 캐시 역시 계층을 두어 L1, L2, L3 캐시를 둔다. Hit와 Miss 두 상황에 대해서, hit이면 해당 계층에서 바로 데이터를 가져와서 쓸 수 있는 것이고, Miss인 경우 다음 계층의 메모리를 참조하게 되는 계층적 구조이다.
캐시의 종류
제일 먼저 Direct-mapped cache를 설명해보겠다. 메인 메모리가 M=2^m bytes, 캐시를 C=2^c bytes라고 해보자. 보통 접근하는 데이터 크기가 4, 8 byte 등으로 묶여져 있으니 G=2^g로 granularity를 두자.
그럼 m-bit 의 메모리 주소값을 3 부분으로 나누자. t / c-g / g. 즉 t = m-c이다. 이 중 c-g를 cache의 index로 사용하고, t는 tag bank에 저장하여 중복될 수 밖에 없는 다른 주소들에 대해 확인할 때 쓰인다. 여기에 valid bit까지 필요하니까 t+1 bits에 대한 저장공간에 추가로 들게 된다. 이를 줄이기 위해서 여러 G-bytes를 묶어서 하나의 block으로 다루면(offset을 확인할 bit도 생각해야함.), Direct-Mapped cache의 형태가 된다. block size B=2^b bytes라고 하면, m-bit는 t/c-b/b/g로 구성되고, C/B개의 t bits로 이루어진 태그 뱅크, 1bit Valid, C/B개의 B bytes로 이루어진 데이터 뱅크가 캐시의 구조가 된다.
이때 tag + valid + data를 합친 하나의 bank가 cache를 이루게 되는데, 이 bank를 여러개 (a개) 두면 a-way set-associative cache가 된다. 하나의 cache index에 대해서 a개의 중복된 뱅크를 두어 conflict를 줄이는 방식이다. a개의 bank의 tag bank는 각각 C/B/a개의 t bits로 이뤄졌다.
즉 associativity란, 메인메모리의 특정 entry(주소) 가 cache의 어떤 부분으로 mapping 될지에 대한 정책인데, 아무데나 갈수 있으면 fully associative, 위치가 정해져 있으면 direct-mapped, a-군데로 갈 수 있으면 a-way set associative라고 한다. 여기에 최대로 가능한 a는 몇일까? C/B이다. 즉 모든 index에 entry가 저장될 수 있고 탐색해야 하는 상황이다. 이런 형태를 fully-associative라고 한다.
trade-off는 check해야할 bank가 많아질수록 더 많은 power와 chip area가 필요하고 latency가 증가하게 된다.
miss의 종류
- cold
- 처음 불러올때 필연적으로 발생하는 miss다.
- B가 design factor이고 데이터 locality와 관련이 있다.
- capacity
- 그냥 cache의 용량이 작아서 발생할 수 밖에 없는 miss. C와 관련있다.
- conflict
- a와 관련있고, set의 way가 부족할 때 발생한다. fully-associated cache에소는 발생하지 않았을 miss라면 여기에 해당한다.
- coherence
- 멀티코어에서 상위 캐시를 코어마다 가지고 하위 캐시는 공유하는 구조에서 발생가능한 문제.
캐시에 Write
캐시에 접근한다는 것은 read/write 두가지가 있다. 이 중 write의 경우는 데이터를 변경하는 것이기 때문에 계층구조와 일관성 등을 고려해야해서 여러 정책을 나눌 수 있다.
- hit 인 경우
- write-through
- L1에 hit인 경우 L2도 업데이트 해주는 방식.
- write-back
- L1만 업데이트 하고 dirty로 표시해놓고 나중에 하위 계층에 업데이트 해주는 방식.
- write-through
- miss
- write-alloc
- L1에서 write miss인 경우 그 block을 L1에 할당해주는 방식.
- write-no-alloc
- L1에서 write miss인 경우 L1할당은 안하고 하위 계층에만 그 block을 할당하는 방식. 할당은 read-miss일때만 일어남.
- write-alloc
- 주로 쓰는 조합
- wb & wa
- locality가 큰 경우 이점을 볼 수 있음
- wt & wna
- 같은 entry에 연속 write할때 이점이 딱히 없음.
- wb & wa
Instruction and Data
- Harvard architecture
- instruction과 data를 별도의 starage로 두는 구조
- Princeton architecture
- 폰노이만의 unified 구조
L1 cache를 split하면 free doubled bandwidth 효과를 볼 수 있어서 주로 L1 캐시를 split으로 쓰고 L2, L3를 unified로 씀.
Practice
이제 위의 ECS에 cache 개념을 가지고 실습 프로젝트를 하나 만드는 과정을 적어보겠다.
https://github.com/keechang-choi/ECS-practice.
코드는 원본(https://austinmorlan.com/posts/entity_component_system/) 기반이지만, 변수타입, 라이브러리, 추가 component 등 크지 않은 부분의 variation이 있다.
step-0
시작점에 필요한 두가지 내용을 추가한다.
- add window
- add cmake build system
이전에 동시에 환경 세팅이 필요한데, 참고한 내용들이다.
- opengl update
glxinfo | grep "OpenGL version"sudo apt update & sudo apt upgrade -y- wsl 관련 https://github.com/microsoft/WSL/discussions/6154
- openGL 버전에 다른 GLAD 설치 후 third-party에 추가. https://glad.dav1d.de/
- glfw 설치.
- mesa 관련
sudo apt-get upgrade mesa-common-dev libgl1-mesa-dev libglu1-mesa-dev-
export LIBGL_ALWAYS_INDIRECT=0 export MESA_GL_VERSION_OVERRIDE=4.5 export MESA_GLSL_VERSION_OVERRIDE=450 export LIBGL_ALWAYS_SOFTWARE=1
step-1
rendering system을 구현한다. 이를 위해 간단한 ECS구조를 완성한다.
- system은 entity (ID)의 set을 가지고 있다.
- 개별 entity에 component를 지정해주면, signature를 변경시키고 그에 적용되는 system도 이를 tracking 한다.
- render system은 camera entity에대해 접근해야 한다. camera entity는 camera component를 지닌 개체이고 trasform component도 지니고 있어야 한다.
- system이 update 함수를 호출되면, 해당하는 component를 지닌 entity들에 대해 iteration을 돌면서 진행되어야 한다.
- render system은 renerable component를 가진 개체들에 적용된다.
- 대부분의 자원은 unique_ptr로 구현했다. (일부 shared_ptr 사용된 부분 변경)
- coordinator는 global에서 app class에서 local 변수로 관리하도록 변경했다.
- 원본 글에서 coordinator는 필요한 자원들을 모두 가지고 서로 소통하도록 해주는 역할을 하는데, 굳이 global 할 필요는 없어보인다.
- https://www.david-colson.com/2020/02/09/making-a-simple-ecs.html 이 글에서는 scene으로 이를 구현했는데, system에 이 scene을 전달해줌으로써 소통하는 구조를 하고 있고, 나도 이 구조를 채택했다.
- 카메라 개체를 rendering system과 분리해서 따로 coordinator에 entity로 저장을 해주는 점을 변경했다.
- shader 관련 compile과 loader 추가.
OpenGL Recap
vao(Vertex Array Object)는 draw command에 사용될 pointer와 같은 역할이다. 따라서 하나의 vao로 여러 vbo를 사용할 수도 있다.
vbo(Vertex Buffer Object)는 실제 데이터라고 볼 수 있다.
openGL에 익숙하지 않다면 OpenGL 튜토리얼 참고 해서 기본적인 것들을 실행해보면 도움이 된다.
http://www.opengl-tutorial.org/beginners-tutorials/tutorial-2-the-first-triangle/
step-1 branch 까지의 내용을 마치면 다음과 같이 정적인 화면의 rendering이 가능하게 된다.
화면을 띄우는데에는 성공했지만 몇가지 오류가 있다. (시점 변환 및 shader)
step-2
사실 위 부분까지 완성되면 다음 step으로 넘어가려 했는데 작성한 코드에 오류가 있어서 이를 수정하는 내용을 step-2로 잡았다. 수정 내용.
projection matrix에 대한 내용을 수정하려고 하는데, 개념은 다음 사이트를 참고해서 도움을 받았다. http://www.songho.ca/opengl/gl_projectionmatrix.html.
OpenGL의 canonical View Volumn은 -1, -1, -1 ~ 1, 1, 1인 정육면체 인데, Normalized Device Coordinate는 left-handed이다. (이 설정들은 api마다 다르다.)
이를 염두해 두고 perspective matrix와 orthographic projection 을 구한 후, 두개를 곱해서 perspective projection matrix를 구해서 뭐가 잘못됐는지 확인 후 수정을 하려 한다.
이 개념은 view frustum을 직육면체로(원근법 반영) 변환을 하고, 그 후 그 직육면체를 canonical view volumn으로 orthographic 한 변환을 수행하는 것이다.
perspective projection에서 x와 y 변환은 z값에 따라 linear한 변환으로 줄 수 있지만, z 값은 그럴수가 없다. 가까운 평면과 먼 평면 n,f에서만 같은 z값을 가지도록 제한을 두어 값을 계산한다. 과정을 나열해보면 다음과 같다.
- xyz -> x’y’z’
- -n < 0으로 상이 맺힐때의 x’ y’을 계산
- x’ = x/(-z) * n 인데 -z 대신 homogeneous factor w를 사용.
- x’ = nx / w
- y’ = ny / w
- w’ = -z 로 잡으면 4x4 변환으로 표현 가능해진다.
- (xyz1) -> x’y’z’(-z)
- z가 변환될 값은 x나 y와는 무관하도록 잡으면 m1, m2 두 변수로 표현 가능하다.
- m1 * z + m2 = z’ / -z. 이때 z’ = z가 되려면 2차방정식이 나온다. 이 값을 -n과 -f에서만 가능하도록 구하면 다음과 같다
따라서 이 변환에서 z remapping이 들어간다고 볼 수 있다. 하지만 원근을 표현함에는 문제가 크게 없다.
\[\begin{align*} perspective \; matrix\\ \left[ \begin{matrix} n & 0 & 0 & 0 \\ 0 & n & 0 & 0 \\ 0 & 0 & (f+n) & fn \\ 0 & 0 & -1 & 0 \\ \end{matrix} \right] \end{align*}\]그 후 직육면체의 크기와 위치만 옮기는 변환은 다음과 같다.
\[\begin{align*} orthographic \; projection\\ \left[ \begin{matrix} \frac{2}{r-l} & 0 & 0 & \frac{-(r+l)}{r-l} \\ 0 & \frac{2}{t-b} & 0 & \frac{-(t+b)}{t-b} \\ 0 & 0 & \frac{-2}{f-n} & \frac{-(f+n)}{f-n} \\ 0 & 0 & 0 & 1 \\ \end{matrix} \right] = \left[ \begin{matrix} \frac{1}{r} & 0 & 0 & 0 \\ 0 & \frac{1}{t} & 0 & 0 \\ 0 & 0 & \frac{-2}{f-n} & \frac{-(f+n)}{f-n} \\ 0 & 0 & 0 & 1 \\ \end{matrix} \right] \\ r+l = 0 , t+b=0 으로 가정. (r>0, t>0) \\ 2r = w, 2t = h, tan(\theta/2) = t/n \end{align*}\]위 두개를 곱하면 최종 perspective projection matrix를 얻는다. (perspective mat이 먼저 적용되도록)
\[\begin{align*} perspective \; projecton\\ \left[ \begin{matrix} \frac{1}{(\frac{w}{h})*tan(\frac{\theta}{2})} & 0 & 0 & 0 \\ 0 & \frac{1}{tan(\frac{\theta}{2})} & 0 & 0 \\ 0 & 0 & -\frac{f+n}{f-n} & -\frac{2fn}{f-n} \\ 0 & 0 & -1 & 0 \\ \end{matrix} \right] \end{align*}\]이 matrix의 sign에 유의해서 코드를 작성하면 다음 부분을 수정할 수 있다.
step-3
- gravity와 rigid body component 추가
- physics system 추가.
- 간단하게 떨어지는 모션을 추가해준다.
- shader의 normal vector에 문제가 있던 것을 수정해준다.
physics system
좌표, 속도, 가속도 업데이트를 통해 물체가 떨어지는 것을 표현한다. 이외에 회전에 대한 component와 system을 추가해줄 수도 있다.
 |
 |
normal vector
rotation, scaling에 따라서 normal vector도 transformation을 해줘야하는데, shader로 전달해줄때는 이 transform을 위한 matrix도 추가로 전달을 해줘야하는데 이 부분이 누락되었었다.
v의 normal을 v라고 하면, Mv에 대한 normal은 다음과 같다.
\[\begin{align} n^T v = 0 \\ n^T M^{-1} Mv = 0 \\ (M^{-T}n)Mv = 0 \\ M^{-T} = RS^{-1} \end{align}\]M = TRS 에서 translation을 제외하고 계산하면 마지막 식을 얻는다. 이 계산을 모든 normal에 대해서 해줄것이 아니므로, fragment shader로 넘겨주어 lighting 계산에 사용하도록 수정해준다.
 |
 |
step-4
- demo 실행
- 간단한 oop 버전 추가 후 비교
- valgrind로 cache 사용 시뮬레이션
verification
valgrind라는 툴로 cache 사용을 simulation 해볼 수 있다. 이전에 memory leak 검사에 사용해본적이 있던 툴인데, cache 사용에 대한 것도 분석이 가능한 툴이었다. https://valgrind.org/docs/manual/cg-manual.html
| ECS | OOP |
|---|---|
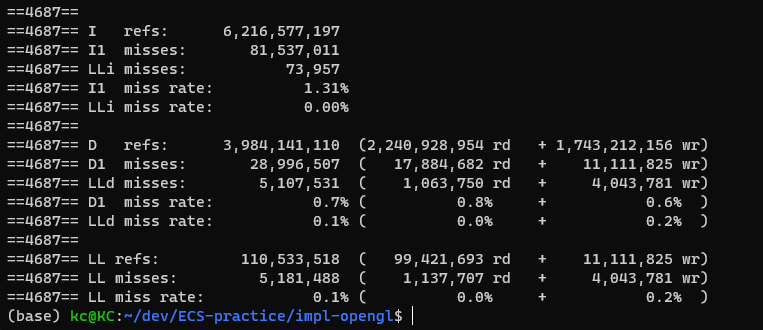 |
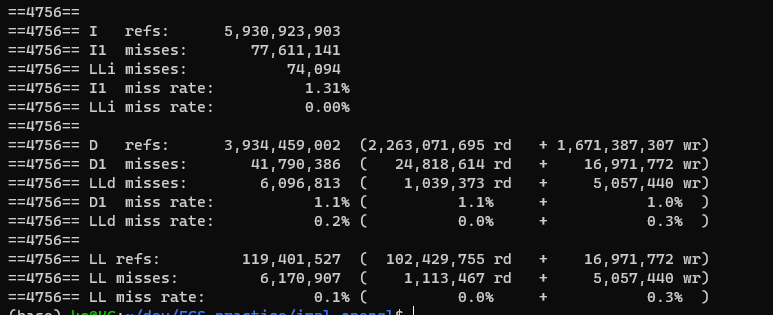 |
cachegrind 출력을 보면 위에서 정리한 cache 개념에 해당하는 내용들을 볼 수 있다. L1 캐시는 instruction 과 data 두개로 나누어 I1, D1으로 출력됐다. LL은 last level 캐시로, valgrind cachegrind에서는 L1과 LL 두가지로만 시뮬레이션 해준다고 한다. 우측편에는 read와 write로 나누어 전체 reference와 miss 수, 비율을 보여준다.
분석 결론으로 D1 miss rate가 cache friendly code인지 확인을 해볼 수 있는 수치라고 한다. 실제로 ECS 코드가 더 작은 D1 cache miss rate을 보였다. 어느정도 차이가 보이긴 했으나 이 수치는 최대 개체 수, component 수 등에 따라서 달라지기도 하고 큰 차이가 나오지 않기도 했다. 이와 별도로 한 frame 계산에 걸리는 평균 시간을 계산해보기도 했는데 오히려 OOP 버전이 짧게 걸리기도 했다. (더 높은 FPS가 oop에서 나옴) ECS 코드의 over head로 인한 것으로 추측되기는 하는데 이번 간단한 실습 프로젝트에서 data cache 개념과 ECS의 원리를 확인해보기 위한 실험으로는 충분한 것 으로 판단되어 이정도에서 진행을 멈췄다.
실제 프로젝트에서는 CPU 레벨의 optimization까지 고려해가며 코드를 작성하기란 쉽지 않을 것 같다. 그리고 game time과 목표 FPS 달성을 위한 최적화 과정에서는 위처럼 단순화 한 것들 보다 훨신 더 복잡한 상황이 적용될 것이므로 직접 실험해보고 이미 검증된 상용화 툴들을 사용할때 도움이 될 것이라 생각한다.